
In the rapidly evolving landscape of large language models (LLMs), accurate performance benchmarking has become critical for organizations seeking to deploy these models at scale. Metrum Insights addresses this challenge with a production-grade benchmarking framework designed to deliver real-world performance metrics that matter.
Understanding Metrum Insights
Metrum Insights' performance benchmarking methodology consists of three core components to deliver accurate and reproducible performance metrics:
- Metrum Bench (Load Generator with Prompt Randomization) - Generates realistic request patterns with diverse prompt configurations, including varied input and output token lengths
- Load Balancer (NGINX) - Distributes traffic intelligently across multiple serving instances
- Multiple LLM Serving Replicas - Metrum Insights determines the minimum tensor parallelism (TP) required to load the LLM onto target hardware, and starts multiple LLM serving replicas based on the determined TP and GPU count
The following sections detail the methodologies.
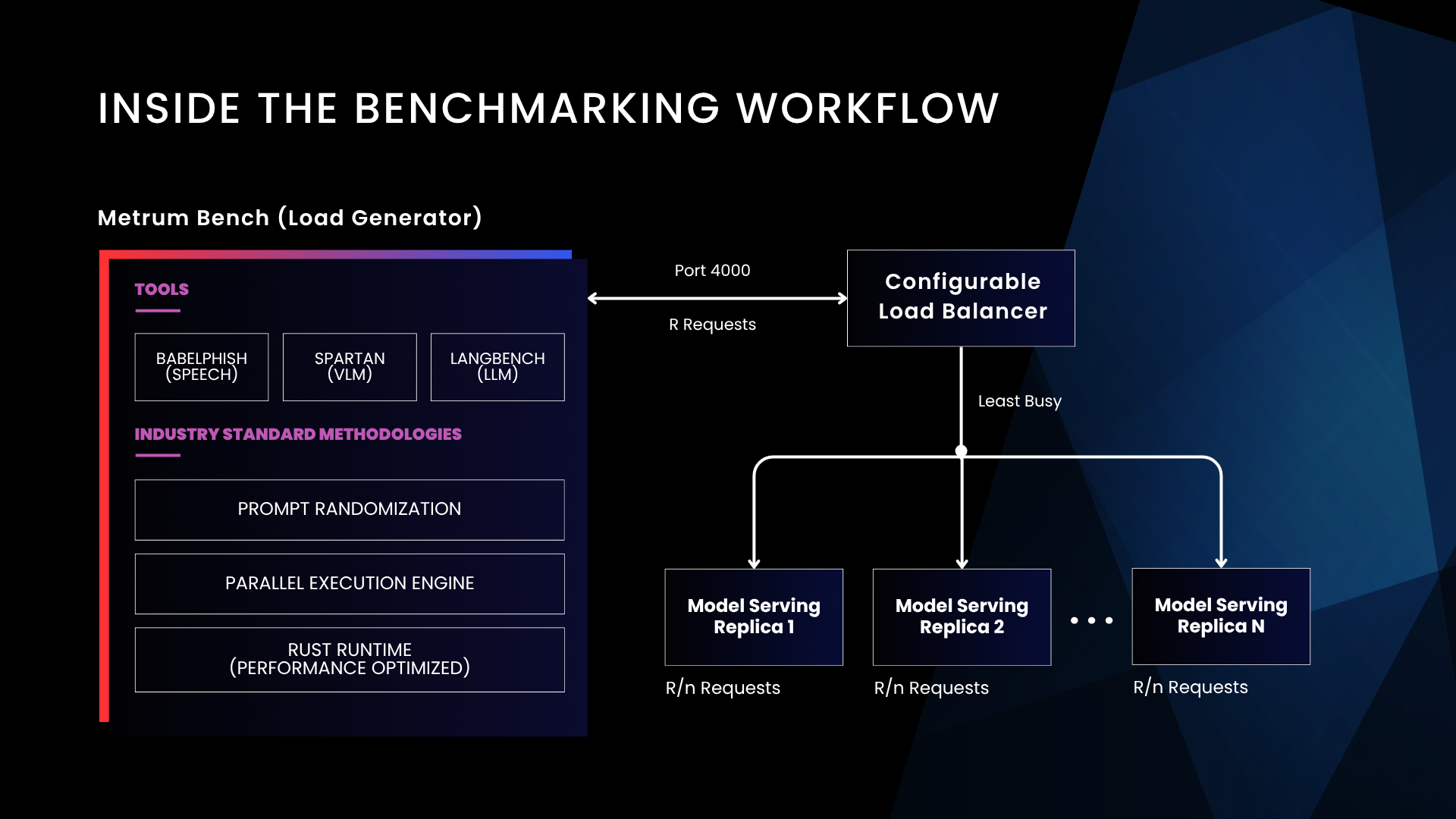
The Metrum Bench Architecture
At the heart of Metrum Insights lies Metrum Bench (Load Generator), which incorporates industry-standard tools and methodologies to ensure comprehensive testing:
Tools Integration
- Babelphish (speech) - speech processing capabilities
- Spartan (VLM) - vision-language model testing
- Langbench (LLM) - large language model benchmarking
Industry Standard Methodologies
The framework employs three critical methodologies that reflect real-world deployment scenarios:
- Prompt randomization - ensures diverse testing patterns that mirror actual user behavior
- Parallel execution engine - simulates concurrent user loads typical of production environments
- Rust runtime (performance optimized) - delivers efficient, high-performance test execution
Intelligent Load Distribution
The load generator communicates with a Load Balancer (NGINX), sending requests to be distributed across multiple model serving replicas. Using a "Least Busy" routing algorithm, the load balancer serves as the central orchestration point, routing incoming requests from the load generator across LLM serving replicas.
Each replica handles R/n requests, where R represents the total number of requests in the tested load scenario, and n represents the number of active replicas. Metrum Insights supports replica counts of 1, 2, 4, or 8, with tensor parallelism values selected dynamically to optimize throughput and latency for each specific model configuration.
This optimal tensor parallelism is determined by three key factors:
- Model Parameter Count - Larger models require more aggressive parallelization
- Inference Model Precision - Higher precision formats demand additional memory resources
- GPU Memory Capacity - Hardware constraints determine maximum parallelization levels
Summary
Metrum Insights represents a significant advancement in LLM performance benchmarking, moving beyond simple synthetic tests to provide production-realistic performance data. By combining industry-standard tools with sophisticated load distribution and configurable parallelism, organizations gain the clarity needed to confidently deploy LLMs at scale.
Start Benchmarking Today
Experience the latest version of Metrum Insights and see how easy it is to automate performance testing, compare results across hardware, and generate data-driven insights, all through a simple, no-code interface.
Copyright © 2025 Metrum AI, Inc. All Rights Reserved. All other product names are the trademarks of their respective owners.