
Executive Summary
The global AI image generation market reached $8.7 billion in 2024 and is projected to grow to $60.8 billion by 2030, expanding at 38.2% annually[1]. Marketing teams generate personalized product imagery at scale. Design studios prototype concepts without traditional production pipelines. Healthcare organizations create synthetic training data for diagnostic systems. Yet most organizations lack reliable methods to determine how much infrastructure these workloads actually require. Metrum AI’s Image Generation Demo eliminates this uncertainty by benchmarking Stable Diffusion v1-5 image generation workloads directly on Dell PowerEdge R770 servers equipped with Intel Xeon 6 processors (6780P), enforcing a strict 120-second latency threshold to ensure results reflect production requirements.
Benchmark results demonstrate a clear performance progression across three acceleration paths. CPU baseline mode achieves 1.47 images per minute at production quality. Enabling Intel Advanced Matrix Extensions (AMX) increases throughput to 3.6 images per minute with 2.4x throughput gains, without any GPU investment. Adding NVIDIA RTX Pro 6000 Ada Generation GPU acceleration extends capacity to 32 concurrent requests at 42.13 images per minute, delivering 28.7x performance gains over baseline. The 14th Generation Dell PowerEdge R740 achieves only 0.21 images per minute on its CPU baseline, a 7x throughput gap that quantifies the operational cost of running generative AI workloads on legacy infrastructure. These results give IT directors and infrastructure architects the validated data they need to right-size deployments, avoid overprovisioning, and build a defensible infrastructure roadmap for generative AI image workloads at scale.
Challenges
Organizations across industries are adopting generative AI to transform how they create visual content. Marketing teams produce personalized product imagery in hours rather than weeks. Design studios iterate on concepts without traditional production pipelines. Healthcare organizations generate synthetic training data to improve diagnostic accuracy. Entertainment companies create visual assets that previously required extensive manual effort. Each use case shares a common requirement: infrastructure capable of generating high-fidelity images within acceptable latency thresholds while supporting multiple concurrent users.
When a marketing platform exceeds acceptable generation latency, creative teams lose momentum and campaign velocity drops. When a design tool operates above threshold, production delays compound across projects. The business value of generative AI image creation depends entirely on systems that perform reliably under production load.
The Infrastructure Challenge
For IT leaders, this growth introduces a practical challenge: determining how much infrastructure is required to support image generation workloads without overspending on unused capacity. Vendor datasheets provide theoretical peak numbers that rarely match sustained production performance. Small-scale pilots test a handful of requests but fail to reveal how systems behave at 8, 16, or 32 concurrent generation tasks. The gap between these limited inputs and actual deployment requirements creates risk on both sides of the equation.
Organizations that overprovision waste capital on accelerators they do not fully utilize. Organizations that underprovision face extended generation times, frustrated users, and costly emergency upgrades. Either outcome undermines the return on investment that justified the generative AI initiative in the first place.
A Solution to Capacity Planning
To address this challenge, Metrum AI developed the Image Generation Demo. This solution provides a complete benchmarking environment that runs directly on Dell PowerEdge R770 servers, enabling IT teams to measure throughput, latency, and concurrency limits before committing to deployment decisions.
The demo benchmarks hardware configurations using Stable Diffusion v1-5, a production-grade text-to-image model representative of the model class organizations deploy for product imagery, concept design, and synthetic data generation. It evaluates three distinct acceleration paths: CPU baseline, Intel AMX optimization, and NVIDIA GPU acceleration, while enforcing a strict 120-second latency threshold per request. This threshold ensures results reflect production conditions, not theoretical peaks.
The demo runs on PowerEdge R770 servers configured with Intel Xeon 6 processors (6780P) with AMX support, DDR5 memory, and PCIe Gen5 expansion for GPU acceleration. This configuration gives organizations a production-grade evaluation environment for image generation workloads, alongside the software workflows used during evaluation.
Solution Overview
Vendor specifications and limited pilots rarely reflect production conditions. Organizations need validated performance data from real hardware running actual workloads. The Image Generation Demo addresses this requirement by embedding a complete benchmarking environment directly onto Dell PowerEdge R770 servers. IT teams measure throughput, latency, and concurrency limits using the same infrastructure they would deploy in production.
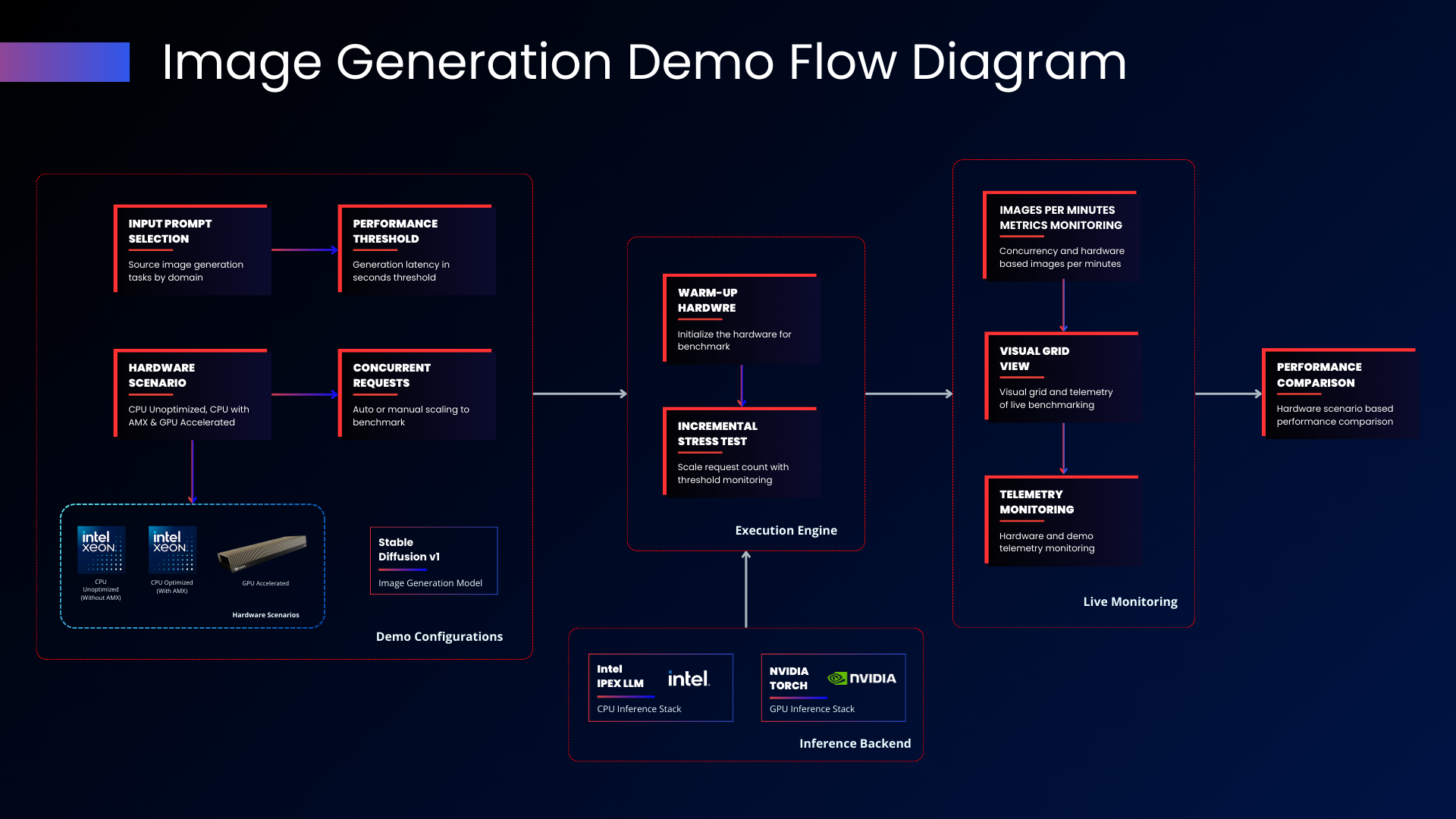
Figure 1- Solution Flow
The demo follows a workflow from configuration through performance comparison. In the configuration stage, operators select standardized image prompts by domain, define the latency threshold, choose which hardware scenarios to evaluate, and specify whether concurrency scaling should be automatic or manual. These parameters establish the test conditions that reflect the organization's specific deployment requirements.
The execution engine then takes over, beginning with a warm-up phase that loads model weights into memory and VRAM while stabilizing thermal conditions. An incremental stress test follows, progressively increasing concurrent image generation requests while monitoring performance against the defined latency threshold. The model executes 25 denoising steps per image using the PNDMScheduler at 1280x720 output resolution. The system records images-per-minute throughput alongside inference latency to capture both aggregate capacity and per-request behavior.
Running on PowerEdge R770 infrastructure, this workflow reflects real deployment conditions by exercising CPU cores for diffusion steps, memory bandwidth for model weight access, and accelerator resources for tensor operations simultaneously. The incremental scaling approach mirrors how production environments grow over time, allowing IT teams to observe system behavior as request density increases.
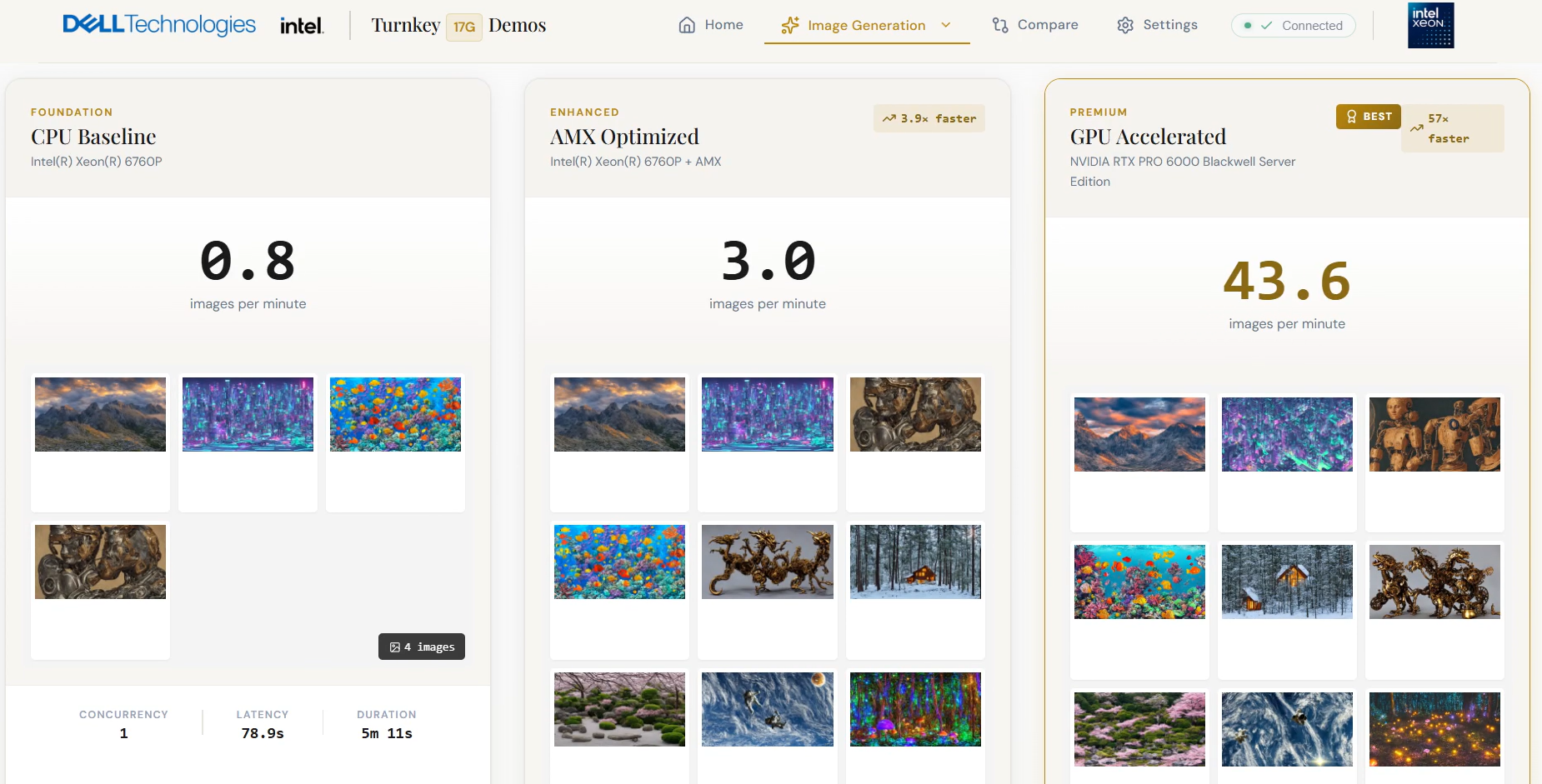
Figure 2 - Unified Command Interface
Throughout execution, the live monitoring interface provides real-time visibility into system behavior. Operators observe images-per-minute metrics, a visual grid of generated images, and hardware telemetry including CPU and GPU utilization. Upon completion, the performance comparison view presents results from all tested scenarios side by side, translating raw metrics into actionable infrastructure decisions.
Solution Architecture
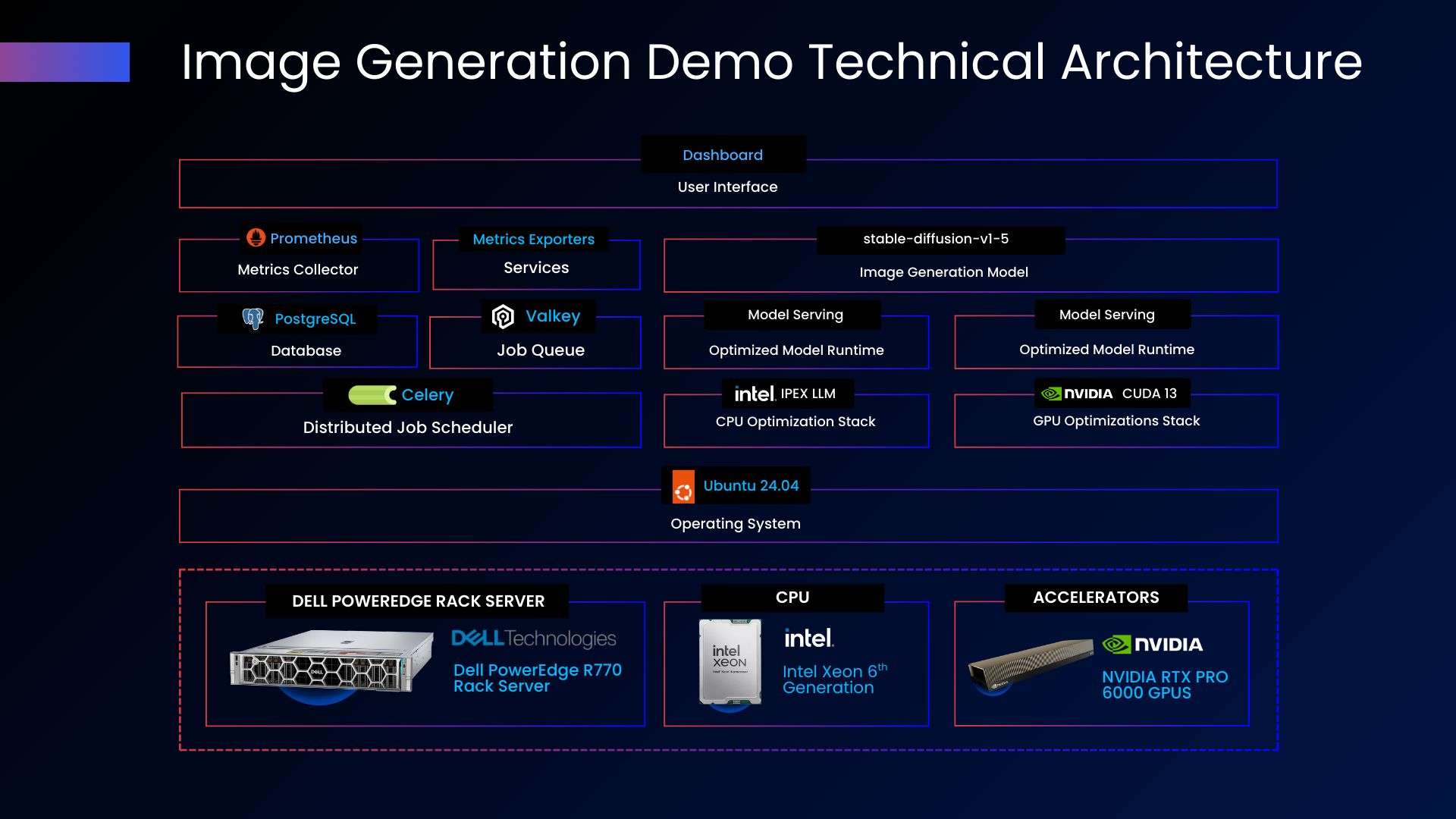
Figure 3 - Solution Architecture
The application layer provides the user-facing interface and coordination logic. A web-based dashboard delivers configuration controls, live benchmark visualization, and results comparison. PostgreSQL maintains benchmark history and configuration state, enabling trend analysis across multiple test runs.
The processing layer manages workload distribution across available compute resources. Celery handles distributed job scheduling, coordinating inference tasks across CPU and GPU backends. Valkey provides the job queue that buffers and routes work to available processors. This architecture supports horizontal scaling by adding worker nodes without modifying application logic.
The inference layer executes image generation using Stable Diffusion v1-5 with optimized runtimes for each hardware scenario. Intel IPEX LLM powers CPU-based inference with optional AMX acceleration using BF16 precision. NVIDIA Torch with CUDA 13 drives GPU-accelerated inference with FP16 precision. The system routes workloads to the appropriate backend based on the selected hardware scenario, optimizing attention mechanisms and memory management for diffusion workloads.
On the R770, Intel AMX supports BF16 tensor execution on CPU cores, improving matrix multiplication performance for diffusion model inference. PCIe Gen5 connectivity provides the bandwidth required to support GPU-accelerated inference workflows.
The observability layer captures system telemetry throughout benchmark execution. Prometheus collects metrics from all components. Custom exporters surface hardware utilization data including CPU load, memory bandwidth, and GPU statistics. This instrumentation enables operators to correlate performance results with underlying resource consumption.
Ubuntu 24.04 LTS provides the operating system foundation, delivering a stable and secure environment for production workloads.
Infrastructure Foundation
Image generation workloads place sustained demands on server infrastructure, requiring high memory bandwidth for model weight access, substantial memory capacity for intermediate tensors during diffusion steps, and parallel compute capacity for the iterative denoising process. Dell PowerEdge R770 addresses these requirements through its 17th Generation architecture, aligned with AI inference and data-intensive application requirements.
Equipped with dual Intel Xeon 6780P processors delivering 128 total cores, the R770 distributes prompt encoding, diffusion steps, and image decoding without resource contention. One terabyte of DDR5 memory keeps model weights and intermediate latent representations resident in memory, eliminating swap-induced latency during sustained operation. High-capacity NVMe storage supports generated image output and logging, preventing I/O bottlenecks as request volumes scale. Together, these capabilities support sustained operation under production workloads, rather than short-lived peak measurements.
For organizations requiring maximum throughput density, two NVIDIA RTX Pro 6000 Ada Generation GPUs deliver dedicated inference acceleration. This configuration separates CPU resources for orchestration and request handling from GPU resources dedicated to diffusion model execution. The design enables scalable performance as request volumes increase. This balanced CPU-GPU architecture allows organizations to scale from CPU-only deployments to GPU-accelerated environments on the same R770 platform, supporting consistent operations as performance requirements evolve.
| Component | Dell PowerEdge R770 | Dell PowerEdge R740 |
|---|---|---|
| Generation | 17th Generation | 14th Generation |
| CPU | Intel(R) Xeon(R) 6780P (128 Cores, 2 Sockets) | Intel(R) Xeon(R) Gold 6126 CPU (12 Cores, 2 sockets) |
| Memory | 1 TB DDR5 | 96 GB |
| Storage | 9.2 TB NVMe SSD | 500 GB |
| GPU | 2x NVIDIA RTX Pro 6000 Ada Generation | None |
Table 1 - Hardware Configuration
The benchmark includes a Dell PowerEdge R740 to illustrate the generational performance gap. This 14th Generation system lacks AMX support and GPU acceleration, limiting its capacity to CPU baseline scenarios. The comparison quantifies the operational constraints organizations face when running image generation workloads on legacy infrastructure.
Performance Benchmark
The benchmark measures system behavior against three key metrics that translate hardware capabilities into operational capacity:
- Images Per Minute (IPM) captures total throughput of fully rendered images produced by the model, indicating aggregate processing power available for creative workloads.
- Inference Latency reflects the time from prompt submission to final pixel rendering, ensuring generation times remain within acceptable bounds for each individual request.
- Max Concurrency identifies the parallelism ceiling before quality degradation occurs, establishing the practical limit for multi-user deployment planning.
The demo enforces a strict 120-second latency threshold throughout testing. Production deployments demand consistent generation times to support real-time creative workflows. A marketing platform exceeding acceptable latency frustrates creative teams and reduces campaign velocity. A design tool operating above threshold introduces production delays that compound across projects. The benchmark progressively increases concurrent requests until any request exceeds this quality floor, establishing true operational capacity.
| Scenario | Max Concurrency (@120s latency threshold) | Peak Images per Minute | Speedup vs. Baseline |
|---|---|---|---|
| CPU Baseline | 2 | 1.47 | 1.0x |
| AMX Optimized | 8 | 3.6 | 2.6x |
| GPU Accelerated | 32 | 42.13 | 28.7x |
Table 2 - Dell PowerEdge R770 Benchmark
These results reflect the combined impact of the R770 platform capabilities: high core density for concurrent request processing, DDR5 memory bandwidth for sustained model weight access, and optimized AMX execution for CPU-based inference. When paired with GPU acceleration, PCIe Gen5 connectivity supports efficient data movement between host and accelerators, enabling increased request density as workloads scale.
| Scenario | Max Concurrency (@120s latency threshold) | Peak Images per Minute | Speedup vs. Baseline |
|---|---|---|---|
| CPU Baseline | 1 | 0.21 | 1x |
| AMX Optimized | Not Supported | Not Supported | Not Supported |
| GPU Accelerated | Not Supported | Not Supported | Not Supported |
Table 3 - Dell PowerEdge R740 Benchmark
The results highlight three practical considerations for infrastructure planning:
AMX optimization delivers 4x concurrency capacity and 2.6x throughput gains without GPU investment. For organizations running moderate image generation workloads with up to 8 concurrent users, AMX-optimized CPU inference provides a cost-effective path that avoids GPU procurement, power, and cooling overhead. A single AMX-optimized R770 handles workloads that would require nearly three baseline servers.
GPU acceleration extends capacity to 32 concurrent requests with 28.7x throughput gains. For high-density environments such as large marketing operations, multi-brand content studios, or enterprise design platforms, GPU acceleration on the R770 consolidates workloads onto fewer servers, reducing rack space, power draw, and management complexity.
The generational gap is substantial. The R770 delivers 7x the baseline throughput of the legacy R740 platform (1.47 vs. 0.21 images per minute). Organizations still running 14th Generation infrastructure face significant constraints that limit their ability to support generative AI image workloads at scale.
Business Impact
Benchmark numbers quantify infrastructure capability. The real value lies in how those capabilities translate into business outcomes for the organizations deploying them.
Server Consolidation and CapEx Efficiency
An AMX-optimized R770 handles the workload of nearly three baseline CPU servers. For a deployment targeting 8 concurrent image generation users, organizations can consolidate from multiple servers to a single R770 with AMX enabled. This consolidation reduces server procurement costs, data center rack space, power consumption, and ongoing management overhead.
GPU-accelerated configurations extend this consolidation further. A single R770 with two NVIDIA RTX Pro 6000 Ada Generation GPUs processes 32 concurrent requests at 42.13 images per minute, workloads that would require over 28 baseline CPU servers. For large-scale creative operations, this consolidation ratio translates directly into lower total cost of ownership.
Risk Reduction Through Validated Capacity Planning
The most expensive infrastructure mistake is deploying hardware that cannot sustain production workloads. Emergency capacity additions, unplanned downtime, and frustrated creative teams carry costs that far exceed the price of proper planning. By validating capacity limits before deployment, organizations reduce the risk of production-day failures and the emergency procurement cycles they trigger.
Flexible Upgrade Path
The R770 platform supports a modular approach to scaling. Organizations can deploy with CPU-only configurations for initial rollouts, enable AMX optimization through software configuration for mid-scale growth, and add GPU accelerators for high-density requirements. This flexibility protects the initial investment and extends the useful life of the platform as workload demands evolve.
Conclusion
Image generation initiatives succeed or fail based on infrastructure readiness. Organizations must produce high-quality images within predictable timeframes while maintaining acceptable latency to avoid frustrated users, stalled creative workflows, and downstream business risk. Traditional capacity planning methods, including vendor specifications and small-scale pilots, often fail to reflect sustained production conditions. IT leaders face a common dilemma: overprovision to mitigate risk, or underprovision and compromise performance. What enterprises need is validated, workload-driven insight that connects infrastructure choices directly to operational outcomes.
The Image Generation Demo provides that validated insight. Rather than measuring isolated peak performance, the solution evaluates real hardware under incremental load using Stable Diffusion v1-5 and a strict 120-second latency threshold. The unified interface guides teams from configuration through execution and side-by-side comparison. The layered architecture ensures clear attribution across orchestration, inference, and observability. By supporting CPU baseline, Intel AMX optimization, and GPU-accelerated scenarios within the same workflow, the demo enables infrastructure architects to compare acceleration paths using consistent test conditions.
Measured results on the Dell PowerEdge R770 demonstrate how the 17th Generation platform translates directly into operational capacity. CPU baseline inference achieves 1.47 images per minute. Intel AMX increases throughput to 3.6 images per minute with a 2.6x gain, providing a cost-effective option for mid-scale deployments without GPU investment. GPU acceleration extends capacity to 42.13 images per minute with 32 concurrent requests, delivering 28.7x gains for environments that require maximum density. The generational comparison quantifies the limitations of legacy systems, highlighting a 7x baseline throughput gap between 14th and 17th Generation platforms.
Together, these outcomes give IT directors and infrastructure architects the defensible data they need to right-size deployments, avoid unnecessary overprovisioning, and build a scalable infrastructure roadmap for generative AI image workloads at scale.
Addendum
Operating System Information
| Type | Details |
|---|---|
| Operating System | Ubuntu 24.04.3 LTS |
| Kernel | 6.8.0-90-generic |
| Driver Status | NVIDIA CUDA 13 |
Experiment Configuration
| Configuration | Details |
|---|---|
| Generative Model | Stable Diffusion v1-5 |
| Model Precision | BF16 (CPU) and FP16 (GPU) |
| Inference Engine | Intel IPEX LLM (CPU) / NVIDIA Torch (GPU) |
| Input Dataset | Standardized image generation text prompts |
| Latency Threshold | 5.0 Seconds (Target for High-Quality Render) |
| Scaling Mode | Auto |
Hardware Scenarios Tested
| Backend | Inference Engine | Version |
|---|---|---|
| CPU Un-optimized | Intel IPEX LLM with AMX disabled | 2.2.0 |
| CPU Optimized with AMX | Intel IPEX LLM with AMX enabled | 2.2.0 |
| GPU Accelerated | NVIDIA CUDA Torch | torch 2.9.1+cu128 |
References
[1] MarketsandMarkets, "AI Image Generator Market by Technology (Convolutional Neural Networks, Autoregressive Models, Diffusion Models), Application (Image Generation, Image Captioning, Image Manipulation, Video Generation, Video Synthesis, Video Editing) - Global Forecast to 2030," MarketsandMarkets Research Private Ltd., Pune, India, 2024. [Online]. Available: https://www.marketsandmarkets.com/Market-Reports/ai-image-video-generator-market-235119833.html
Copyright © 2026 Metrum AI, Inc. All Rights Reserved. This project was commissioned by Dell Technologies. Dell and other trademarks are trademarks of Dell Inc. or its subsidiaries.
DISCLAIMER - Performance varies by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance.