
In this blog, Metrum AI and Dell present fine-tuning performance results using a distributed system of two Dell PowerEdge XE9680 Servers equipped with Nvidia H200 Tensor Core GPUs and high-performance Broadcom networking enabled with RoCE.
Introduction
In our previous blog, Metrum AI introduced a high-performance multi-node training architecture utilizing Dell PowerEdge XE9680 servers with Nvidia H200 Tensor Core GPUs, optimized with RoCE (RDMA over Converged Ethernet). This architecture aims to minimize network bottlenecks and improve the efficiency of distributed fine-tuning for large language models (LLMs). In this blog, we leverage this architecture and present performance benchmarks that demonstrate the tangible benefits of this setup.
Our results clearly illustrate the advantages of RoCE on fine-tuning performance with two Dell PowerEdge XE9680 servers equipped with Nvidia H200 Tensor Core GPUs:
| Model | With RoCE (Train Time in Minutes Per Epoch) |
|---|---|
| Llama 3.1 8B, BF16 | 15 |
| Llama 3.1 70B, BF16 | 82 |
Benchmarking Methodology
To evaluate the effectiveness of RoCE-enabled multi-node training, we conducted fine-tuning experiments on two Llama 3.1 models of different scales. These models were selected because they are current, leading open-weight models, well-positioned for enterprise fine-tuning due to their performance, quality, and commercially friendly licensing:
We use the pubmed_qa, pqa-artificial dataset for fine-tuning these models. This dataset was selected to represent a domain-specific dataset that reflects enterprise fine-tuning workloads. Batch size was selected to utilize more than 90% of GPU memory during fine-tuning, and all fine-tuning was performed with BF16 precision. Each model was fine-tuned for three epochs, and the final time taken for fine-tuning for one epoch was calculated by averaging times over the three measured epochs. This methodology focuses solely on the time required for training, excluding model loading, checkpointing, and evaluation.
Our testbed consisted of two Dell PowerEdge XE9680 servers each equipped with 8x Nvidia H200 GPUs, interconnected using Broadcom Thor 2 NICs with RoCE support. Broadcom Thor 2 NICs, with fast ethernet and advanced RoCE v2 RDMA capabilities, deliver low-latency, energy-efficient, and scalable performance, making them ideal for accelerating distributed AI fine-tuning workloads. The network backbone included a Dell PowerSwitch Z9864F-ON, an 800GbE high-density switch designed for AI workloads.
We leveraged two multi-node-training architectures comprising industry-standard software components. First, we tested the architecture we introduced in our previous blog, consisting of Nvidia NeMo for fine-tuning workflows, SkyPilot for orchestration, and Kubernetes with the Mellanox RDMA plugin for optimized GPU-to-GPU communication, as shown in the architecture diagram below. We made one change from the Calico CNI to the Flannel CNI, which is ideal for users seeking straightforward networking solutions for small to medium Kubernetes clusters without complex network policies. We also tested a second multi-node training architecture consisting of DeepSpeed, Hugging Face Accelerate, and Ray Train, also using the Flannel CNI, to get a broader picture of fine-tuning performance gains with RoCE enabled.
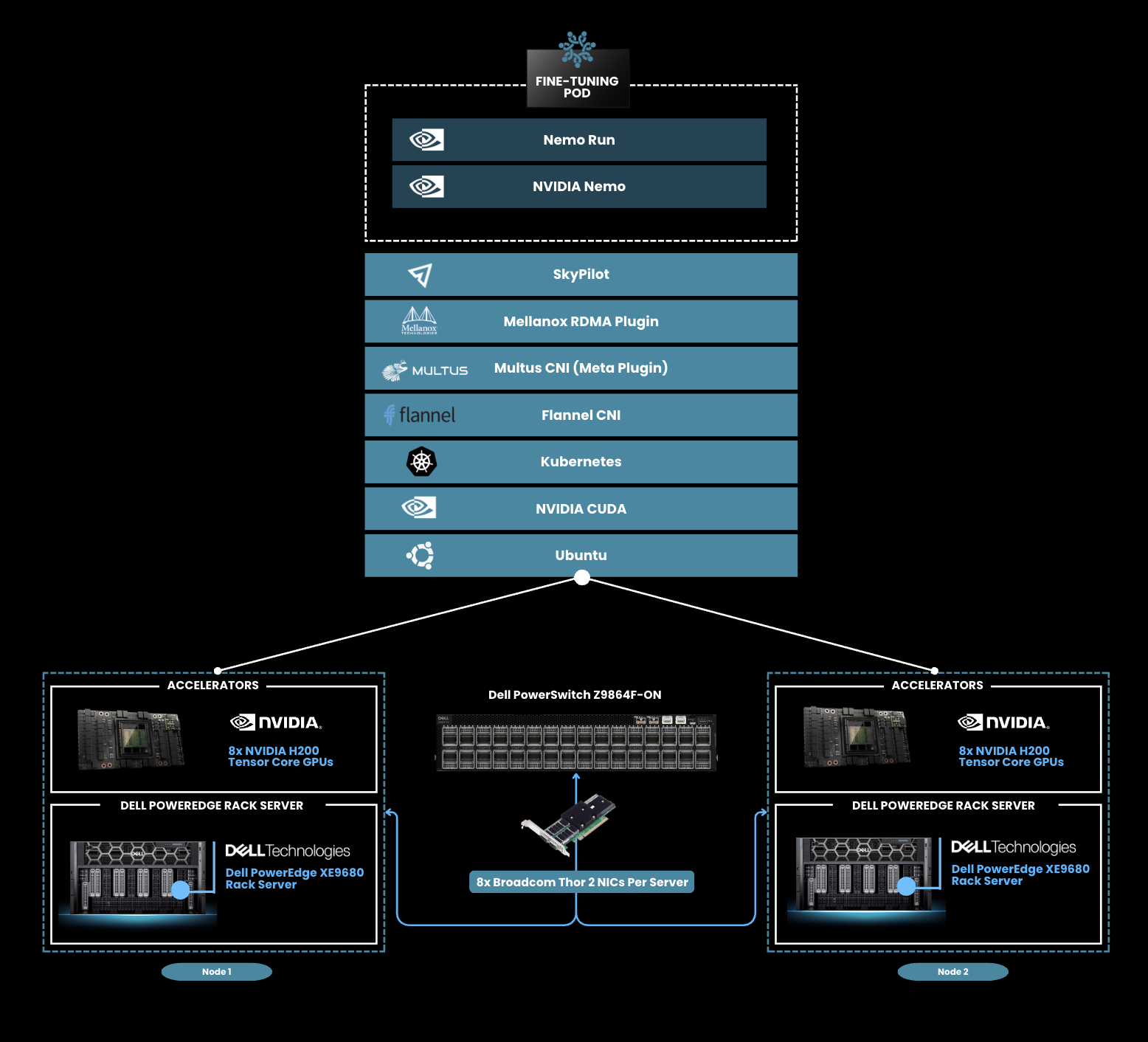
Figure 1. NVIDIA NeMo-Based Multi-Node Training Architecture with Dell PowerEdge XE9680 fully populated with 8 NVIDIA H200 Tensor Core GPUs, using 8x Broadcom Thor 2 NICS per server with RoCE.
Performance Results for Nvidia NeMo-Based Multi-Node Training Architecture
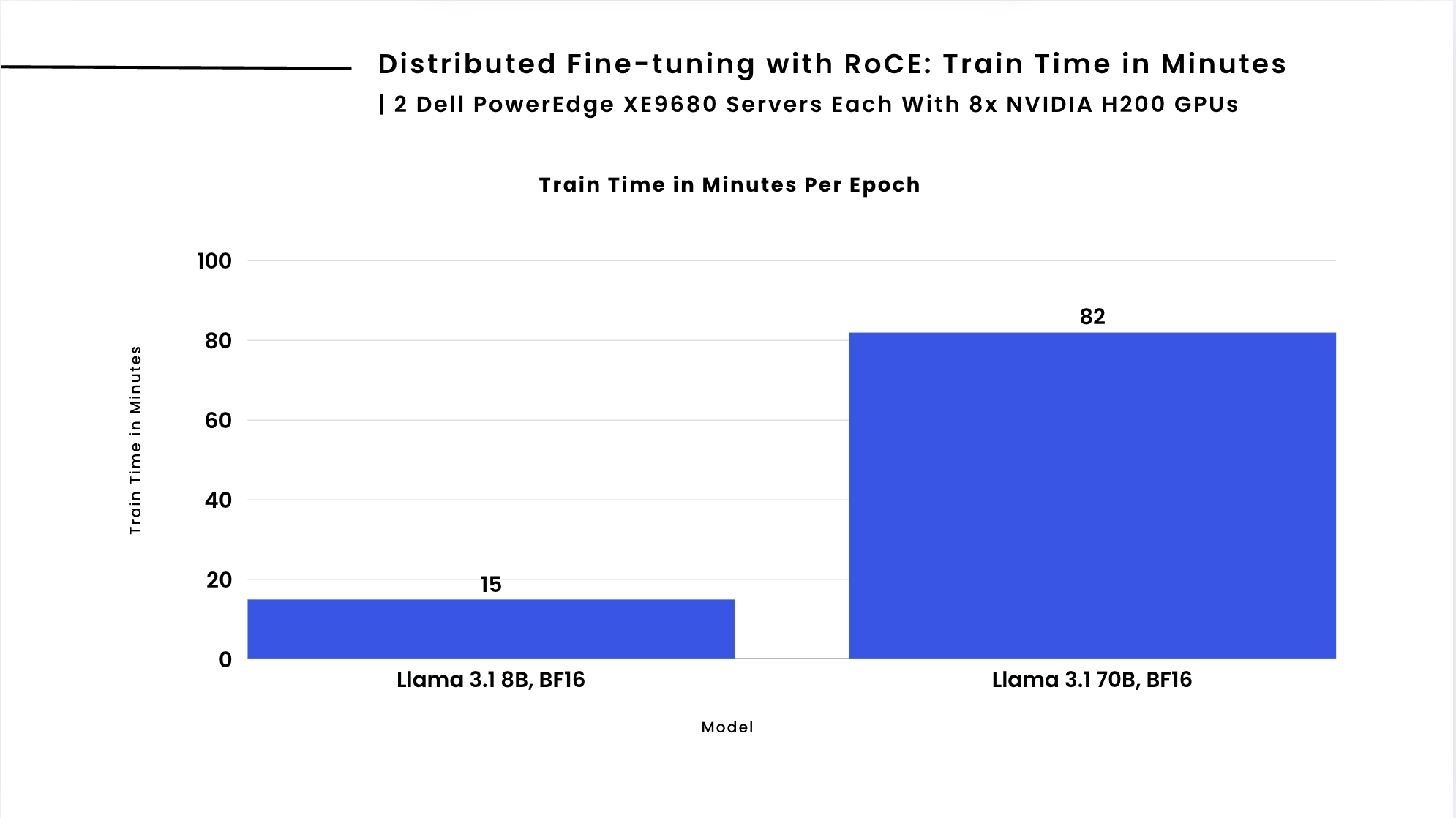
Figure 2. Performance results for distributed fine-tuning with RoCE on Llama 3.1 8B with BF16 Precision, and Llama 3.1 70B with BF16 Precision. Measuring train time in minutes.
As seen in the chart above, RoCE enables fine-tuning of large large language models in 82 minutes, delivering a significant speedup for larger language models such as Llama 3.1 70B. The performance gains stem from improved direct GPU-to-GPU communication, reducing network overhead and ensuring efficient data exchange across nodes.
Key Observations
- Scaling Efficiency: The performance boost is more pronounced in larger models (70B), where training time is much higher without RoCE due to communication overhead becoming a bottleneck. RoCE mitigates this, enabling significantly faster convergence.
- Lower Latency: By leveraging direct memory access over Ethernet, RoCE eliminates unnecessary CPU processing, reducing end-to-end communication latency.
- Infrastructure Cost Savings: Faster fine-tuning means reduced compute hours, translating into lower operational costs, especially for enterprises running multiple training cycles.
Performance Results for DeepSpeed-Ray-Based Multi-Node Training Architecture
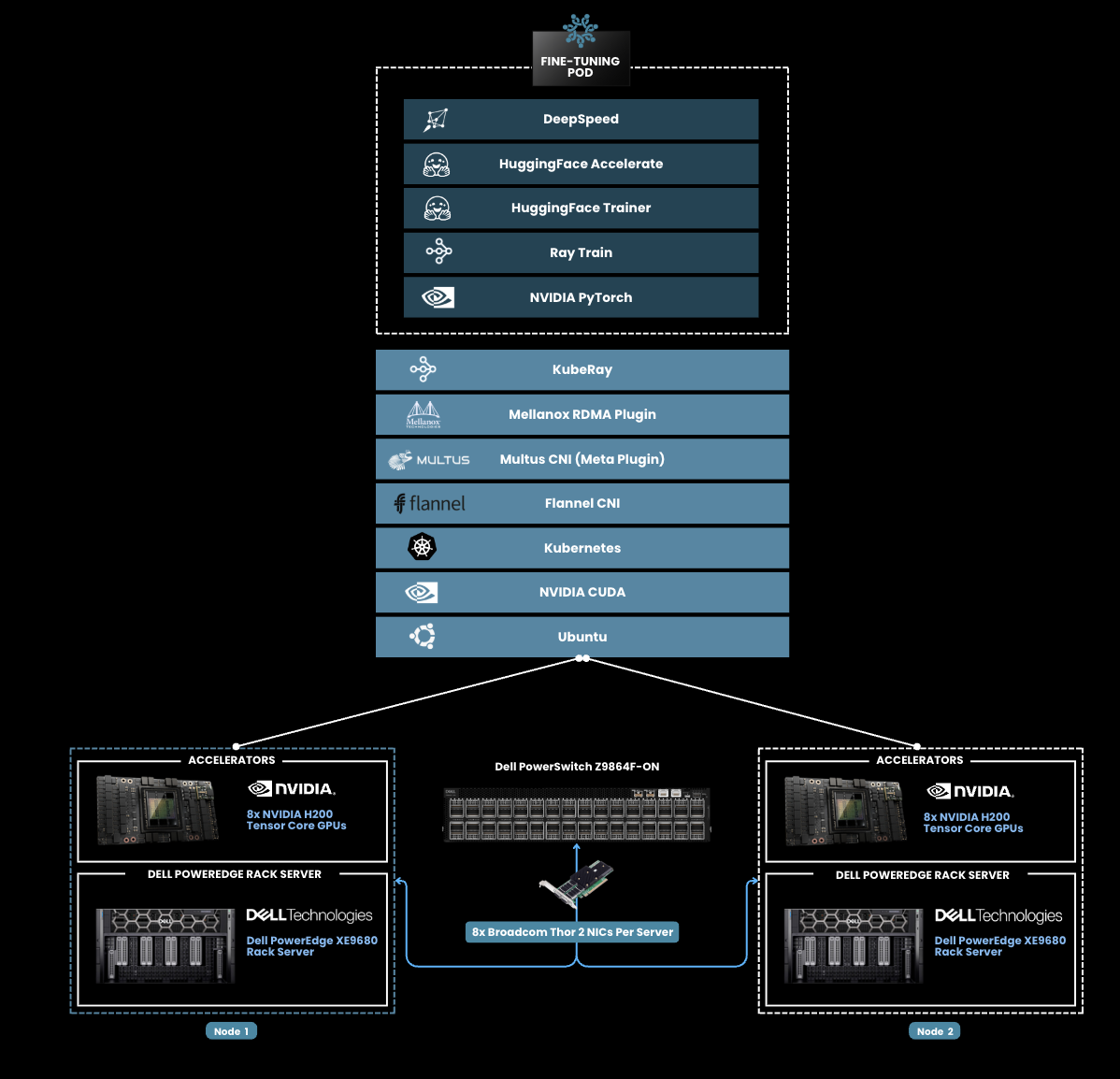
Figure 3. DeepSpeed-Ray-Based Multi-Node Training Architecture with Dell PowerEdge XE9680 fully populated with 8 NVIDIA H200 Tensor Core GPUs, using 8x Broadcom Thor 2 NICS per server with RoCE.
When testing with the second architecture shown above, we achieved similar results, measuring 14 minutes of train time on Llama 3.1 8B with RoCE enabled.
Conclusion
Our benchmarks confirm that RoCE significantly accelerates distributed fine-tuning of LLMs. By integrating Nvidia H200 GPUs with high-bandwidth networking, enterprises can train models faster, optimize resource utilization, and lower total compute costs.
This is particularly valuable for organizations fine-tuning proprietary LLMs on domain-specific data, as it allows for rapid iteration cycles and faster deployment of AI-driven applications. As AI models continue to scale, leveraging advanced networking technologies like RoCE will be crucial for maintaining performance efficiency in distributed training environments.
For further details on implementation or to explore how this hardware combination can fit your enterprise AI strategy, reach out to Metrum AI at contact@metrum.ai.
Hardware Configuration
| Server | Dell PowerEdge XE9680 (2 Servers Total) |
|---|---|
| Accelerators | 8x NVIDIA H200 Tensor Core GPUs |
| CPU | 2x Intel Xeon Platinum 8568Y+ |
| Memory | 2 TB |
| Accelerators Count | 8 |
| OS | Ubuntu 22.04.5 LTS |
| Embedded NIC | Broadcom Gigabit Ethernet BCM5720 |
| RoCE NICs | 8x Broadcom BCM57608 2x200G PCIe (Thor 2) - 1 Per GPU |
| Ethernet Switch | Dell PowerSwitch Z9864F-ON with Enterprise SONiC Distribution by Dell Technologies |
References
Image Sources
Dell images: Dell.com
NVIDIA images: nvidia.com
Broadcom images: broadcom.com
Copyright © 2025 Metrum AI, Inc. All Rights Reserved. This project was commissioned by Dell Technologies. Dell and other trademarks are trademarks of Dell Inc. or its subsidiaries. NVIDIA and combinations thereof are trademarks of NVIDIA Corporation. All other product names are the trademarks of their respective owners.
DISCLAIMER - Performance varies by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance.