
Introduction
AI agents are revolutionizing task automation and productivity across industries. At Metrum AI, we specialize in developing industry-specific AI agents tailored for real-world applications. To deliver on this innovation we continuously assess the latest hardware advancements to ensure optimal performance and total cost of ownership. This optimization is powered by Metrum Insights, our advanced benchmarking platform that tests cutting-edge AI models on next-generation hardware.
Metrum AI received access to the Dell PowerEdge XE7745 server with NVIDIA H200 Tensor Core GPUs to conduct comprehensive performance evaluations for AI agent development and enterprise deployment. Previously, we developed on the Dell PowerEdge R760xa server. To compare gains we put both systems to the test by deploying industry-leading large language models (LLMs) in real-world AI scenarios.
Today, our AI agents run on vLLM, an industry-leading open-source library that makes deploying large language models more efficient by addressing memory management challenges that typically come with real-world LLM applications. For additional performance optimization, we also tested NVIDIA NIM, a set of easy-to-use microservices which automatically configure workloads for optimal performance on NVIDIA hardware.
Metrum Insights, our performance evaluation tool for real-world AI workloads, automated critical steps of the end-to-end AI benchmarking pipeline, from server provisioning to validating performance results. Further, to gain real-world insights, Metrum Insights enabled prompt randomization and concurrency simulation to thousands of concurrent requests. By leveraging Metrum Insights, we reduced our evaluation time by >90%.
Key Findings
When comparing the Dell PowerEdge XE7745 with 8x NVIDIA H200 NVL against the Dell PowerEdge R760xa with 4x NVIDIA H100PCIe, we found significant throughput performance improvements, especially when handling multiple concurrent requests. Here are the performance highlights for XE7745 on the following model deployment scenarios:

Why Throughput and Concurrency Levels Matter for AI Performance
In our benchmarks, we measure output token throughput, measured in tokens per second - a critical performance metric for AI inference. Higher throughput means a model can generate more text per second, improving response times and overall efficiency. In real-world AI applications, throughput directly impacts scalability and cost efficiency. Maintaining high throughput performance across varying concurrency levels is a key differentiator for production-grade AI applications.
Understanding Throughput Across Concurrency Levels
Different AI use cases demand different levels of concurrent requests, a proxy for the number of concurrent active users. Here's how concurrency impacts real-world workloads:
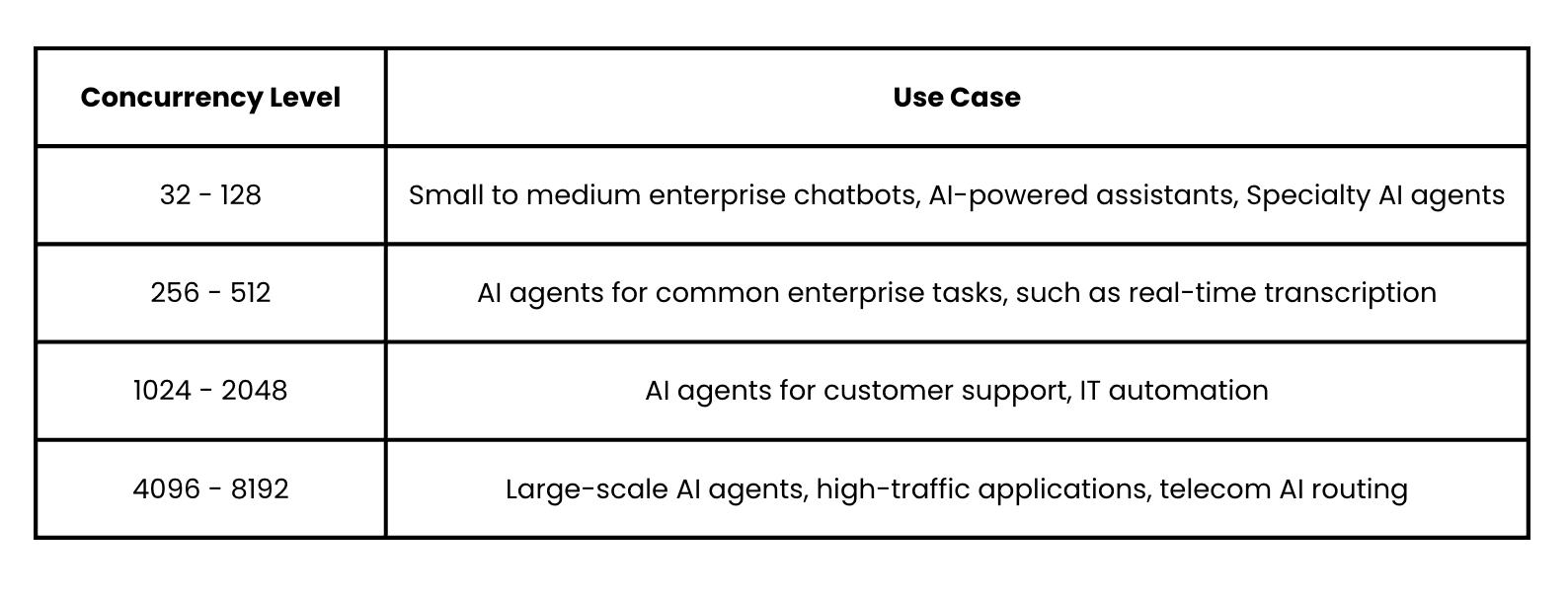
As AI adoption accelerates, businesses need hardware that delivers consistently high throughput across these varying concurrency levels. The Dell PowerEdge XE7745 server's 5x performance improvement offers a key advantage here, enabling enterprises to handle more concurrent users and requests while seamlessly running high-demand applications. This capability is essential for both batch-based AI applications such as industry-specific AI agents and real-time applications like private, on-premise chatbots.
Our Methodology
To test how well these servers perform on real-world AI workloads with varying concurrent user requirements, we leveraged Metrum Insights to deploy Llama 3.3 70B across concurrency levels: 32, 64, 128 ... 8192.
For each benchmarking scenario, we used the following configurations:
- Randomized Prompts:
- Average Input Token Length: 128
- Output Token Length: 128
- Tensor Parallelism: 2
- Number of Model Replicas: 4 (total number of replicas deployed on entire system)
- Metrics:
- Output token throughput (measured in tokens per second)
- Maximum concurrent requests supported at minimum throughput of 10 tokens per second (measured in number of concurrent requests)
Throughput Performance Results: Dell PowerEdge XE7745 vs. R760xa Server
Using Metrum Insights, we conducted an initial evaluation of Llama 3.3 70B Instruct, an industry-leading open-weight LLM, deployed on both Dell PowerEdge XE7745 (8x H200 NVL) and R760xa (4xH100 PCIe). We measured output token throughput (OTT) across varying concurrency levels. The results below illustrate the total output token throughput (OTT) for the entire system under testing.
Llama 3.3 70B Performance with vLLM
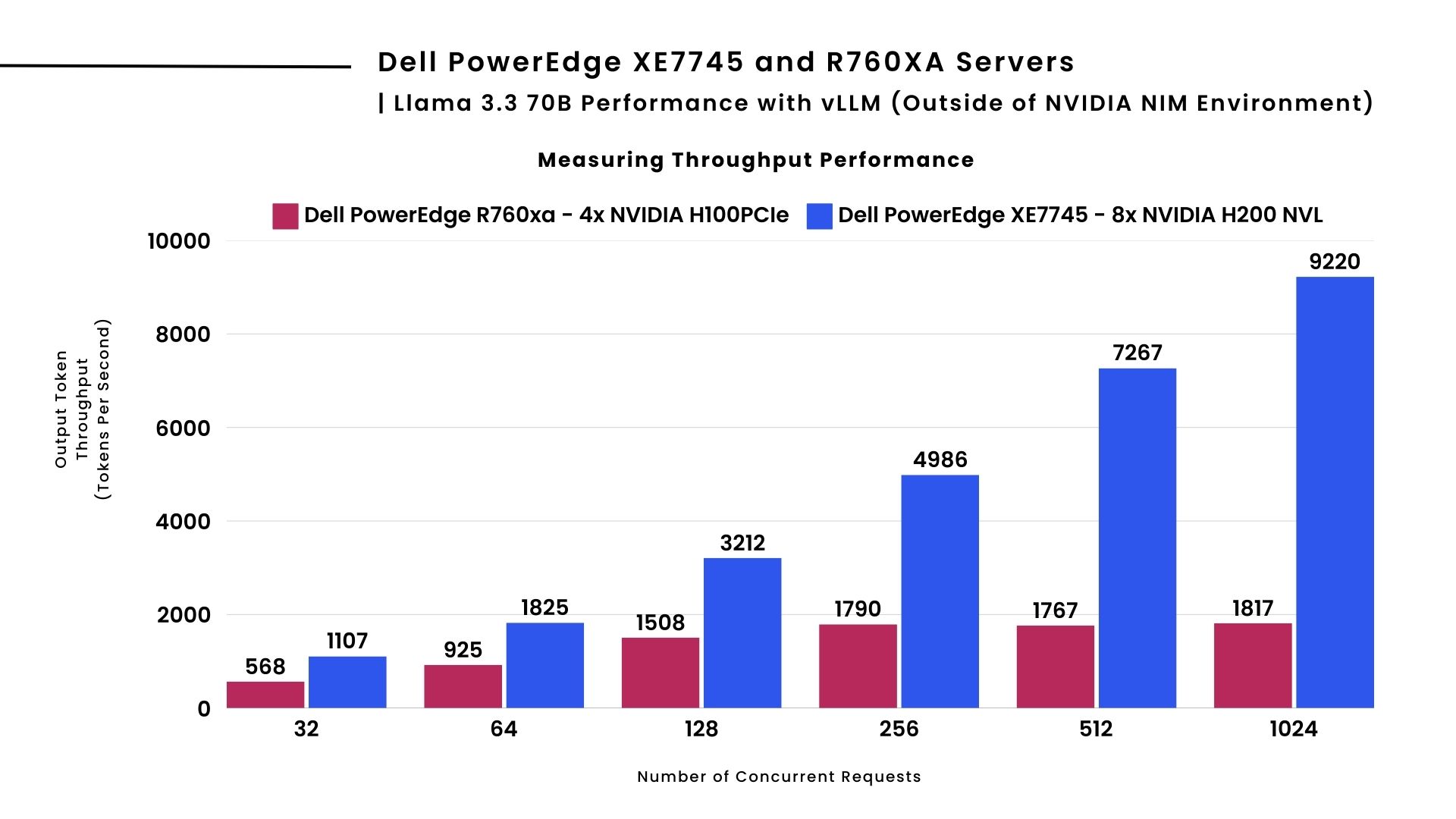
When deploying Llama 3.3 70B with vLLM, the Dell PowerEdge XE7745 outperforms R760xa, delivering approximately 5x improvement in throughput at high concurrency levels. The benchmark comparison highlights the superior capabilities of the XE7745 equipped with 8x NVIDIA H200 NVL GPUs compared to the R760xa with 4x H100 PCIe GPUs, with a performance advantage due to a doubling in number of GPUs as well enhanced memory bandwidth and GPU architecture in NVIDIA H200 NVL. As shown above, the Dell PowerEdge R760xa server performance tapers around 256 concurrent requests, whereas the Dell PowerEdge XE7745 server performance increases, sustaining up to 9220 tokens per second at 1024 concurrent requests.
Llama 3.3 70B Performance with NVIDIA NIM
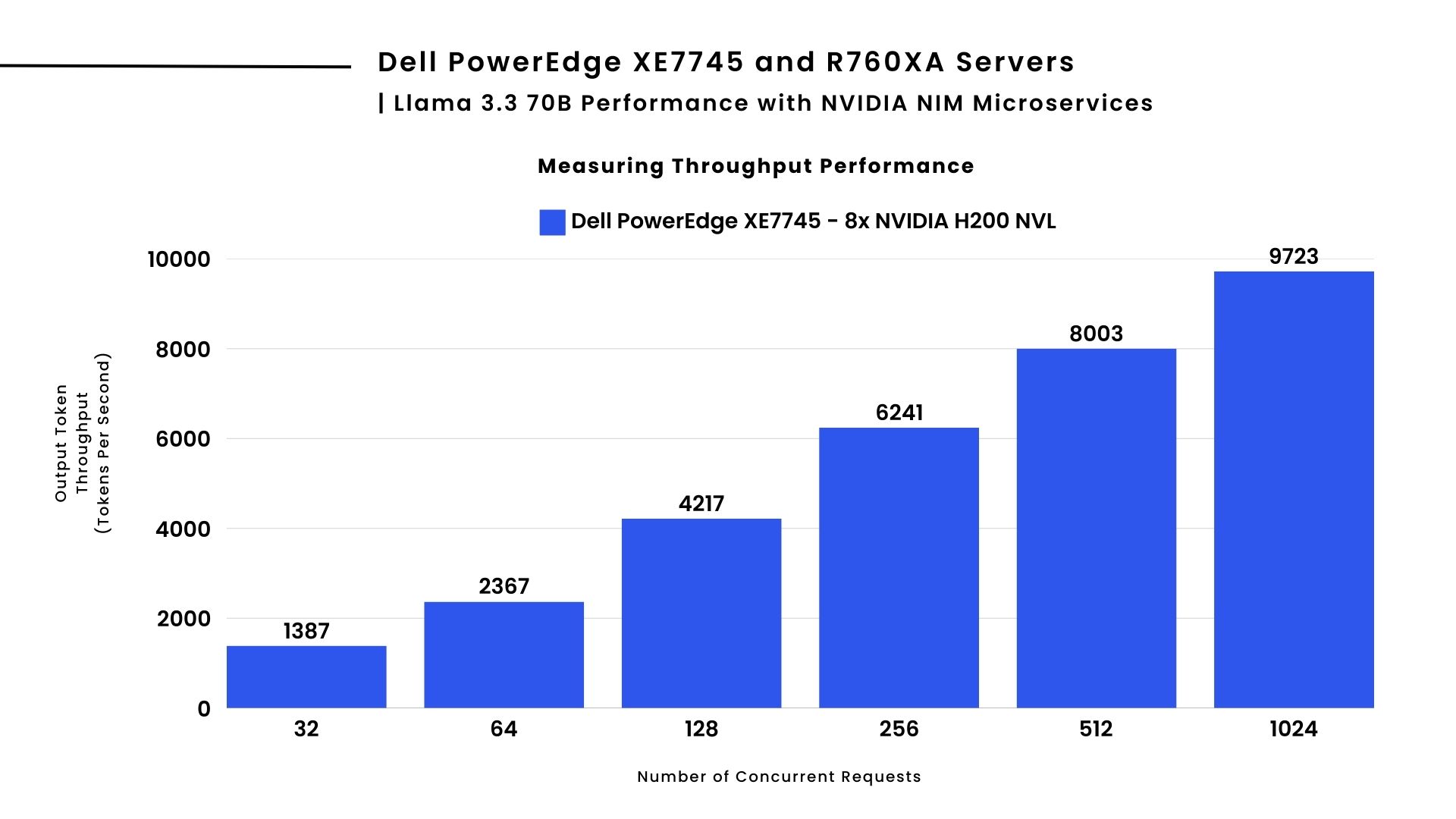
For the larger Llama 3.3 70B model, the Dell PowerEdge XE7745 delivers approximately 5% improvement in throughput at high concurrency levels when deployed with NVIDIA NIM microservices over vLLM. As shown above, the Dell PowerEdge XE7745 server scales efficiently, sustaining over 9700 tokens per second at 1024 concurrent requests.
Simulating Maximum Concurrent Requests Supported
Now that we've analyzed output token throughput, it's worth considering real-world requirements. Interactive applications like chatbots typically need to meet an industry standard of 10 tokens per second per user to feel responsive. Using Metrum Insights, we measured how many concurrent requests each of our deployment scenarios could support while maintaining this minimum threshold.
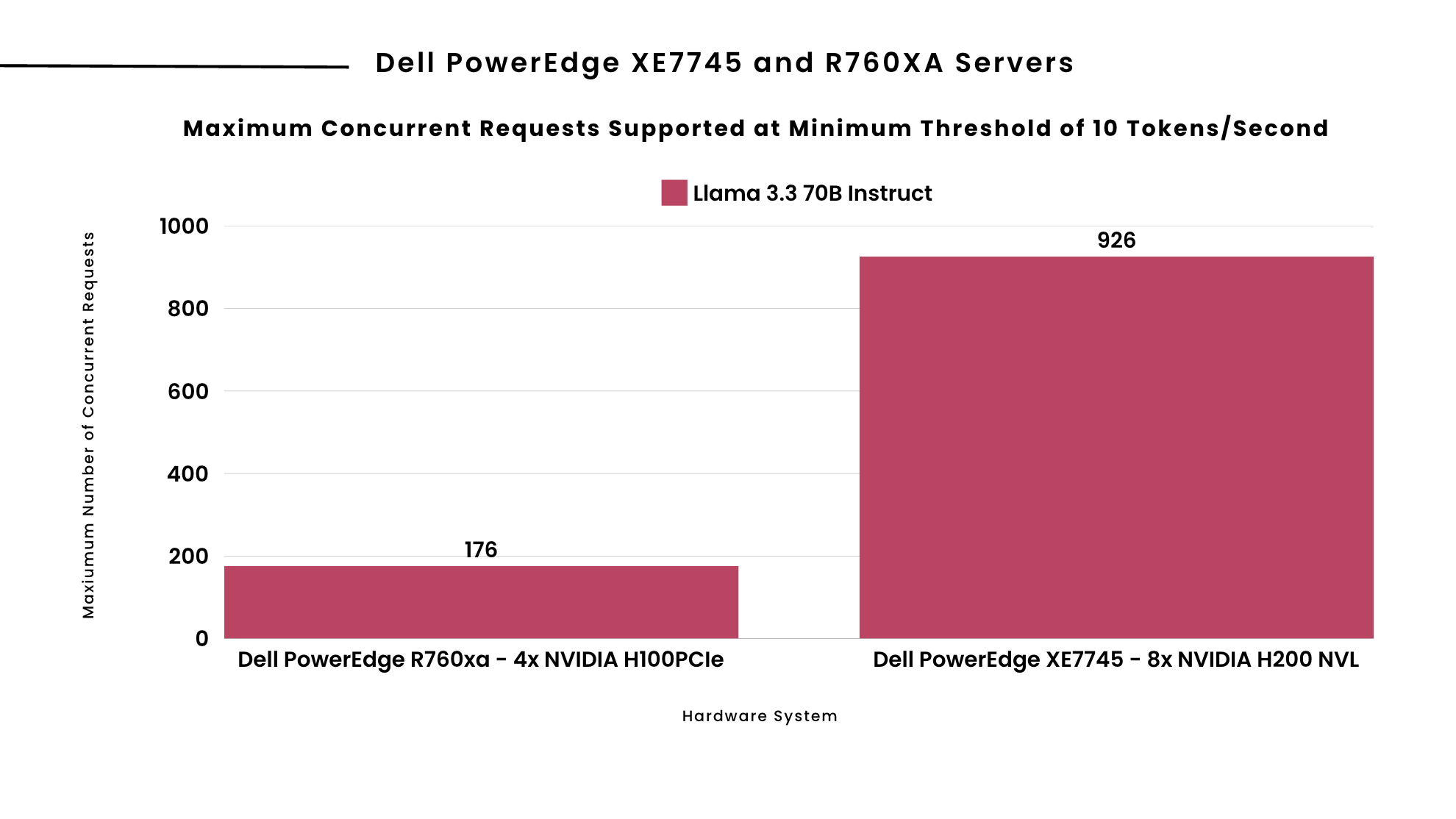
As shown above, we can see the maximum number of concurrent requests each server can support while maintaining the minimum threshold of 10 tokens per second per user. These results show a dramatic performance difference between the two server configurations, with Dell PowerEdge XE7745 with 8x NVIDIA H200 NVL GPUs outperforming the older R760xa system with 4x H100 PCIe GPUs. The massive improvement for the largest model (Llama 3.3 70B), which jumps from supporting 176 requests to 982 requests, suggests that the H200 GPUs provide especially significant benefits for larger, more memory-intensive models.
Summary
The Dell PowerEdge XE7745 server with NVIDIA H200 Tensor Core GPUs delivers exceptional performance gains for enterprise applications. We used Metrum insights to conduct comprehensive performance tests, discovering significant gen-on-gen improvements when deploying large language models:
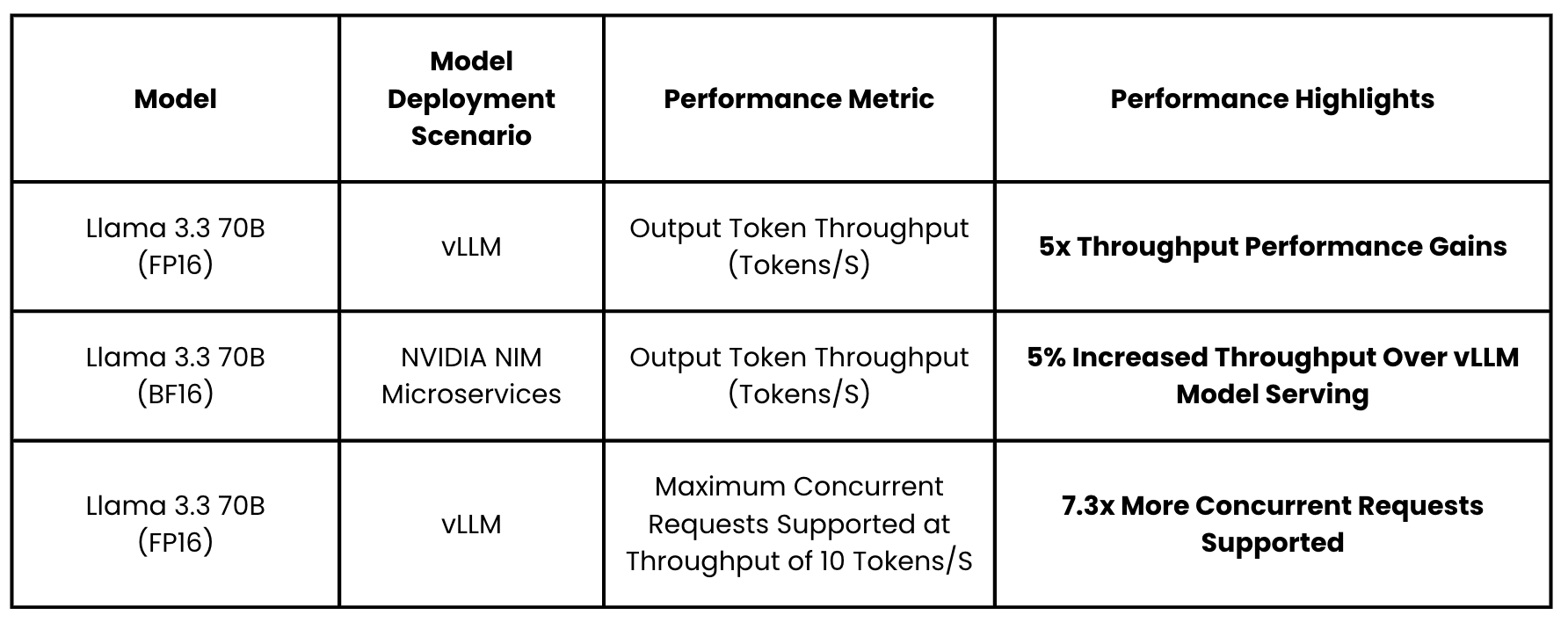
- Llama 3.3 70B (FP16) with vLLM achieves 5x throughput performance gains
- When serving Llama 3.3 70B (BF16) using NVIDIA NIM microservices, throughput increases by an additional 5% over vLLM model serving
- The XE7745 supports 7.3x more concurrent requests when running Llama 3.3 70B (FP16) with vLLM at a throughput of 10 tokens/second
These substantial performance improvements translate directly to lower cost-per-token and higher concurrent user capacity, significantly reducing TCO and enabling more responsive AI applications.
For enterprises serious about deploying production-grade AI at scale, the Dell PowerEdge XE7745 with NVIDIA H200 GPUs provides the performance headroom and efficiency needed to support growing AI workloads and user demands. By leveraging both vLLM and NVIDIA NIM deployment options, organizations can optimize their LLM infrastructure for their specific use cases.
Server Configuration
| Server Model | GPU | GPU Count | CPU |
|---|---|---|---|
| Dell PowerEdge XE7745 | NVIDIA H200 NVL | 8 | AMD EPYC 9965 192-Core Processor |
| Dell PowerEdge R760xa | NVIDIA H100 PCIe | 4 | Intel(R) Xeon(R) Platinum 8480+ |
References
Dell images: Dell.com
Copyright © 2025 Metrum AI, Inc. All Rights Reserved. This project was commissioned by Dell Technologies. Dell and other trademarks are trademarks of Dell Inc. or its subsidiaries. NVIDIA, NVIDIA H100 and NVIDIA H200, and combinations thereof are trademarks of NVIDIA. All other product names are the trademarks of their respective owners.
DISCLAIMER - Performance varies by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance.