
In this blog, Metrum AI and Dell introduce a solution architecture for multi-node training using a distributed system of Dell PowerEdge XE9680 Servers equipped with Intel Gaudi 3 Accelerators and Intel Gaudi 3 AI Accelerator NICs enabled with RoCE.
Introduction
Training large language models (LLMs) requires significant computational resources, often requiring extensive server clusters. For instance, training Meta's Llama 3 family of models demanded 24,000 NVIDIA H100 GPUs, resulting in hundreds of millions in infrastructure costs.
Distributed training streamlines this process, improving resource usage by parallelizing tasks across multiple GPUs or devices and enhancing resource utilization. However, communication overhead can become a major bottleneck. RDMA over Converged Ethernet (RoCE) boosts data transfer efficiency and cuts latency, optimizing communication between devices. This accelerates the training of large language models, making it faster and more cost-effective, allowing you to fine-tune bigger models or reduce costs for models of the same size.
In this blog, we introduce a solution architecture for multi-node training using Dell PowerEdge XE9680 servers with Intel Gaudi 3 Accelerators. This configuration can significantly reduce both time and infrastructure costs for fine-tuning state-of-the-art LLMs, a critical process for enterprises looking to customize models for specific domains.
Distributed Fine-tuning Solution Architecture
This solution utilizes Dell PowerEdge XE9680 rack servers and Intel Gaudi 3 AI accelerators with integrated NICs, which support RoCE to facilitate high-speed, low-latency communication across nodes through direct memory access over Ethernet. By bypassing the CPU, RoCE minimizes overhead and speeds up GPU to GPU data transfers, significantly improving throughput and scalability for distributed fine-tuning.
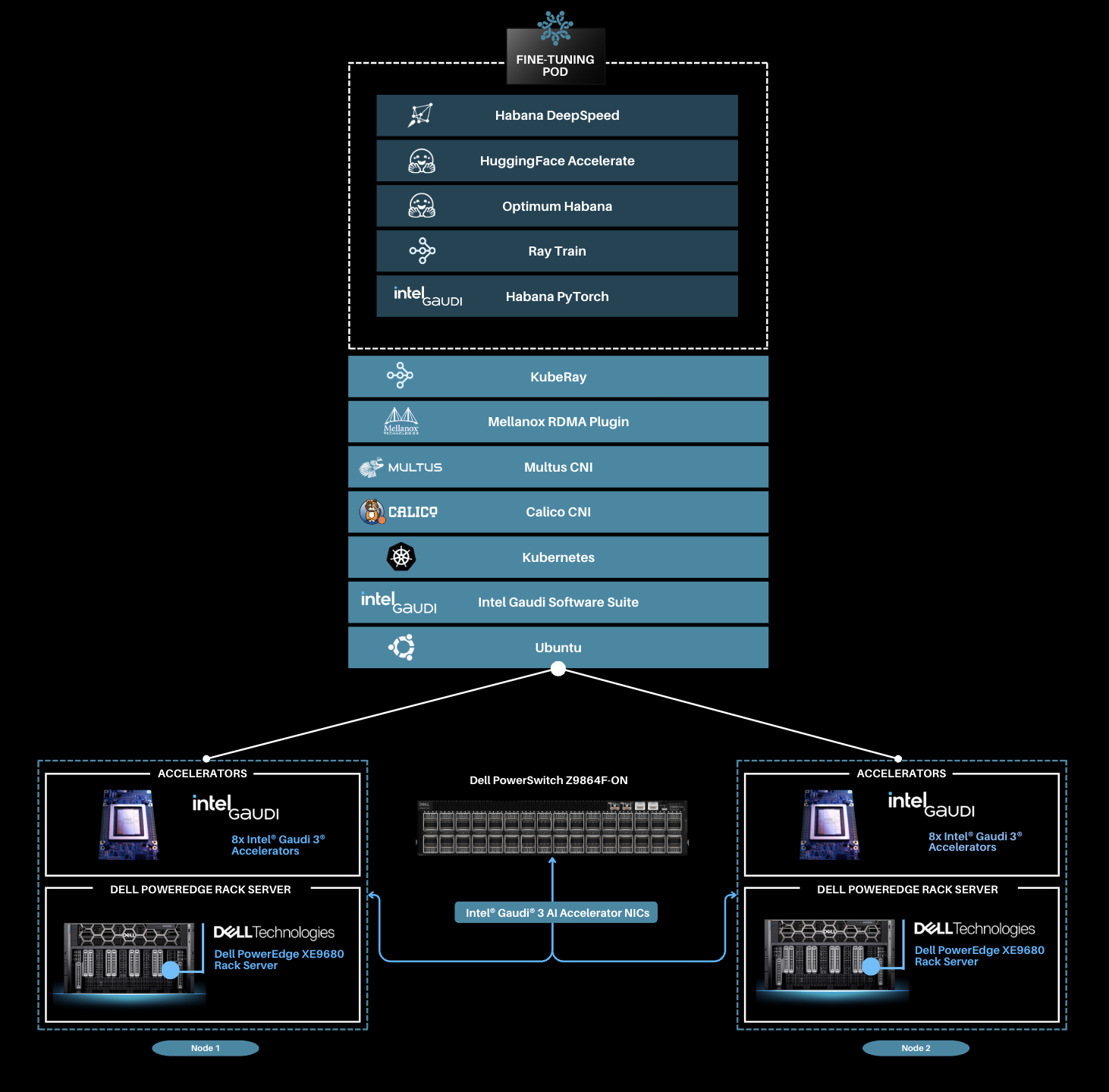
In this setup, two Dell PowerEdge servers equipped with Intel Gaudi 3 AI accelerators are linked through a Dell PowerSwitch Z9864F-ON, with each server featuring eight Intel Gaudi 3 OpenCompute Accelerator Modules (OAMs). The Dell PowerSwitch Z9864F-ON is a high-density 800GbE fixed switch designed for AI/ML fabric solutions, featuring 64 ports of 800GbE in a 2U form factor, powered by the Broadcom Tomahawk 5 chipset, which enables 51.2 Tb/second throughput (half-duplex) and supports advanced features like RoCEv2, adaptive routing, and enhanced priority-based flow control for optimal performance in AI workloads. Each OAM card on a server has a NIC port connected to three of the OSFP scale-out ports of the server, while 21 x 200 GbE are part of OAM to OAM connections, one dedicated per accelerator. The total throughput remains the same from the Intel Gaudi 3 AI platform with 8 OAM cards with 3x200GbE (4800GbE) converging to 6*800GbE (4800 GbE) with OSFP ports on the PowerEdge XE9680 server.
The following key libraries are utilized to enable distributed fine-tuning:
- KubeRay: A Kubernetes operator that acts as an orchestration framework for training on a distributed hardware system. KubeRay is responsible for setting up a Ray cluster, i.e., setting up pods on the requested machines. It then handles the pod lifecycles, which involves checking that pods are alive as well as restarting pods if they are unresponsive. The pods can be started with different Docker images, but they must be able to communicate through Ray. KubeRay also handles job submissions, and provides a dashboard displaying hardware utilization metrics for all machines currently in the cluster.
- Accelerate: Provides the distributed training capabilities to PyTorch code. Accelerate simplifies the distribution of the current PyTorch fine-tuning code across multiple nodes. The Accelerate library primarily acts as a wrapper, meaning that the configuration options you can pass to the library are actually configuration options of underlying libraries, such as DeepSpeed.
- Habana DeepSpeed: Habana DeepSpeed optimizes distributed fine-tuning on Gaudi accelerators with advanced algorithms that efficiently manage memory and computation. A key feature, ZeRO Stage 3, partitions model states across Gaudi devices, reducing memory consumption and enabling the training of larger models. It minimizes communication overhead by distributing optimizer states, gradients, and parameters among Gaudi accelerators, leading to faster convergence. Notably, with ZeRO on Gaudi systems, significant performance improvements are observed as additional accelerators are added, resulting in superlinear scaling. This efficiency stems from reduced communication bottlenecks and better utilization of Gaudi's High Bandwidth Memory (HBM), making Habana DeepSpeed an ideal solution for scaling massive models in distributed environments. Leveraging Gaudi's unique architecture and the optimized Synapse AI software stack further enhances performance by facilitating efficient handling of large model states and rapid inter-Gaudi communication, which is crucial for the distributed training of large language models.
This solution integrates additional AI libraries and drivers including Kubernetes, Intel Gaudi Software Suite and PyTorch. To enhance network performance for distributed fine-tuning in Kubernetes environments, we utilized both Multus CNI and Mellanox RDMA Plugins.
Summary
The Dell PowerEdge XE9680 Server, featuring Intel Gaudi 3 Accelerators, offers enterprises cutting-edge infrastructure for fine-tuning AI solutions tailored to industry-specific needs using their proprietary data, as well as for developing pretrained models. In this blog, we showcased a comprehensive multi-node training solution architecture, enabling enterprises to accelerate training and fine-tuning by utilizing multi-node hardware clusters with RoCE.
References
Dell images: Dell.com
Intel images: Intel.com
https://blogs.nvidia.com/blog/meta-llama3-inference-acceleration/
Copyright © 2024 Metrum AI, Inc. All Rights Reserved. This project was commissioned by Dell Technologies. Dell and other trademarks are trademarks of Dell Inc. or its subsidiaries. Intel, Intel Gaudi 3 and combinations thereof are trademarks of Intel, Inc. All other product names are the trademarks of their respective owners.
DISCLAIMER - Performance varies by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance.