How 288GB HBM3e Eliminates the VRAM Wall for Next-Generation AI Models

Executive Summary
Moonshot AI's Kimi K2.5 arrived in late January 2026 as a 1-trillion-parameter Mixture of Experts (MoE) model, a design that activates only a subset of specialized sub-networks per request to improve efficiency. It is one of the largest production-grade language models released to date. Infrastructure teams worldwide faced an immediate question: how to deploy this model at enterprise scale without multi-node complexity and weeks of custom engineering.
A single Dell PowerEdge™ XE9785L server equipped with eight AMD Instinct™ MI355X accelerators resolves that constraint. The MI355X delivers 288GB of HBM3e memory per GPU, providing 2.3TB of combined capacity across one 8-GPU node, enough to run the full Kimi K2.5 model without multi-node sharding. AMD ROCm™ 7 delivers day-0 software support with optimized kernels for MoE routing and Multi-head Latent Attention (MLA), a more memory-efficient attention mechanism that supports longer context without sacrificing speed. This enables production deployment within hours of the model's release rather than weeks of custom integration.
Benchmark model: Both platforms ran Kimi K2.5. The MI355X used amd/Kimi-K2.5-MXFP4, an MXFP4 quantization of the base model produced with AMD Quark, served at FP4 precision. The MI300X used the stock moonshotai/Kimi-K2.5 checkpoint served at FP8 precision.
The generational leap from CDNA 3 to CDNA 4 is equally significant. Running Kimi K2.5 on a single 8-GPU MI300X node (Dell PowerEdge XE9680, FP8 precision) produces 708 output tokens per second at 512 concurrent requests before errors begin. The MI355X (Dell PowerEdge XE9785L, FP4 precision) delivers 1,032 tokens per second at the same concurrency with zero errors and continues scaling to 3,035 tokens per second at 2,048 concurrent requests. The MI300X cannot operate reliably at those concurrency levels.
Key Results at a Glance
Sub-2s TTFT (P95) Through 128 concurrent requests |
3,035 output tokens/s Peak throughput at 2,048 conc. requests |
2.3 TB combined GPU memory Single 8-GPU node, no multi-node sharding |
Up to 1.63x system-level throughput MI355X vs. MI300X deployment at error-free concurrency |
0% error rate at 2,048 concurrent requests On generation workload; MI300X fails 65% at this load |
Hours to production, not weeks Via ROCm 7 + Dell Enterprise Hub containers |
The deployment path extends beyond hardware and drivers. The Dell Enterprise Hub on Hugging Face provides validated, deployment-ready Kimi K2.5 containers pre-tested on Dell PowerEdge platforms with AMD Instinct accelerators. Infrastructure teams pull an optimized container, deploy on the XE9785L, and serve production traffic the same day the model releases. No custom sharding, no multi-node orchestration, no weeks of integration work. These workloads match common enterprise use cases such as customer-facing chatbots, document analysis pipelines, and long-form content generation.
The VRAM Challenge
Every major model release forces infrastructure teams through the same evaluation cycle: assess hardware compatibility, estimate distributed deployment requirements, and calculate engineering effort before production can begin. With Kimi K2.5, that cycle exposes a hard constraint: memory capacity.
Kimi K2.5 uses Multi-head Latent Attention (MLA) and requires approximately 230GB of memory per inference instance at FP4 precision. Many current-generation accelerators ship with 192GB or less of high-bandwidth memory, creating a hard ceiling for single-GPU model hosting. This memory footprint exceeds single-GPU limits and triggers a cascade of complexity. The model must be sharded across multiple nodes, and that distributed approach introduces three costs that compound over time.
Latency penalties from inter-node communication. Every inference request must coordinate across network boundaries, adding milliseconds that users perceive as sluggish response times.
Infrastructure complexity from distributed orchestration. Operations teams must configure, monitor, and troubleshoot a more intricate system with additional failure modes.
Extended time to production. Engineering teams implement custom sharding strategies for each new model release, creating a recurring productivity tax that accumulates throughout the year.
The 288GB HBM3e capacity of the MI355X eliminates this constraint at the hardware level. A single 8-GPU node provides 2.3TB of combined memory, keeping the full Kimi K2.5 model on-node and removing multi-node sharding from the deployment equation entirely.
| Dimension | Path A: 192GB Accelerator (Multi-Node) | Path B: MI355X 288GB (Single Node) |
|---|---|---|
| Nodes required | 2+ nodes (16+ GPUs) | 1 node (8 GPUs) |
| Network fabric | High-speed inter-node interconnect required (InfiniBand / RoCE) | On-node interconnect only |
| Deployment engineering | Custom sharding strategy, distributed orchestration, inter-node tuning | Pull validated container, deploy |
| Time to production | Days to weeks per model release | Hours |
| Failure domain | Multi-node (network partitions, distributed fault handling) | Single node |
| Power envelope (Illustrative) | ~11kW+ (2 nodes, GPU power) | ~5.0 to 5.4kW (1 node, GPU power) |
| Rack footprint | 2+ rack units, additional switching | 1 rack unit |
| Ancillary infrastructure | Network switches, cabling, distributed monitoring | Standard enterprise management |
Table 1 - Two Paths to Production: A Deployment Comparison. Power envelope values are illustrative estimates based on GPU-level measurements during Kimi K2.5 inference; actual power consumption varies by workload, configuration, and facility conditions.
In practice, this means what used to require a small cluster now fits in one server. Deployment time drops from 2 to 4 weeks to a few hours, and engineering effort shifts from distributed systems work to application optimization.
AMD CDNA 4: Built for Next-Generation Inference
The MI355X represents the fourth generation of AMD's CDNA architecture, engineered specifically for large-scale AI inference workloads. Three capabilities define its value for production deployment: 288GB HBM3e memory per accelerator, 8TB/s memory bandwidth, and hardware-accelerated inference through the AI Tensor Engine (AITER).
Memory: The 50% Advantage
Moving from 192GB to 288GB HBM3e per accelerator is not an incremental improvement. This 50% capacity increase enables single-node deployment of models that previously required distributed infrastructure.
For Kimi K2.5, an 8-GPU MI355X node provides 2.3TB of combined GPU memory. This capacity supports multiple concurrent inference instances with headroom for dynamic batching and KV cache optimization, a technique that stores previously computed attention data to avoid redundant calculations. This results in infrastructure consolidation that simplifies operations while improving performance.
A workload requiring 16 GPUs with 192GB memory now runs on 8 GPUs with 288GB memory. This consolidation reduces power consumption, shrinks data center footprint, and cuts operational overhead. Consolidation also improves inference latency by eliminating cross-node communication entirely.
Bandwidth: Moving Data at Scale
Memory capacity determines what fits. Memory bandwidth determines how fast it runs. The MI355X delivers 8TB/s of HBM3e bandwidth per accelerator, enabling rapid model weight access during inference.
For MoE models like Kimi K2.5, where expert routing requires frequent weight loading, bandwidth directly impacts tokens per second. The advantage compounds under production load. When serving multiple users simultaneously, the MI355X maintains consistent throughput by efficiently streaming weights from HBM3e to compute units. Infrastructure teams can support higher concurrent user loads without degradation in response time.
Dell PowerEdge XE9785L: Enterprise AI Infrastructure
The Dell PowerEdge XE9785L rack server provides the enterprise foundation for MI355X-accelerated inference. The XE9785L addresses the thermal, power, and density requirements of GPU-intensive AI workloads while supporting up to eight MI355X accelerators in a standard rack form factor.
Dell's integrated management stack, including iDRAC and OpenManage, gives operations teams the same monitoring, firmware lifecycle, and remote management capabilities they rely on across their Dell server fleet. This consistency reduces the operational learning curve for teams adopting GPU-accelerated infrastructure.
The XE9785L's direct-liquid cooling option addresses the thermal demands of eight MI355X accelerators running sustained inference workloads. By maintaining optimal GPU temperatures under load, the platform supports sustained inference within the ~5.0 to 5.4kW GPU power envelope observed during Kimi K2.5 benchmarking.
ROCm 7: Production-Ready Software from Day Zero
Hardware capacity means little if software support lags behind model releases. ROCm 7, released in September 2025, provides day-0 support for Kimi K2.5 with optimized kernels for MoE routing and MLA attention mechanisms. Organizations can deploy the model in production immediately after release, without waiting for software updates or implementing custom kernels.
AI Tensor Engine (AITER) Optimizations
The AITER hardware block in MI355X accelerates the mathematical operations underlying transformer inference. ROCm 7 leverages this capability for two critical operations in Kimi K2.5: MoE expert routing and MLA attention computation.
For MoE models, expert routing overhead can represent a meaningful fraction of total inference time, depending on model architecture and batch size. ROCm 7's AITER-optimized kernels reduce this overhead through hardware-accelerated routing decisions. The MI355X processes expert selection and weight loading in parallel with attention computation, improving overall throughput without application-level changes.
Multi-head Latent Attention, a key innovation in Kimi K2.5, compresses key-value cache size through learned projections. ROCm 7 includes specialized kernels that exploit AITER's matrix multiplication units for efficient latent projection computation. This optimization maintains inference speed while reducing memory footprint for longer context windows.
Production Performance: Kimi K2.5 on MI355X
Benchmark results confirm that a single 8-GPU MI355X node handles Kimi K2.5 at enterprise scale. All MI355X tests ran on a Dell PowerEdge XE9785L with eight AMD Instinct MI355X accelerators, using ROCm 7 and vLLM 0.15.0. The model was amd/Kimi-K2.5-MXFP4, served at FP4 precision on a Dell PowerEdge XE9785L with eight AMD Instinct MI355X accelerators using ROCm 7 and vLLM 0.15.0.
This configuration reflects a single-node production deployment without multi-node sharding or distributed orchestration. AMD's published Quark quantization data for this model class shows minimal accuracy degradation from MXFP4 precision relative to the base checkpoint; a detailed accuracy analysis across task types is outside the scope of this deployment-focused brief. Organizations should validate task-level accuracy (e.g., factual QA or reasoning benchmarks) on their own datasets before production deployment.
Throughput at Production Scale
The system scales predictably from single-user inference to enterprise-grade concurrency. Three workload profiles capture the range of production scenarios: short-context classification, long-form content generation, and full long-context dialogue.
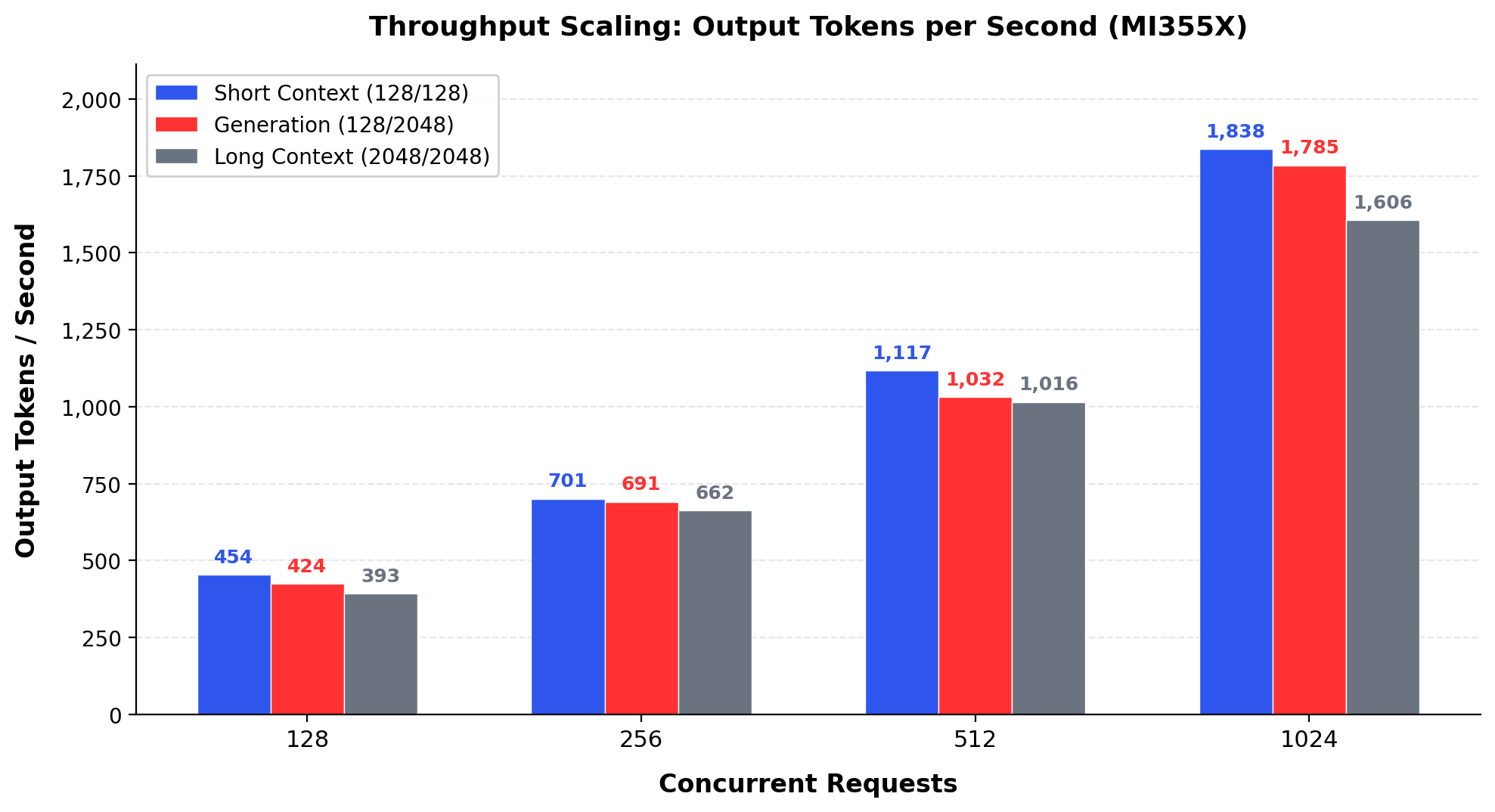
Figure 1 - Kimi K2.5 Output Throughput on a Single 8-GPU MI355X Node
Short Context = 128 input tokens, 128 max output tokens. Generation = 128 input, 2048 max output. Long Context = 2048 input, 2048 max output. All results reflect zero-error runs.
1,000+ tokens/s at 512 concurrent requests with zero errors on a single node. At 512 concurrent requests, a concurrency level typical for departmental deployments, the system delivers over 1,000 output tokens per second across all three workload profiles. Under typical enterprise query patterns (short prompts, moderate output lengths), this throughput can support on the order of 100 or more concurrent interactive sessions, though actual capacity depends on workload mix and latency requirements.
Scaling to 1,024 concurrent requests increases generation throughput to 1,785 tokens per second while maintaining zero errors. At 2,048 concurrent requests, the generation workload reaches 3,035 output tokens per second. This represents the peak throughput for long-form output with complete reliability on a single node.
Power Efficiency
The MI355X maintains consistent power consumption across concurrency levels while scaling throughput linearly. System power measurements during Kimi K2.5 inference demonstrate the efficiency characteristics of the CDNA 4 architecture under production load.
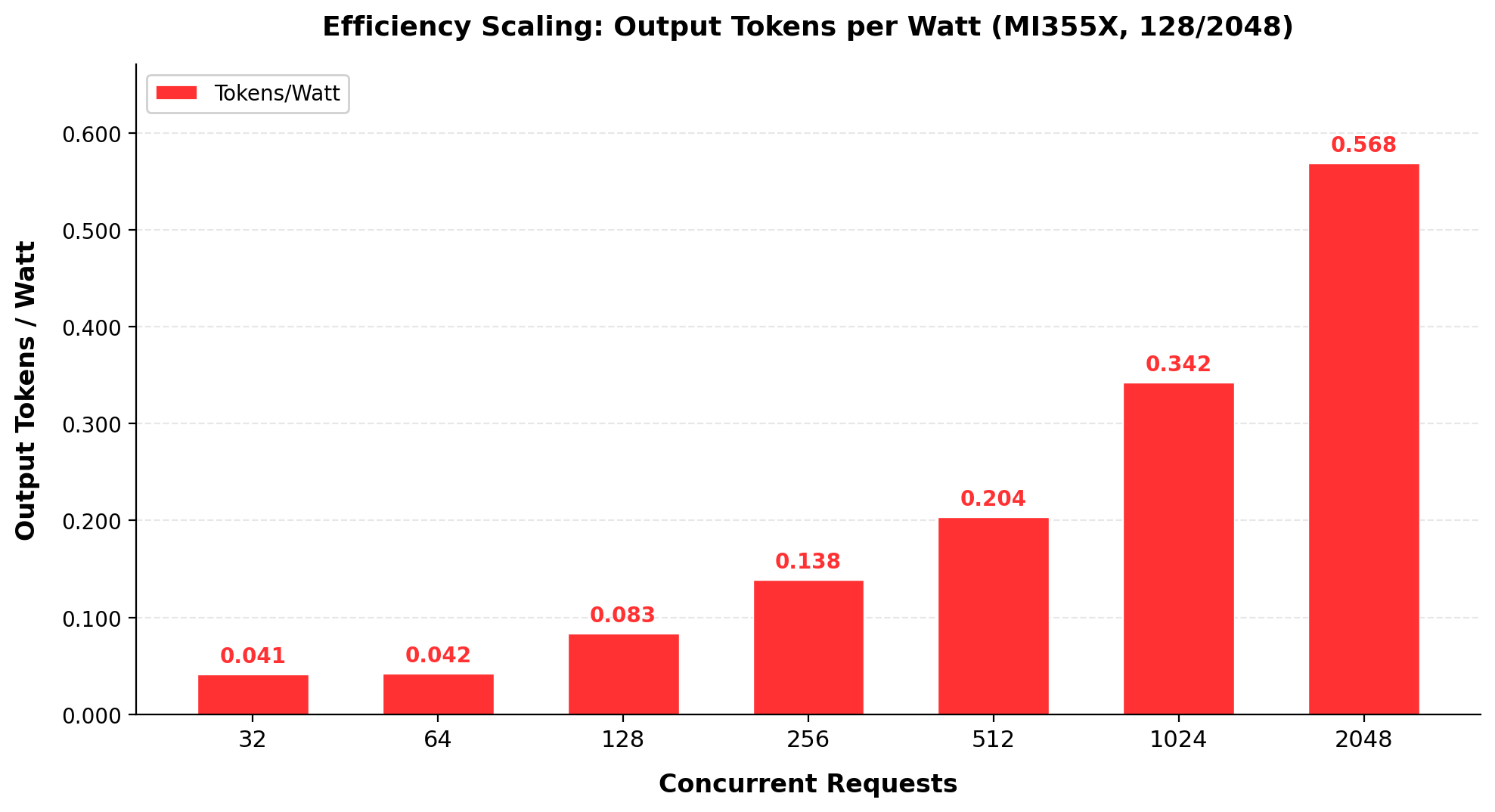
Figure 2 - Power Efficiency at Production Concurrency (128 input / 2048 max output)
GPU power scales modestly while throughput scales dramatically. Total GPU power (P90, sum of eight accelerators) ranges from approximately 4,957W at 128 concurrent requests to 5,356W at 2,048 concurrent requests on the generation workload (128 input / 2048 output). That is an 8% increase in GPU power supporting a 7.4x increase in throughput. At 1,024 concurrent requests, the system delivers 0.34 output tokens per GPU-watt, a 32x improvement over single-request inference (0.011 tokens per GPU-watt), reflecting the batching efficiency gains available at production concurrency levels.
For data center operators, this characteristic simplifies capacity planning. GPU power varies less than 10% between moderate and peak concurrency, so power provisioning can be sized for steady-state operation without accounting for significant load-dependent spikes. The 8-GPU MI355X node sustains production throughput within a predictable ~5.0 to 5.4kW GPU power envelope.
Time to First Token: Preserving Interactive Experience
Time to first token (TTFT), the delay before a user sees the first word of a response, determines whether an application feels responsive. For interactive deployments, TTFT below one second preserves conversational flow. Latency above two seconds introduces noticeable hesitation that degrades user satisfaction.
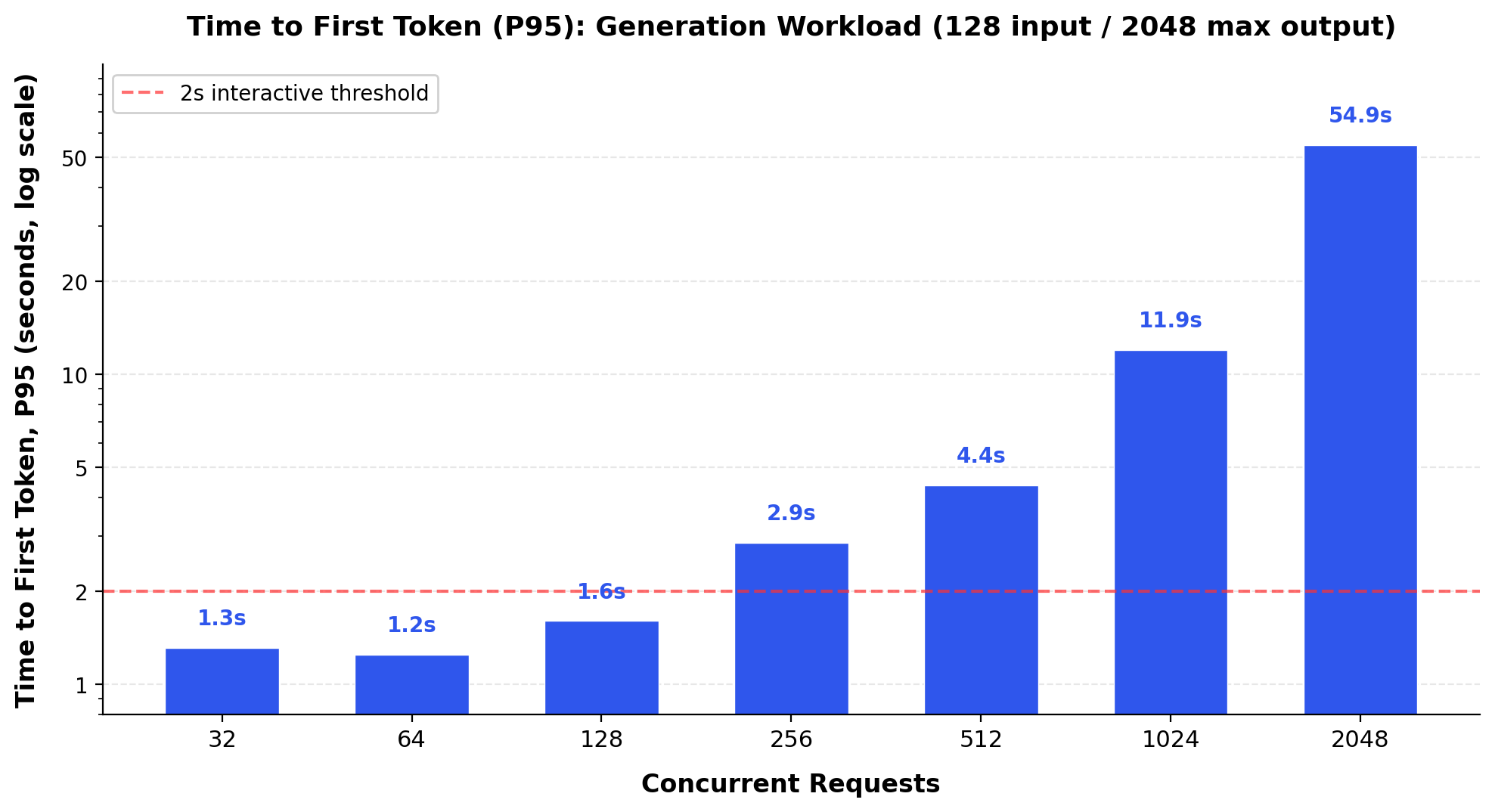
At moderate concurrency levels of 32 to 128 concurrent requests, the MI355X maintains P95 TTFT below 1.6 seconds. This performance results directly from the combination of 8TB/s HBM3e bandwidth and ROCm 7's optimized prefetching, which together enable rapid weight loading for initial token generation.
At 1,024 concurrent requests, P95 TTFT reaches approximately 12 seconds, reflecting the scheduling overhead at high concurrency. The system still serves over 1,785 output tokens per second at this scale, maintaining aggregate throughput even as tail latency increases. Infrastructure teams can scale from departmental pilots to enterprise-wide deployment without introducing perceptible latency degradation.
System-Level Comparison: MI355X vs MI300X Deployment
The MI355X does not simply extend the MI300X. It changes what a single 8-GPU server can realistically handle for trillion-parameter models. To quantify this improvement, both accelerators ran Kimi K2.5 on single 8-GPU nodes under identical workload profiles.
This is a system-level deployment comparison, not an architecture-isolation experiment. Each platform uses its optimal serving configuration for the same model (moonshotai/Kimi-K2.5): the MI355X serves at FP4 precision on the Dell PowerEdge XE9785L, while the MI300X serves at FP8 precision on the Dell PowerEdge XE9680. GPU generation, server platform, and numerical precision differ simultaneously. The throughput differences reported below reflect the combined effect of these factors, not any single architectural improvement in isolation. Isolating individual contributions would require controlled ablations (for example, both platforms at identical precision on the same server) that fall outside the scope of this paper.
For infrastructure teams, the system-level comparison is the decision-relevant metric. When evaluating GPU investments, what matters is the throughput, reliability, and cost delivered by the complete deployment stack.
The architectural differences between the two configurations are significant. The MI300X provides 192GB HBM3 per GPU (1.5TB total per node). The MI355X provides 288GB HBM3e per GPU (2.3TB total). The MI355X's larger memory and FP4 precision support give the serving stack more flexibility in how it distributes the model across GPUs, directly contributing to higher throughput and concurrency headroom.
Throughput: Consistent Gains Across Deployments
Up to 633x higher throughput where both systems are reliable; MI300X becomes unusable at real enterprise load, MI355X stays stable. At low to moderate concurrency, the MI355X delivers steady throughput improvements across all workload profiles. At 512 concurrent requests on the generation workload (128 input / 2048 output), the MI355X produces 1,032 output tokens per second compared to 708 on the MI300X. This represents a 1.46x improvement at a concurrency level where both systems operate without errors.
| Workload | Concurrency | MI300X (TPS) | MI355X (TPS) | Improvement |
|---|---|---|---|---|
| Generation (128/2048) | 128 | 304 | 424 | 1.40x |
| Generation (128/2048) | 256 | 477 | 691 | 1.45x |
| Generation (128/2048) | 512 | 708 | 1,032 | 1.46x |
| Long Context (2048/2048) | 128 | 303 | 393 | 1.30x |
| Long Context (2048/2048) | 256 | 407 | 662 | 1.63x |
| Short Context (128/128) | 512 | 861 | 1,117 | 1.30x |
| Short Context (128/128) | 1,024 | 1,189 | 1,838 | 1.55x |
Table 2 - System-Level Throughput: MI355X Deployment vs. MI300X Deployment at Error-Free Concurrency Levels. Both platforms: moonshotai/Kimi-K2.5. MI300X on XE9680 at FP8. MI355X on XE9785L at FP4. Differences reflect GPU generation, platform, and precision combined.
At concurrency levels where both GPUs operate error-free, the MI355X delivers 1.30x to 1.63x higher throughput depending on workload. The real gap emerges beyond these levels, where the MI300X stops functioning as a production system entirely.
The Reliability Cliff: Where Memory Constraints Become Service Outages
The throughput comparison tells only part of the story. The more consequential difference emerges at enterprise concurrency levels, where the MI300X’s memory constraints produce escalating error rates that make it unsuitable for production service.
On the generation workload (128 input / 2048 output), the MI300X begins failing requests at 1,024 concurrent users, with a 24% error rate. At 2,048 concurrent requests, errors climb to 65%. For the long-context workload (2048/2048), the reliability cliff arrives even earlier: 42% error rate at just 512 concurrent requests, rising to 71% at 1,024.
The MI355X maintains a zero-percent error rate through 2,048 concurrent requests on the generation workload. On the long-context workload (2048/2048), the MI355X begins producing errors at 2,048 concurrency (29.6%), but this occurs at a concurrency level where the MI300X has already reached 87.9% errors on the same workload.
| Workload | Concurrency | MI300X Errors | MI355X Errors | MI355X Effective Advantage |
|---|---|---|---|---|
| Generation (128/2048) | 1,024 | 24.0% | 0% | 3.0x effective throughput |
| Generation (128/2048) | 2,048 | 65.2% | 0% | MI300X non-functional |
| Long Context (2048/2048) | 512 | 41.9% | 0% | 4.3x effective throughput |
| Long Context (2048/2048) | 1,024 | 70.9% | 0% | MI300X no longer meets SLA |
Table 3 - Reliability Under Load: Error Rates at Enterprise Concurrency. Effective throughput = raw TPS x (1 - error rate). Both platforms: moonshotai/Kimi-K2.5. MI300X at FP8, MI355X at FP4. See System Under Test for full configuration.
At enterprise scale, the MI300X becomes unreliable, dropping up to two-thirds of requests on the generation workload. The MI355X maintains zero errors through 2,048 concurrent requests on this workload, delivering consistent responses instead of failures.
For IT leaders, this distinction is critical. A system that produces high token throughput but drops one in four requests does not meet production SLA requirements. The MI355X eliminates that failure mode entirely at these concurrency levels. The MI355X’s combination of higher raw throughput and zero errors at scale means infrastructure teams can deploy with confidence at concurrency levels that match real enterprise demand.
Latency: From Interactive to Unusable
The latency story reinforces the reliability findings. On the generation workload, the MI300X's 95th-percentile time to first token exceeds 2.2 seconds even at just 32 concurrent requests. That means 1 in 20 users waits more than two seconds for the first word to appear, which feels noticeably laggy. At 512 concurrent requests, that figure climbs to 395 seconds (over six minutes), rendering the system completely non-interactive.
The MI355X maintains P95 TTFT below 1.6 seconds at 128 concurrent requests. End users experience responsive, conversational interactions at concurrency levels where the MI300X has already become unusable.
What Drives the System-Level Improvement
Three architectural advances in CDNA 4 combine to produce these results:
Memory capacity and FP4 precision enable higher serving density. The MI355X's 288GB per GPU and FP4 precision reduce the per-instance memory footprint, giving the serving stack more headroom for concurrent inference than the MI300X at FP8 on 192GB GPUs.
8TB/s HBM3e bandwidth sustains throughput under load. Higher bandwidth per accelerator ensures that model weights stream at full speed even under heavy concurrent load.
AITER and ROCm 7 optimizations reduce per-token compute cost. Hardware-accelerated MoE routing and MLA attention computation reduce per-token compute cost, improving efficiency across all concurrent inference workloads.
The net effect is a platform that scales with concurrency rather than degrading under it. For organizations planning infrastructure investments around trillion-parameter models, this generational improvement changes the calculus from managing distributed complexity to deploying single-node solutions.
Operational Advantages: From Deployment to Production
The MI355X's memory capacity advantage translates into measurable operational improvements throughout the deployment lifecycle. Organizations reduce time to market, simplify infrastructure management, and lower total cost of ownership.
Accelerated Time to Market
When a new model releases, deployment speed determines competitive advantage. For Kimi K2.5, the MI355X eliminated the distributed deployment bottleneck entirely.
With 288GB per accelerator, the full Kimi K2.5 model fits within a single 8-GPU node's 2.3TB of combined memory. There is no need for custom sharding strategies, inter-node communication tuning, or distributed orchestration logic. Organizations running MI355X infrastructure achieved production deployment within hours of the Kimi K2.5 release.
Compare this timeline to the alternative. Deploying a 1 trillion parameter MoE model on accelerators with 192GB or less requires partitioning the model across multiple nodes. Engineering teams must implement and validate model-parallel strategies, tune inter-node communication, and test distributed fault handling. This process can extend deployment timelines from days to weeks per model release, creating a recurring tax on engineering productivity.
Over the course of a year with multiple major model releases, that deployment delay compounds. Teams that deploy in hours maintain a persistent advantage over teams that deploy in weeks.
Simplified Infrastructure
Single-node deployment reduces operational complexity at every layer of the stack.
Network configuration becomes simpler. A single-node MI355X deployment communicates entirely over high-speed on-node interconnects. There are no cross-node fabric requirements, no distributed routing tables, and no network partitioning risks during inference.
Monitoring becomes more focused. Operations teams track one system's health, memory utilization, and thermal state rather than coordinating distributed health checks across multiple nodes. When an issue arises, the fault domain is contained to a single machine. This improves mean time to diagnosis and recovery.
Resource allocation improves. Distributed deployments require over-provisioning to handle node failures and load imbalances. Single-node inference eliminates this overhead. Every GPU in the node contributes directly to serving user requests, improving hardware utilization rates.
Dell Enterprise Hub: Validated Model Deployment
Beyond raw software support, the path from model selection to production deployment is further streamlined through the Dell Enterprise Hub on Hugging Face. This curated repository provides validated, deployment-ready model containers tested on Dell PowerEdge platforms with AMD Instinct accelerators. Infrastructure teams can pull pre-optimized Kimi K2.5 containers and deploy with confidence, reducing the validation and configuration effort that typically accompanies new model adoption.
Total Cost of Ownership
Infrastructure consolidation drives long-term cost reduction across three dimensions.
Capital expenditure. A workload that requires two or more nodes on lower-memory accelerators runs on a single MI355X node. Fewer nodes and no dedicated network fabric reduce infrastructure-adjacent spend, including switches, cabling, and rack space. Organizations consolidating from multi-node to single-node deployments for this class of workload can expect meaningful savings on these line items, with the exact percentage varying by existing infrastructure and vendor agreements.
Operational expenditure. Single-node deployments require less administration. Fewer systems to patch, fewer firmware updates to coordinate, and fewer failure modes to document in runbooks. Operations teams can redirect this capacity toward application optimization and user experience improvements.
Opportunity cost. Every week spent engineering a distributed deployment for a new model is a week that model is not serving production traffic. For organizations where AI inference directly supports revenue-generating applications, the time-to-production gap has a measurable financial impact. Deploying in hours rather than weeks closes that gap.
A detailed analysis of power efficiency and tokens-per-watt performance across CDNA generations will follow in a companion brief focused on total cost of ownership at scale.
Conclusion: Removing Infrastructure Constraints
The trajectory of large language models points toward larger parameter counts, longer context windows, and more sophisticated architectures. The MI355X positions organizations to deploy these models without repeated infrastructure re-architecture.
The system-level comparison with the MI300X deployment underscores why this matters now. Running Kimi K2.5 on the same 8-GPU form factor, the MI355X deployment delivers up to 1.63x higher throughput at error-free concurrency levels and operates reliably at concurrency levels where the previous-generation deployment fails entirely. For organizations scaling AI inference to enterprise demand, this is the difference between a production-ready platform and an escalating engineering project.
The 288GB memory capacity and 8TB/s bandwidth provide headroom for the next generation of models beyond Kimi K2.5. When new models emerge, organizations with MI355X infrastructure can deploy immediately, maintaining competitive advantage through operational speed rather than hardware refresh cycles.
For infrastructure teams evaluating AI deployment strategy, the MI355X removes a critical constraint. Focus shifts from distributed systems engineering to application optimization and user experience. Production deployments accelerate from weeks to hours. Total cost of ownership decreases through consolidation and simplified operations.
The combination of CDNA 4 architecture and ROCm 7 software delivers day-0 support for emerging models. This readiness transforms how organizations respond to AI advancement: not with infrastructure crisis, but with immediate production deployment. For organizations planning 2026 GPU investments, prioritizing 288GB-class accelerators enables single-node deployment of the next wave of trillion-parameter models.
Learn more about AMD Instinct MI355X at amd.com/instinct
Addendum
All benchmark results in this paper were collected on the hardware and software configurations described below. Reproducing these results requires matching both the platform configuration and the specific model checkpoints.
Hardware Configuration
| Parameter | MI300X System | MI355X System |
|---|---|---|
| GPU Accelerators | 8x AMD Instinct MI300X | 8x AMD Instinct MI355X |
| GPU Architecture | CDNA 3 | CDNA 4 |
| HBM per GPU | 192 GB HBM3 | 288 GB HBM3E |
| Server | Dell PowerEdge XE9680 | Dell PowerEdge XE9785L |
| Software Stack | ROCm™ 7.0, Ubuntu 24.04 | ROCm 7.0, Ubuntu 24.04 |
Software Configuration
| Component | Detail |
|---|---|
| ROCm version | ROCm™ 7 |
| Inference engine | vLLM 0.15.0 |
| MI355X model checkpoint | amd/Kimi-K2.5-MXFP4 (MXFP4 quantization via AMD Quark) |
| MI300X model checkpoint | moonshotai/Kimi-K2.5 (FP8) |
| MI355X serving config | FP4 precision |
| MI300X serving config | FP8 precision |
| Inference Container | Available via Dell Enterprise Hub on Hugging Face |
What This Comparison Measures
The MI355X and MI300X configurations differ in three simultaneous dimensions: GPU generation (CDNA 4 vs. CDNA 3), numerical precision (FP4 vs. FP8), and server platform (XE9785L vs. XE9680). This is a deliberate design choice. The comparison represents how an enterprise IT team would actually deploy Kimi K2.5 on each platform to maximize throughput, using the most capable precision and topology available on each generation.
This is a system-level deployment comparison, not an architecture-isolation experiment. The reported 1.30x to 1.63x throughput improvements reflect the combined effect of CDNA 4 hardware, FP4 precision, larger memory capacity, and ROCm 7 software optimizations for Kimi K2.5 at error-free concurrency levels. Isolating the contribution of any single factor would require controlled ablations (for example, both platforms at identical precision on the same server) that are outside the scope of this paper.
For infrastructure teams, the system-level comparison is the decision-relevant metric. When evaluating GPU investments, what matters is the throughput, reliability, and cost delivered by the complete deployment stack, not the contribution of any individual component in isolation.
Copyright © 2026 Metrum AI, Inc. All Rights Reserved. This project was commissioned by Dell Technologies. Dell, Dell PowerEdge and other trademarks are trademarks of Dell Inc. or its subsidiaries. AMD, Instinct, ROCm, EPYC and combinations thereof are trademarks of Advanced Micro Devices, Inc. All other product names are the trademarks of their respective owners.
DISCLAIMER - Performance varies by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance.