How OCP Microscaling Formats and AMD Quark Deliver 4-Bit Quantization at Near-Zero Inference Error Rate

Executive Summary
Inference cost now exceeds training cost as the primary infrastructure challenge for production AI. Serving a 235-billion parameter model at enterprise concurrency can require multiple accelerator nodes, with power and hardware expenditures scaling proportionally. For IT leaders under pressure to expand AI capacity without expanding budgets, precision format selection offers one of the most effective levers available.
On the Dell PowerEdge XE9785L (liquid-cooled) with AMD Instinct MI355X accelerators, MXFP4 delivers 1.15x to 2.3x more throughput than FP8 on the same node, and up to 6.1x more throughput than MI300X FP8 when combining the benefits of new hardware, new precision format, and the liquid-cooled Dell PowerEdge XE9785L platform. GPU power efficiency improves up to 2x on a tokens-per-kilowatt basis at matched concurrency, with the largest gains on long-input document processing workloads. These gains translate into far more concurrent users within the same latency SLAs, with no retraining and no code changes. All benchmark configurations reported here produced zero inference errors across their full test duration. The deployment path requires minimal operational change: Quark-quantized MXFP4 models export directly to standard Hugging Face safetensors format and deploy through vLLM or SGLang.
Key Results at a Glance
| Up to 2.3x throughput over FP8 | Up to 6.1x throughput over MI300X |
| MXFP4 vs. FP8 on the same MI355X node at high concurrency | MI355X MXFP4 vs. MI300X FP8 at production concurrency (combined hardware + precision gain) |
| Up to 2x GPU power efficiency gainTokens per kilowatt at matched concurrency, MI355X MXFP4 vs. MI300X FP8 | 8x more concurrent usersWithin a 100ms per-token SLA on short-form workloads |
The Quantization Challenge
The question is no longer whether to quantize, but how far precision can drop before accuracy degrades and users notice. Traditional INT4 quantization forces a painful tradeoff. Its uniform precision grid clips outlier values or sacrifices resolution across the entire weight distribution. This results in measurable accuracy loss that pushes teams to over-provision hardware at higher precision, erasing the cost savings quantization was supposed to deliver.
This effect is supported by research, consistently showing that naive INT4 post-training quantization can produce perplexity increases and accuracy drops that make models unsuitable for production deployment[1]. Advanced algorithms like GPTQ and AWQ partially address these limitations through sophisticated calibration, but they cannot overcome the fundamental constraint of uniform representation.
The AMD Instinct MI355X introduces hardware-native support for MXFP4, a floating-point format designed specifically for the distribution patterns observed in deep learning workloads. Combined with the AMD Quark quantization toolkit and ROCm 7 runtime optimizations, this architecture delivers 4-bit inference throughput while preserving output reliability. All benchmark configurations reported here produced zero inference errors.
Understanding Microscaling Formats
MXFP4 works like a smarter 4-bit format that shares a single scale factor across small blocks of values, preserving detail where model weights concentrate instead of wasting bits on empty range. The Open Compute Project (OCP) published the Microscaling Formats (MX) specification with contributions from AMD, Arm, Intel, Meta, Microsoft, NVIDIA, and Qualcomm[2]. MX formats define a new approach to low-precision data representation. Rather than treating each value independently, MX formats share a scaling factor across blocks of elements, enabling efficient representation with reduced storage overhead.
MXFP4 encodes each block of 32 elements using 4-bit floating-point values (E2M1 format: 2 exponent bits, 1 mantissa bit) with a shared 8-bit scale factor (E8M0). This structure requires only 136 bits per block (17 bytes), compared to 1,024 bits (128 bytes) for the equivalent FP32 representation. The 7.5x reduction in storage translates directly to reduced memory bandwidth requirements and improved cache utilization during inference.
The Floating-Point Advantage
The critical difference between MXFP4 and INT4 lies in how values distribute across the representable range. Floating-point formats space their quantization levels logarithmically, providing higher resolution near zero and lower resolution at extremes. This non-uniform grid aligns naturally with neural network parameters, which typically follow approximately Gaussian distributions centered near zero.
When an outlier activation occurs in INT4, the uniform grid forces either severe clipping or scale expansion that quantizes most values to zero. In MXFP4, the exponent bits provide dynamic range while the block-level scale factor adjusts to local magnitude. The outlier receives appropriate representation, and neighboring values maintain precision. This architectural difference explains why MXFP4 consistently demonstrates superior signal-to-noise ratio for deep learning tensors compared to INT4 at equivalent bit-widths[3].
The MI355X implements native MXFP4 matrix multiplication through its Matrix Fused Multiply Add (MFMA) scale instructions. This hardware acceleration eliminates the dequantization overhead that software-emulated approaches require, delivering up to 10.1 petaFLOPS of theoretical peak MXFP4 compute performance per accelerator
AMD Quark: Production-Ready Quantization
In practice, Quark takes a standard FP16 or BF16 model, runs an automated calibration pass, and outputs an MXFP4 checkpoint that existing serving stacks can load with no model changes and no custom kernels.Converting a model from FP16 or BF16 to MXFP4 requires careful calibration to minimize accuracy loss. AMD Quark provides a comprehensive toolkit for this transformation, integrating established algorithms with MI355X-specific optimizations[4].
Quark supports multiple quantization strategies, each offering different tradeoffs between calibration time, accuracy preservation, and computational overhead. For production deployment of large models, AutoSmoothQuant provides the optimal balance. This algorithm adaptively smooths outliers on a per-layer basis, reducing the dynamic range that any single block must represent. Unlike manual SmoothQuant tuning, AutoSmoothQuant requires no hyperparameter search, making it practical for enterprise deployment pipelines.
Quantization Workflow
A typical Quark workflow for MXFP4 quantization proceeds through three stages. First, the model loads from a standard Hugging Face checkpoint or safetensors format. Second, Quark applies the selected quantization scheme with calibration data. Third, the quantized model exports in a format compatible with vLLM, SGLang, or other serving frameworks.
Quark completes the quantization process in hours, even for models exceeding 200 billion parameters. It parallelizes calibration across available GPUs, and the exported model deploys immediately on MI355X infrastructure without additional conversion steps.
Mixed-Precision Strategies
Not all model layers respond equally to aggressive quantization. Embedding layers and certain attention projections often benefit from higher precision, while MLP layers tolerate lower precision with minimal impact. Quark supports layer-wise mixed-precision configuration, enabling MXFP4 for bulk compute with FP8 for sensitive operations.
This granular control allows organizations to tune the precision-performance tradeoff for their specific workloads. A model serving factual question-answering may tolerate more aggressive quantization than one performing complex reasoning tasks. Quark's configuration system exposes these choices without requiring deep expertise in quantization theory.
Performance Analysis: Qwen3-235B-A22B
To quantify the throughput advantage of MXFP4 over FP8, benchmark testing compared identical workloads on the same MI355X hardware. All tests ran on a Dell PowerEdge XE9785L liquid-cooled server equipped with eight AMD Instinct MI355X accelerators, ROCm 7, and vLLM as the serving framework. Baseline MI300X results used a Dell PowerEdge XE9680 with eight MI300X accelerators under the same software stack. Qwen3-235B-A22B was selected as the benchmark model because its 235-billion parameter Mixture of Experts architecture (128 experts, 8 active, 22B activated parameters) represents the class of large sparse models increasingly adopted for production inference. MXFP4 quantization via Quark applies broadly to transformer-based architectures; the results presented here are representative of the throughput characteristics organizations can expect across similar large-scale models.
Runs with greater than 10% error rate were excluded from all reported results. All retained configurations produced zero inference errors across their full test duration.
Peak Throughput by Workload
Each AI workload has a distinct input/output token signature that stresses hardware differently. Short prompts with short replies characterize chatbots and API-driven Q&A. Long inputs with short outputs define document classification, RAG, and compliance review. The MI355X with MXFP4 leads across all four profiles tested, with gains increasing at higher concurrency.
| Workload | MI355X MXFP4Peak (tok/s) | MI300X FP8Peak (tok/s) | Gain | Example Uses |
|---|---|---|---|---|
| 128 in / 128 out | 33,106 | 7,799 | 4.2x | Chat, Q&A, autocomplete |
| 128 in / 2,048 out | 43,916 | 8,278 | 5.3x | Content gen, code gen |
| 2,048 in / 128 out | 10,806 | 1,778 | 6.1x | RAG, classify, compliance |
| 2,048 in / 2,048 out | 18,395 | 4,096 | 4.5x | Research, translation |
Table 1 - Peak throughput across all tested concurrency levels. MI355X MXFP4 (XE9785L, 8-GPU) vs. MI300X FP8 (XE9680, 8-GPU). Qwen3-235B-A22B. Runs with >10% error rate excluded. Gain reflects the combined benefit of new hardware architecture, new precision format, and new platform.
The largest absolute advantage appears on document-processing workloads (2,048 input / 128 output), where the MI355X with MXFP4 delivers 6.1x the peak throughput of the MI300X with FP8. Long-generation workloads (128 input / 2,048 output) reach 5.3x. Even short-form chat workloads (128/128) show a 4.2x improvement. These gains reflect the combined benefit of MI355X hardware architecture (CDNA 4 vs. CDNA 3), MXFP4 precision (vs. FP8), and the Dell PowerEdge XE9785L liquid-cooled platform (vs. XE9680).
Throughput Comparison
On the same MI355X node, MXFP4 delivers approximately 1.2x to 1.5x more throughput at moderate concurrency, and up to 2.3x at very high concurrency, depending on workload profile. Figure 1 illustrates how the throughput advantage scales with concurrency on a representative long-generation workload (128 input / 2,048 output tokens).
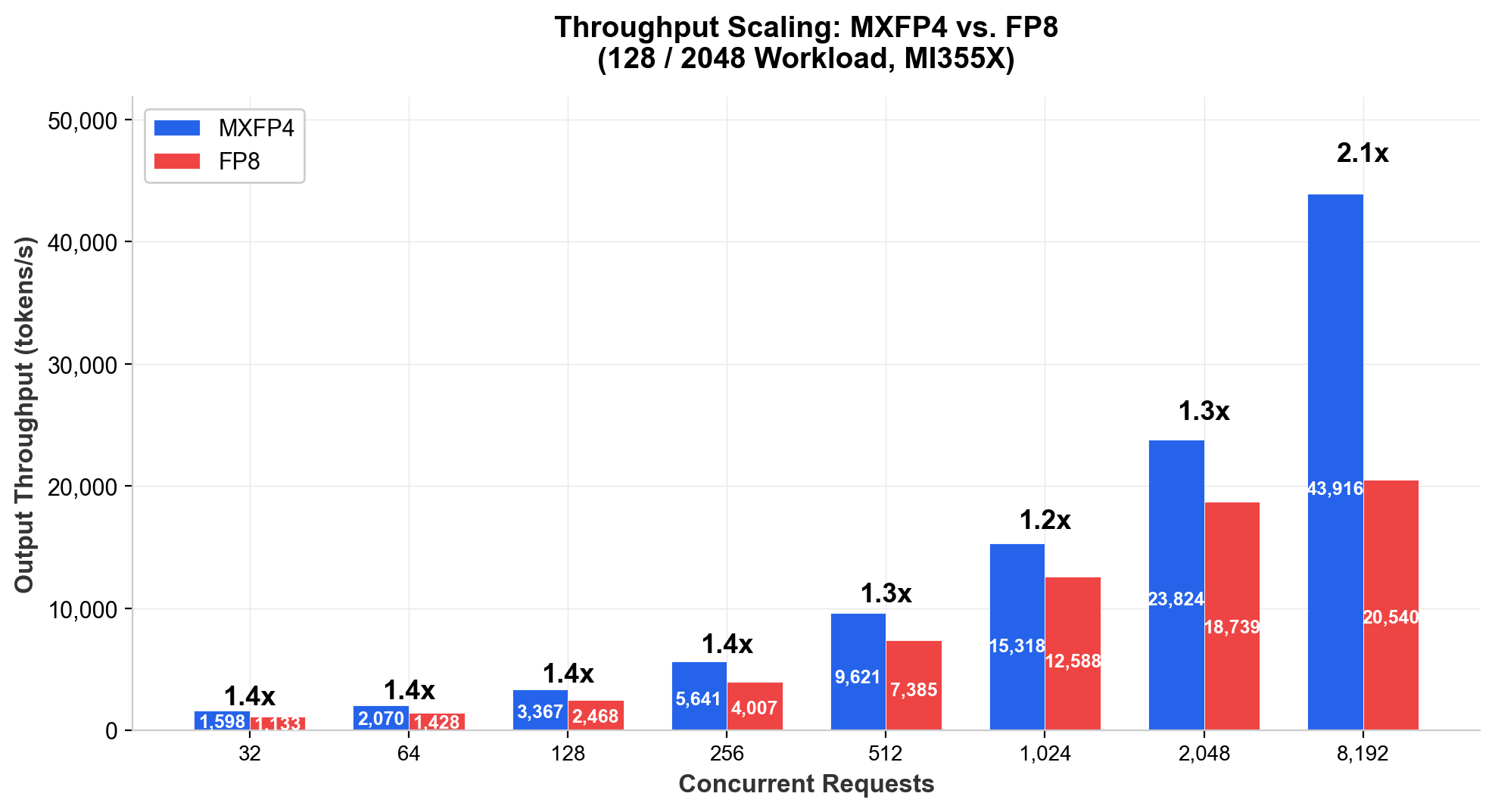
Figure 1 - MXFP4 vs. FP8 throughput scaling with concurrency (128/2048 workload). Qwen3-235B-A22B on Dell PowerEdge XE9785L, 8x AMD Instinct MI355X.
At moderate concurrency (32 to 1,024 requests), MXFP4 delivers 1.15x to 1.45x more throughput than FP8 across all workload profiles. The advantage grows with scale. For long-generation workloads (2048/2048) at 8,192 concurrent requests, MXFP4 produces 2.30x more output tokens per second than FP8, as FP8 throughput plateaus while MXFP4 continues to scale.
Consider a production deployment currently handling 10 million tokens daily on FP8 at 512 concurrent requests with 128-token outputs. Switching to MXFP4 on the same hardware adds approximately 26% throughput, enabling the same node to handle 12.6 million tokens daily without additional infrastructure.
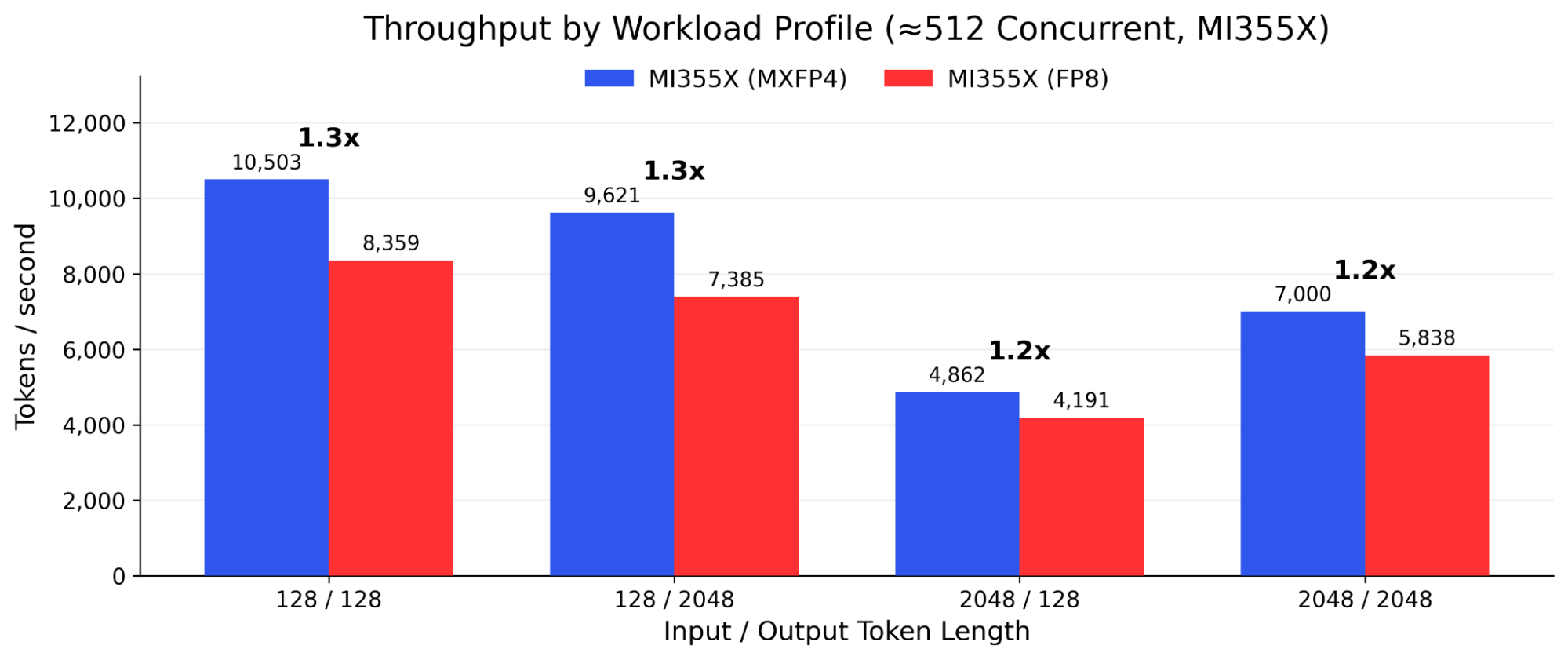
Figure 2 - MXFP4 vs. FP8 across workload profiles at 512 concurrent requests. Qwen3-235B-A22B on Dell PowerEdge XE9785L, 8x AMD Instinct MI355X.
Latency Characteristics
Throughput measures aggregate capacity. Latency governs user experience. Two metrics matter for interactive inference: Time to First Token (TTFT), which controls perceived responsiveness, and Time Per Output Token (TPOT), which controls perceived generation speed. The benchmark suite captured both across all configurations, with the most significant finding shown in Figure 3.
At moderate concurrency, MXFP4 makes each output token 20% to 29% faster than FP8 on the same MI355X hardware. At high concurrency on long-context workloads, MXFP4 keeps time to first token around 1 to 1.5 seconds, where FP8 can spike to 6 to 24 seconds, maintaining responsive feedback at user scales where FP8 cannot.
For short-input decode (128-token prompts) at moderate concurrency (32 to 512 requests), MXFP4 reduces average TPOT by 20% to 29% compared to FP8 on the same MI355X hardware. The advantage narrows at higher concurrency as the workload becomes more compute-bound. At 128 concurrent requests, MXFP4 delivers 31.3 ms per token versus 43.2 ms for FP8 (1.38x). The advantage holds across generation lengths and moderate concurrency levels.
The more significant finding is in TTFT at high concurrency with long contexts. At 1,024 concurrent requests with 2048/2048 tokens, MXFP4 delivers first-token in 1.2 seconds while FP8 requires 24.4 seconds (20.9x improvement). On the 2048/128 profile at the same concurrency, MXFP4 achieves 1.4 seconds versus 6.6 seconds for FP8. This reflects FP8's inability to sustain prefill once the KV cache saturates available memory bandwidth.
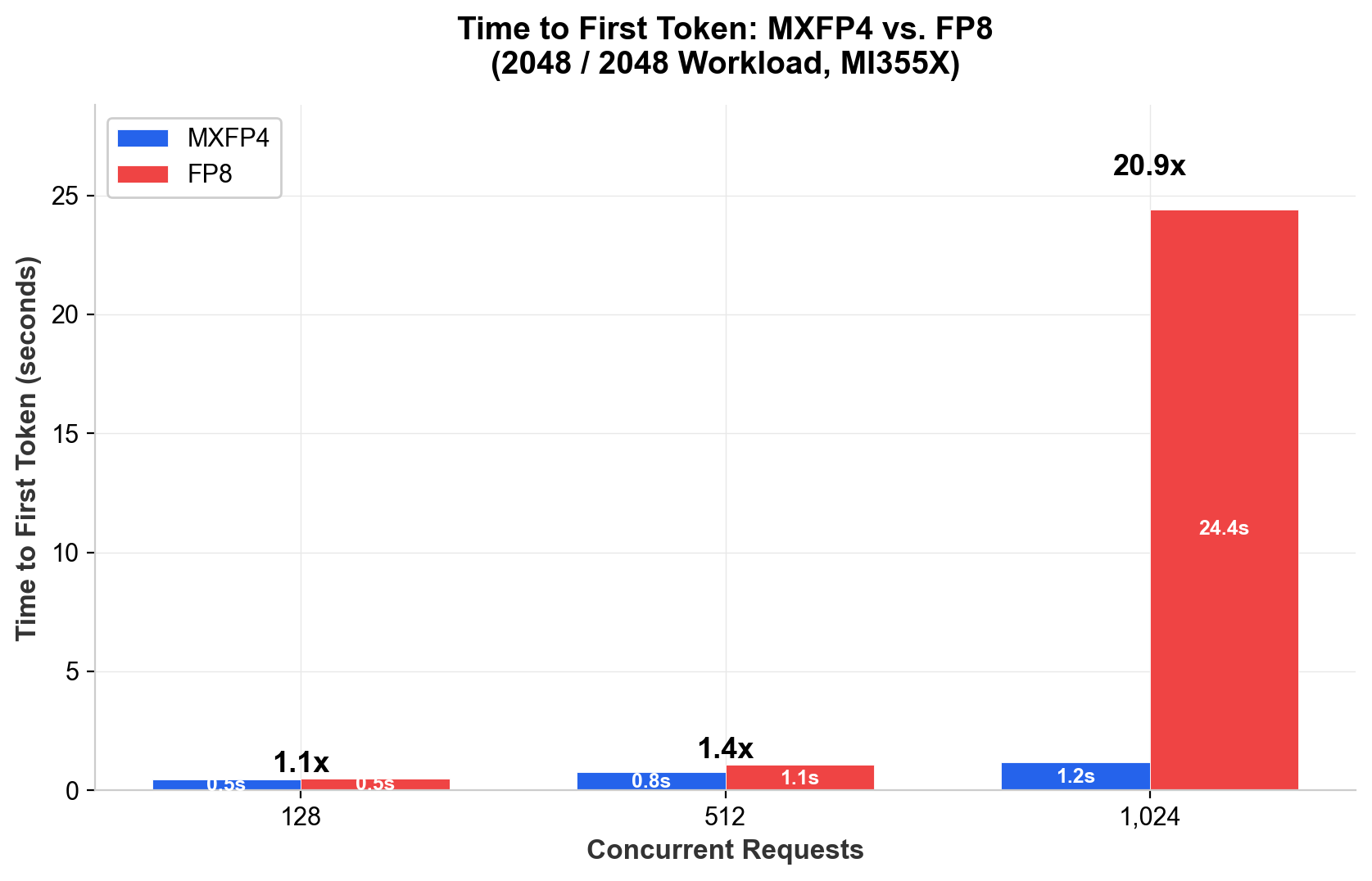
Figure 3 - Time to First Token: MXFP4 vs. FP8 at high concurrency (2048/2048 workload). Qwen3-235B-A22B, Dell PowerEdge XE9785L, 8x MI355X. Lower is better.
For capacity planning, if an SLA requires sub-second TTFT for 2048-token prompts, FP8 supports roughly 256 concurrent requests before crossing that threshold. MXFP4 extends the limit beyond 512 concurrent requests, effectively doubling the concurrent user capacity within the same SLA envelope.
Latency SLA Compliance: The 100ms Threshold
A 100ms per-token inter-token latency (ITL) is a practical planning threshold for responsive AI generation. The ITL values in this analysis are derived from throughput (ITL = 1,000 / (tok/s / concurrent requests)), not measured p95 or p99 inter-token latency. They serve as capacity-planning heuristics, not directly benchmarked SLA guarantees. At this target, a 128-token response completes in roughly 13 seconds, acceptable for most asynchronous and batch-adjacent applications. For real-time streaming, lower targets apply.
The MI355X with MXFP4 sustains sub-100ms per-token latency at up to 8x more concurrent users than the MI300X with FP8, while delivering 4x to 7x more aggregate throughput within the same SLA window.
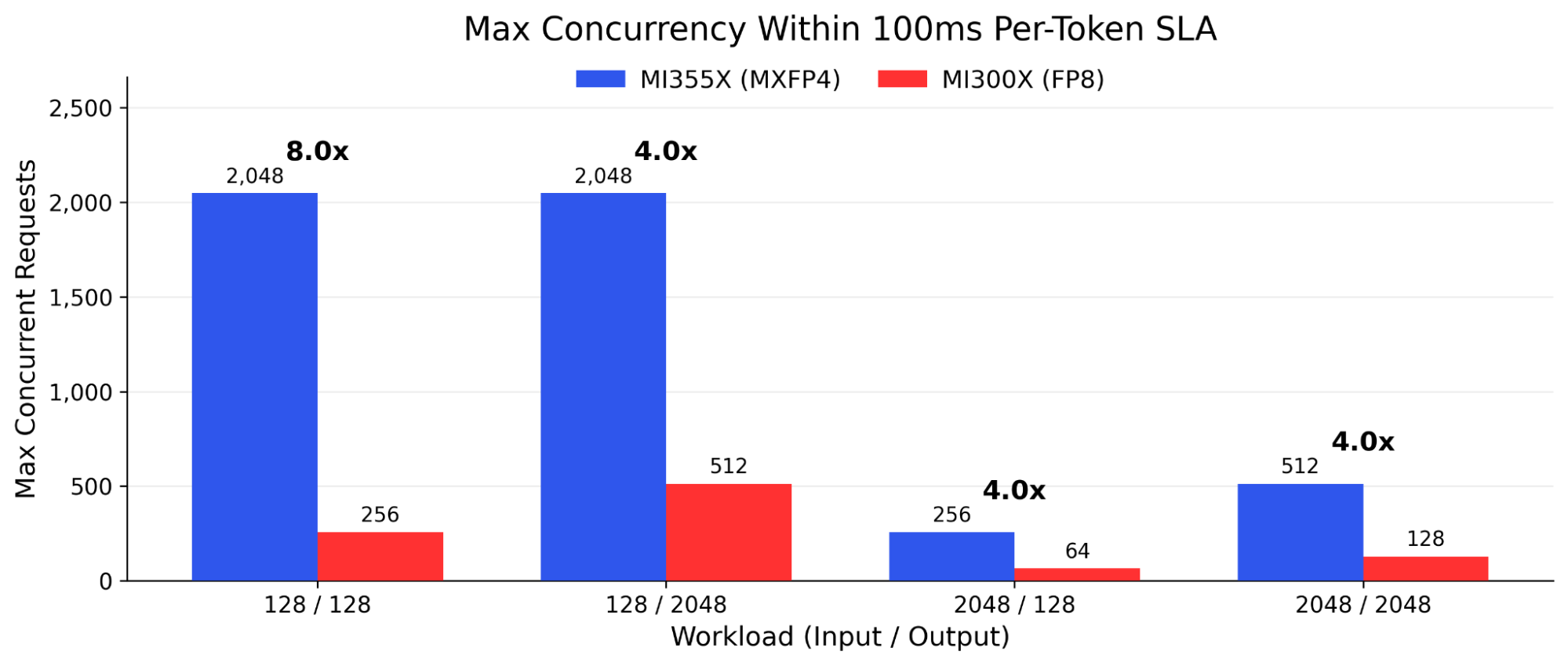
Figure 4 - Maximum concurrency within 100ms per-token SLA. Derived ITL = 1,000 / (tok/s / concurrent requests).
For any platform running inference at scale, whether a developer API, enterprise AI gateway, or consumer product, the 100ms per-token threshold defines whether the experience feels responsive or sluggish. The MI355X with MXFP4 pushes that SLA boundary 4x to 8x further than the MI300X with FP8. That translates directly to more users served at the same quality of experience, without adding hardware.
Scaling Behavior at High Concurrency
The data reveals an important inflection above 1,024 concurrent requests. At moderate concurrency, both precision formats scale in rough proportion, producing improvement ratios of 1.15x to 1.45x. Above 2,048 concurrent requests, FP8 throughput begins to plateau while MXFP4 continues to scale.
This divergence is most visible in long-generation workloads (2,048/2,048), where FP8 throughput effectively caps near 8,000 tokens per second regardless of additional concurrency. MXFP4 reaches 18,395 tokens per second at 8,192 concurrent requests on the same workload. On long-input workloads (2,048/128), MI300X FP8 plateaus at approximately 1,750 tokens per second from 2,048 concurrent onward, while MI355X MXFP4 continues scaling to 10,806 tokens per second.
Two architectural factors drive this behavior. First, MXFP4 model weights occupy half the HBM footprint of FP8, freeing memory bandwidth for KV cache operations that become the bottleneck at high concurrency. Second, the MI355X’s native MFMA scale instructions process MXFP4 matrix operations without the dequantization overhead that constrains FP8 throughput as compute utilization approaches saturation.
For capacity planning, the implication is direct: the return on investment for MXFP4 increases with deployment scale. Organizations operating inference nodes at production concurrency levels (512 and above) realize substantially more benefit than moderate-concurrency benchmarks alone suggest.
Generational Improvement: MI355X MXFP4 vs. MI300X FP8
The performance comparison between MI355X MXFP4 and MI300X FP8 quantifies the combined benefit of three factors: new accelerator hardware (CDNA 4 vs. CDNA 3), new precision format (MXFP4 vs. FP8), and new platform architecture (Dell PowerEdge XE9785L liquid-cooled vs. XE9680). These factors are not independently separable in this comparison. Both configurations ran Qwen3-235B-A22B on 8-GPU nodes.
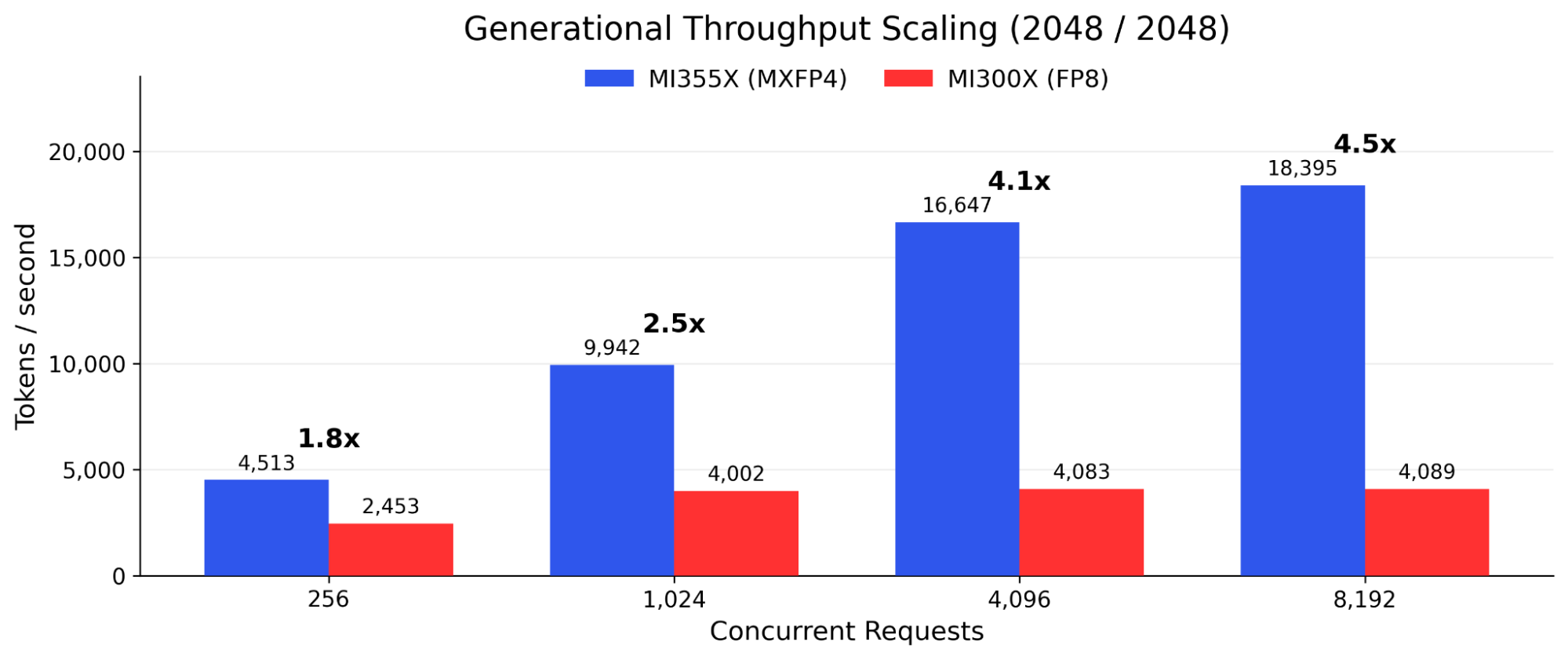
Figure 5 - MI355X MXFP4 vs. MI300X FP8 throughput scaling (2048/2048 workload)
At a 100ms per-token SLA, MXFP4 supports 4x to 8x more concurrent users than MI300X FP8 on the same workloads. At moderate concurrency (128 to 256 requests), the MI355X with MXFP4 delivers 1.45x to 2.92x the throughput of the MI300X with FP8, depending on workload profile. The advantage is most pronounced for long-input, short-output workloads (2,048/128), where the MI300X’s narrower memory bandwidth and lack of native FP4 compute constrain throughput scaling.
At 1,024 concurrent requests, the generational gap widens to 2.48x for long-context generation and 3.79x for long-input summarization tasks. At 8,192 concurrent, document-processing workloads (2,048/128) reach 6.1x. For organizations currently operating MI300X infrastructure, these results establish a concrete performance baseline for migration planning.
Enterprise Use Case: Compliance and Document Intelligence
Compliance checks, regulatory document review, financial risk analysis, and contract classification all share a common token profile: long inputs (2,048+ tokens of document context) with short outputs (128 tokens of classification, risk score, or structured response). This is the workload where the MI355X with MXFP4 delivers its largest absolute and proportional advantage.
At 1,024 concurrent requests, a practical operational load for enterprise platforms, MXFP4 delivers 6,188 tokens per second versus 1,632 tokens per second for MI300X FP8: 3.8x more capacity. At peak concurrency, the ratio reaches 6.1x. Document throughput translates directly to review capacity: 6.1x throughput means 6.1x more documents reviewed per hour on equivalent hardware.
Regulatory workloads often face batch deadlines: end-of-day portfolio reviews, overnight compliance sweeps, and real-time transaction monitoring thresholds. For real-time monitoring scenarios where the 100ms per-token SLA applies, MI300X FP8 supports only 64 concurrent document streams. MI355X MXFP4 sustains 256 concurrent streams, processing 4x more documents under active review simultaneously.
Output Reliability
Throughput gains deliver value only if the model produces reliable output under load. The benchmark suite tracked inference error rates across all tested configurations. All results retained in this report produced zero errors across their full test duration, confirming that MXFP4 quantization via Quark produces consistent inference output under production concurrency.
It is important to distinguish inference error rate from model accuracy. The benchmarks reported here measure whether the serving stack returns valid, complete responses at each precision level. They do not measure downstream task accuracy metrics such as MMLU scores, perplexity, or factual retrieval precision. These task-level evaluations depend on the specific model, dataset, and application, and should be validated independently for each deployment.
Independent MLPerf Inference v5.1 results provide additional context for MXFP4 reliability. AMD's MXFP4 submission on MI355X for Llama 2-70B met the accuracy targets required by the benchmark's closed division [5]. While these results validate MXFP4 as a datatype on MI355X hardware, they apply specifically to Llama 2-70B under MLPerf evaluation criteria and should not be interpreted as a direct accuracy guarantee for Qwen3-235B-A22B or other models. Organizations should run their own accuracy evaluation pipelines before deploying any quantized model to production.
Implementation Considerations
Adopting MXFP4 quantization involves minimal operational complexity when compared to other precision reduction strategies. The quantization workflow integrates with existing model management practices, and the quantized models deploy through standard serving frameworks.
Infrastructure Requirements
MXFP4 inference requires MI355X accelerators with ROCm 7.0 or later. Earlier AMD Instinct generations (MI300X, MI325X) can emulate MXFP4 through software dequantization, providing compatibility for model evaluation but without the full throughput benefits of native hardware support.
The quantization process itself can run on any ROCm-compatible hardware. Organizations can quantize models on existing MI300X infrastructure, then deploy the quantized checkpoints to MI355X systems for production inference. This flexibility simplifies the transition path for established AMD deployments.
Serving Framework Integration
vLLM provides native support for Quark-quantized MXFP4 models. Loading a quantized checkpoint requires no code changes beyond specifying the model path. vLLM automatically detects the quantization format and configures the appropriate kernels for MI355X execution.
SGLang similarly supports MXFP4 models with automatic detection. For organizations using custom serving infrastructure, Quark exports to Hugging Face-compatible safetensors format with embedded quantization metadata, enabling integration with any framework that can load quantized models.
Dell PowerEdge Platform Integration
The Dell PowerEdge XE9785L is a liquid-cooled server platform purpose-built for high-density AI inference. Liquid cooling enables the XE9785L to sustain full accelerator performance under continuous load without thermal throttling, a critical requirement for production inference at the concurrency levels tested in this paper. The liquid-cooled design also reduces data center cooling overhead, contributing to the power efficiency advantages reported in the TCO analysis.
Dell iDRAC (Integrated Dell Remote Access Controller) delivers hardware-level management capabilities critical for production AI infrastructure: real-time GPU telemetry, thermal monitoring, remote firmware updates, and automated alerting. These capabilities enable infrastructure teams to monitor power draw, memory utilization, and accelerator health across fleet deployments without custom tooling. Pre-validated configurations available through Dell reduce the time from hardware delivery to production inference.
Total Cost of Ownership Impact
The throughput improvement from MXFP4 translates directly to infrastructure economics. The following analysis uses GPU-level power measurements (sum of eight accelerator P90 power readings via amd-smi). These figures represent GPU power draw under inference load, which operates well below the 1,400W per-accelerator TDP because inference workloads do not saturate all compute units simultaneously. Host CPU, memory, networking, and cooling overhead are not included in the reported figures. Figure 6 presents the power-normalized throughput comparison at 512 concurrent requests.
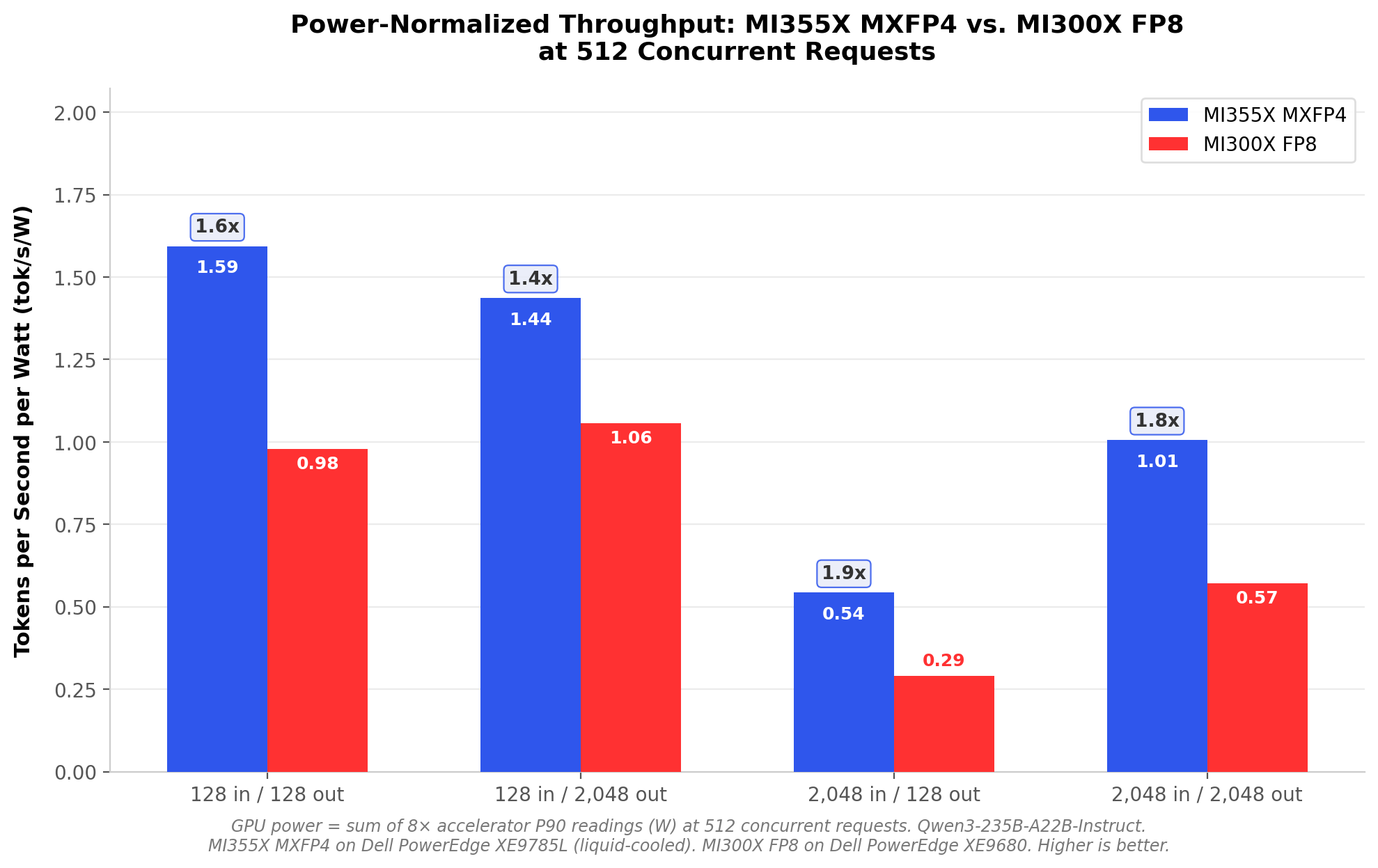
Figure 6 - Power-normalized throughput: MI355X MXFP4 vs. MI300X FP8 at 512 concurrent requests
GPU-level power consumption confirms the efficiency advantage. At 512 concurrent requests, MI355X GPUs draw approximately 6,591W to 8,958W total (sum of eight accelerator P90 readings) under sustained MXFP4 inference load, compared to 4,888W to 5,601W total GPU power for the MI300X running FP8. The MI355X draws more absolute GPU power, but the throughput gain is proportionally larger. Normalizing for throughput, the MI355X with MXFP4 yields 0.54 to 1.59 tokens per second per watt at 512 concurrent. The MI300X with FP8 yields 0.29 to 1.06 tokens per second per watt. That represents a 1.4x to 1.9x improvement in power-normalized throughput, with the largest efficiency gain on long-input document workloads (2048/128).
To illustrate: at $0.10/kWh, the MI300X node running FP8 at 512 concurrency on a 2048/128 workload costs approximately $352/month in GPU power alone, producing 1,420 tokens per second. The MI355X with MXFP4 produces 4,862 tokens per second at $645/month in GPU power. In absolute terms, the MI355X draws more GPU power. The value appears when normalizing for capacity: the MI300X costs $0.25 in GPU power per token-per-second of capacity per month, while the MI355X costs $0.13, a 46% reduction in the GPU power cost of each unit of inference throughput. For organizations that need 4,862 tokens per second of capacity, the choice is one MI355X node or approximately 3.4 MI300X nodes. Three MI300X nodes would draw roughly 14,664W in GPU power ($1,056/month), making the single MI355X node 39% less expensive in GPU power while delivering the same aggregate throughput.
The memory footprint reduction compounds these benefits. MXFP4 model weights occupy half the space of FP8, freeing HBM capacity for larger KV caches. Longer context windows support more complex conversations without requiring model sharding. More concurrent users fit within a single node's memory budget. These efficiency gains accumulate across the deployment lifecycle, reducing both capital expenditure and ongoing operational costs.
Conclusion: Production-Ready 4-Bit Inference
The combination of OCP MXFP4 standardization, AMD Quark tooling, MI355X hardware support, and Dell PowerEdge platform validation establishes a production-ready path to 4-bit inference.
Performance. MXFP4 on MI355X delivers up to 6.1x throughput over MI300X FP8 (reflecting the combined benefit of new hardware, new precision format, and new platform), with the largest gains on document-processing and long-input workloads critical to regulated industries. On the same MI355X hardware, MXFP4 delivers 1.15x to 2.30x throughput over FP8, with the advantage growing at higher concurrency. At the 100ms per-token SLA, MXFP4 supports 4x to 8x more concurrent users, directly expanding the operational envelope for latency-sensitive applications.
Efficiency. At matched concurrency, the MI355X with MXFP4 delivers up to 2x more tokens per kilowatt of GPU power, with the largest efficiency gains on long-input document workloads. In concrete terms, a single MI355X MXFP4 node can deliver 3.4x the throughput of an MI300X FP8 node. While the MI355X draws more absolute GPU power per node, the cost per unit of inference capacity drops by approximately 46%, enabling organizations to consolidate three to four MI300X nodes into one with lower total GPU power draw and proportionally lower infrastructure cost.
Practicality. No retraining and no framework changes are required. Organizations can quantize existing models with AMD Quark on current MI300X infrastructure, validate accuracy, and deploy to MI355X when hardware arrives. Zero inference errors across all retained benchmark configurations, combined with MLPerf Inference v5.1 validation of MXFP4 on Llama 2-70B, support confidence in the production viability of 4-bit floating-point inference. Organizations should validate task-level accuracy through their own evaluation pipelines before deployment.
Learn more about AMD Instinct MI355X at amd.com/instinct
References
[1] T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, "QLoRA: Efficient Finetuning of Quantized LLMs," arXiv preprint arXiv:2305.14314, 2023.
[2] Open Compute Project, "OCP Microscaling Formats (MX) Specification v1.0," September 2023. [Online]. Available: https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf
[3] B. D. Rouhani et al., "Microscaling Data Formats for Deep Learning," arXiv preprint arXiv:2310.10537, 2023.
[4] AMD, "AMD Quark Documentation," 2025. [Online]. Available: https://quark.docs.amd.com/
[5] AMD, "Technical Dive into AMD's MLPerf Inference v5.1 Submission," ROCm Blogs, September 2025. [Online]. Available: https://rocm.blogs.amd.com/artificial-intelligence/mlperf-inference-v5.1/
[6] AMD, "High-Accuracy MXFP4, MXFP6, and Mixed-Precision Models on AMD GPUs," ROCm Blogs, October 2025. [Online]. Available: https://rocm.blogs.amd.com/software-tools-optimization/mxfp4-mxfp6-quantization/
Copyright © 2026 Metrum AI, Inc. All Rights Reserved. This project was commissioned by Dell Technologies. Dell, Dell PowerEdge, Dell iDRAC and other trademarks are trademarks of Dell Inc. or its subsidiaries. AMD, Instinct, ROCm, EPYC and combinations thereof are trademarks of Advanced Micro Devices, Inc. All other product names are the trademarks of their respective owners.
DISCLAIMER - Performance varies by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance.