KV Cache Offload on Solidigm™ D7-PS1010 NVMe SSDs with NVIDIA Dynamo
March 2026

Executive Summary
AI inference at scale wastes up to 40% of GPU compute on work the system has already done. Every time the KV cache is evicted from GPU memory, the system burns 20 to 40 seconds of compute and peak power to rebuild the context it already generated. Solidigm D7-PS1010 NVMe SSDs, integrated with the NVIDIA® Dynamo inference runtime, eliminate this penalty by persisting KV cache tensors on high-performance PCIe 5.0 storage and reloading them on demand.
Live Demo Results

The Hidden Tax on AI Inference
Redundant GPU recomputation costs organizations in hardware spend, energy, and response time. Every large language model builds an attention state called the KV cache as it processes input context. This structure tracks relationships between tokens and must remain accessible throughout the session. For a 200,000-token context, a single KV cache can consume the majority of available GPU VRAM.
When GPU memory fills up, the system evicts older caches to make room. The next time any user returns to that context, the GPU recomputes the entire attention state from scratch. That recomputation takes 20 to 40 seconds of pure compute, burning power and blocking the pipeline for work the system already completed.
Under concurrent load, this compounds. Every returning user triggers a full re-prefill. The GPU queues up. Time to first token climbs. Throughput drops. Power draw stays at maximum. For organizations running multi-user inference at scale, redundant recomputation is not an edge case. It is the default operating condition, and it carries a direct cost in GPUs, energy, and user experience.

Figure 1 | AI Inference Memory Hierarchy: Latency, Cost, and Capacity by Tier
Memory pricing reflects approximate market ranges as of Q1 2026. GPU VRAM (~$50-80/GB): estimated from NVIDIA RTX PRO 6000 Blackwell Server Edition accelerator card pricing divided by 96 GB GDDR7 memory capacity [1][2]. CPU DRAM (~$5-8/GB): based on DDR5-4800 RDIMM server module contract pricing as reported by Counterpoint Research [3][4]. NVMe SSD (~$0.08-0.12/GB): based on Solidigm D7-PS1010 (15.36 TB, PCIe 5.0, TLC) enterprise volume pricing [5][6]. Latency figures represent typical access times for each tier under inference workloads.
The Fix: Persist the Work, Skip the Recompute
KV cache data does not need to live exclusively in GPU VRAM. By extending the memory hierarchy to include NVMe SSD storage, inference systems can persist computed KV tensors instead of discarding them. When the same context is needed again, the system reloads cached blocks from SSD in seconds rather than recomputing them on the GPU.
Metrum AI validated this approach using Solidigm D7-PS1010 NVMe SSDs as a persistent KV cache tier. In early testing, time to first token for returning contexts improved by more than an order of magnitude, while first-time document processing performed identically to GPU-only configurations, confirming zero overhead for new content.
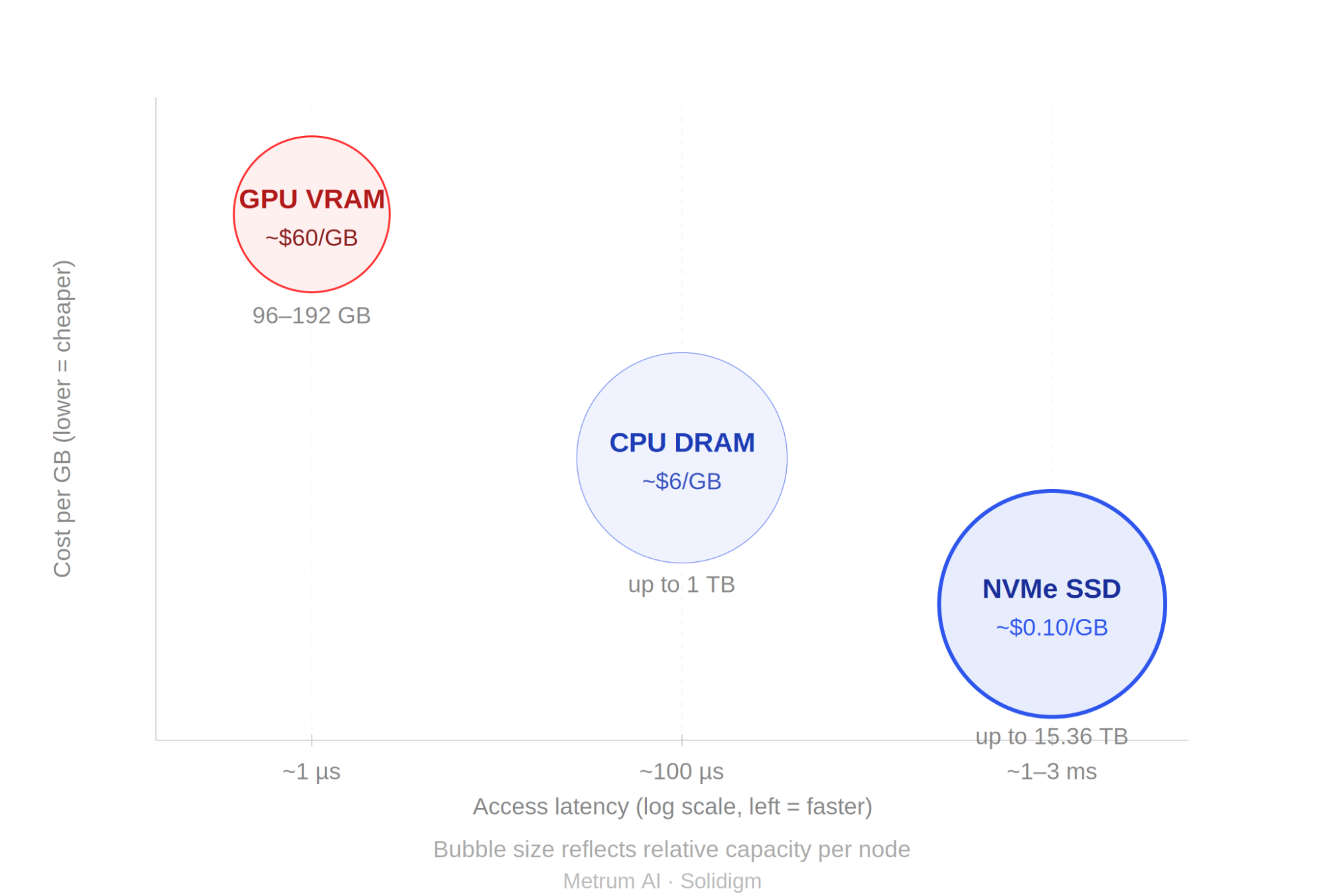
Figure 2 | Memory Tier Comparison: Cost per GB vs. Access Latency and Available Capacity
Bubble size reflects relative per-node capacity: GPU VRAM at 96-192 GB, CPU DRAM at up to 1 TB, NVMe SSD at up to 15.36 TB per drive. Cost per GB: GPU VRAM ~$60/GB estimated from accelerator card pricing [1][2]; CPU DRAM ~$6/GB based on DDR5 RDIMM server module pricing [3][4]; NVMe SSD ~$0.10/GB based on Solidigm D7-PS1010 enterprise volume pricing [5][6]. Access latency ranges represent typical inference workload conditions. All pricing as of Q1 2026.
The Use Case: Why Sports Analytics Breaks Traditional Inference
Long-context, multi-session, multi-user inference is a pattern that spans industries. Legal teams query millions of pages of discovery documents. Financial compliance analysts search years of transaction records. Medical professionals cross-reference patient histories against clinical literature. In every case, users query large, previously analyzed document sets and expect answers in seconds. The underlying infrastructure challenge is the same: context volumes exceed GPU VRAM, sessions overlap, and every cache eviction triggers costly recomputation.
To demonstrate KV cache offload under realistic conditions, Solidigm and Metrum AI chose professional football game analysis, a workload that exposes every limitation of GPU-only inference architectures.
Today, the coaching staff spend hours watching raw game footage frame by frame. Each position coach reviews films independently. The offensive coordinator sees one thing, the quarterback coach sees another. Insights stay siloed, and no one sees the full picture.
Subtle tendencies go unnoticed: a formation tendency on third down that appears only twice across a season, a coverage rotation that only surfaces in the aggregate. During game week, coaches cannot query an entire season of footage and get an answer grounded in every play. They rely on memory, partial notes, and manually compiled spreadsheets. The knowledge exists across hundreds of hours of film, but there is no way to search it, question it, or synthesize it on demand.
This problem maps directly to the inference challenge. Querying a full season of analyzed game footage means loading hundreds of thousands of tokens of context into an LLM. That volume exceeds GPU VRAM. In a standard architecture, every context switch forces recomputation, and every concurrent user multiplies the penalty. The use case is not hypothetical. It is a production workload that requires exactly the kind of long-context, multi-session, multi-user inference that KV cache offload is designed to serve.
Production-Grade KV Cache Offload with NVIDIA Dynamo
Those initial results proved the concept. The current architecture, built on the NVIDIA Dynamo inference runtime, advances KV cache offload from a research finding into a production-integrated capability.
The architecture advances KV cache offload across four layers of the inference stack.
First, the runtime integrates KV cache offload natively within Dynamo's scheduling layer, not as an external add-on. The system routes each query to the GPU worker that already holds the relevant KV blocks, minimizing unnecessary data movement across the node.
Second, a cache-aware disaggregated router tracks whether each KV block is hot in GPU memory, warm in CPU DRAM, or cold on SSD. Every incoming request lands on the optimal data path without manual placement logic.
Third, a GPU Direct Storage path enables NVMe-to-GPU transfers via GDS, bypassing the CPU entirely. This reduces transfer latency and frees CPU cycles for other work under high concurrency.
Fourth, the architecture scales to concurrent workloads where dozens to hundreds of users compete for GPU resources simultaneously. The SSD serves cached KV blocks to every user session without triggering recomputation on the GPU.
The hardware foundation remains the Solidigm D7-PS1010, a PCIe 5.0 NVMe SSD available in capacities up to 15.36TB in a standard U.2 form factor. At current DDR5 pricing, NVMe-based memory extension costs a fraction of equivalent DRAM capacity, and that gap continues to widen as AI-driven demand pressures memory spot prices.
The Pipeline: From Game Film to Queryable Intelligence
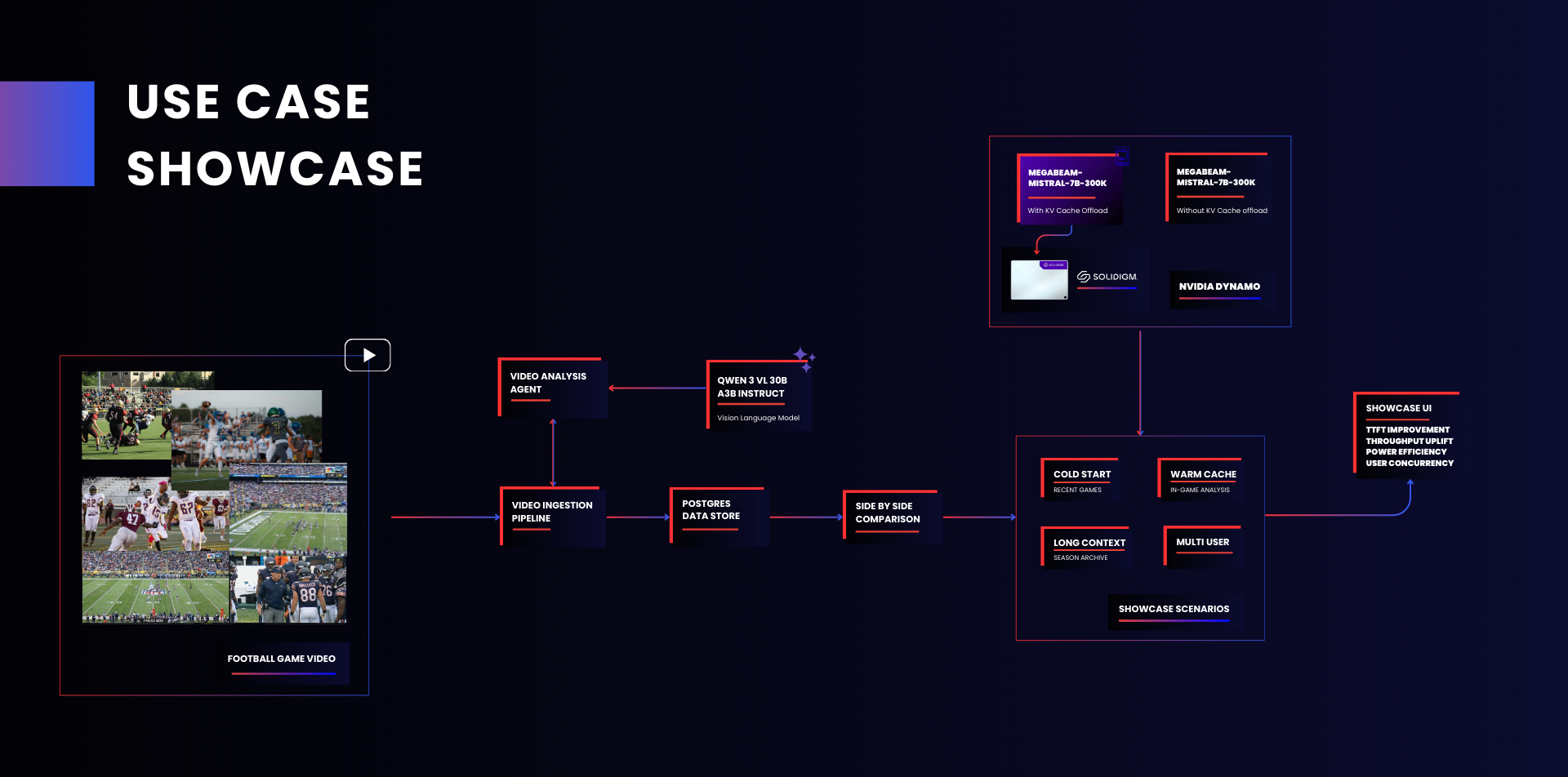
Figure 3 | Use Case Flow Showcase: Agentic Video Analysis Pipeline
The Tactical Sports Analytics platform processes game footage through an agentic pipeline that converts raw video into structured, queryable context for the LLM.
Video Ingestion
Game video (All-22 and broadcast angles) flows into the Video Ingestion Pipeline, which segments footage and stores structured data in PostgreSQL. Each game generates between 50,000 and 76,000 tokens of analyzed context, depending on game length and complexity. At this token density, a single context window can hold approximately four to six full games, enabling cross-game pattern analysis within a single query session.
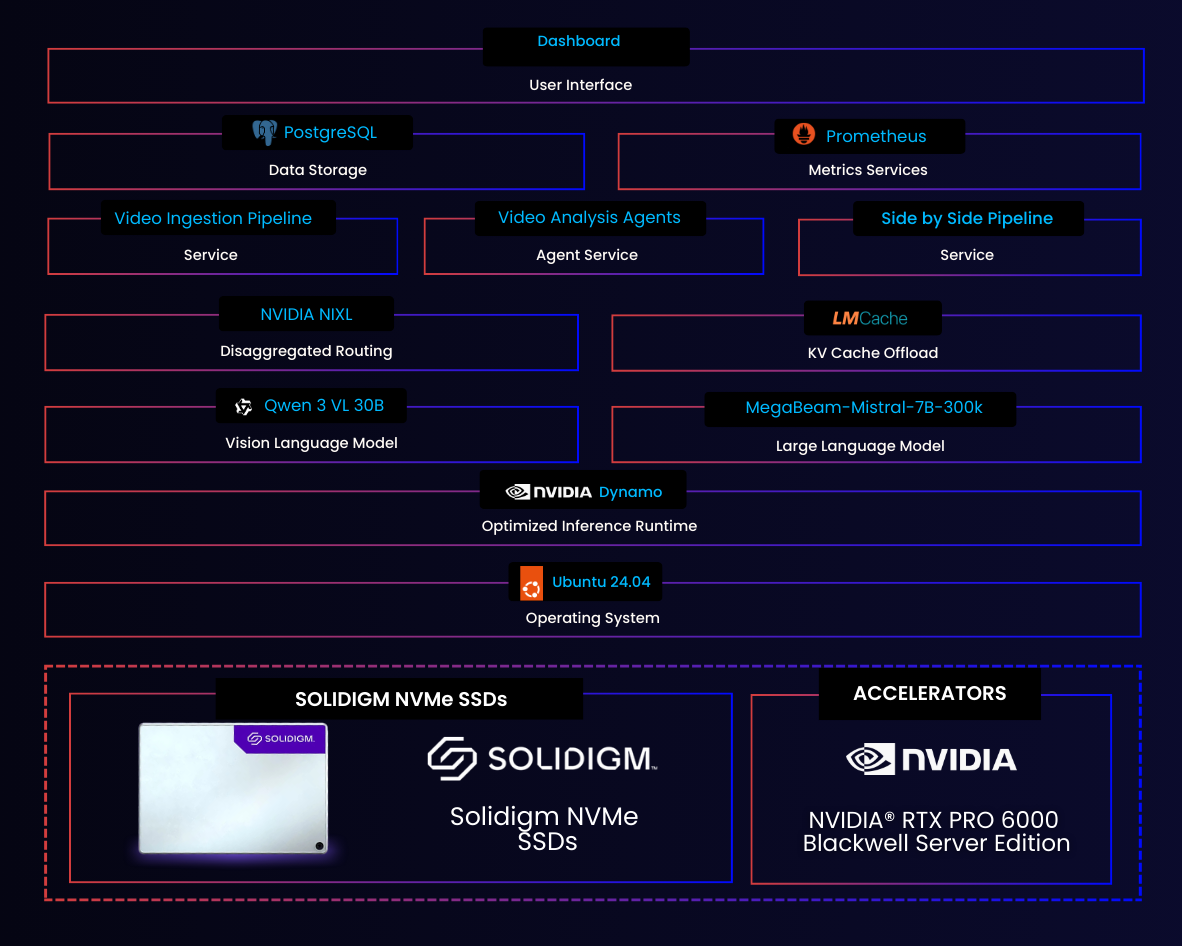
Figure 4 | Technical Architecture: Layered Pipeline from Video Ingestion to Analyst Interface
Vision Language Model Analysis
A Video Analysis Agent sends each segment through Qwen 3 VL 30B A3B Thinking, a vision language model that extracts frame-level analysis from every play: formations, personnel groupings, coverage schemes, route combinations, and key moments. Every play across the season is indexed and described.
LLM Synthesis and Query
The analyzed game context feeds into MegaBeam-Mistral-7B-300k, a large language model with a 300,000-token context window, running on the NVIDIA Dynamo inference runtime. Coaches interact through a natural language chat interface, asking questions grounded in every relevant play. Follow-up queries return in seconds because the context is already loaded. Patterns that human review would miss become visible at scale.
Side-by-Side Comparison
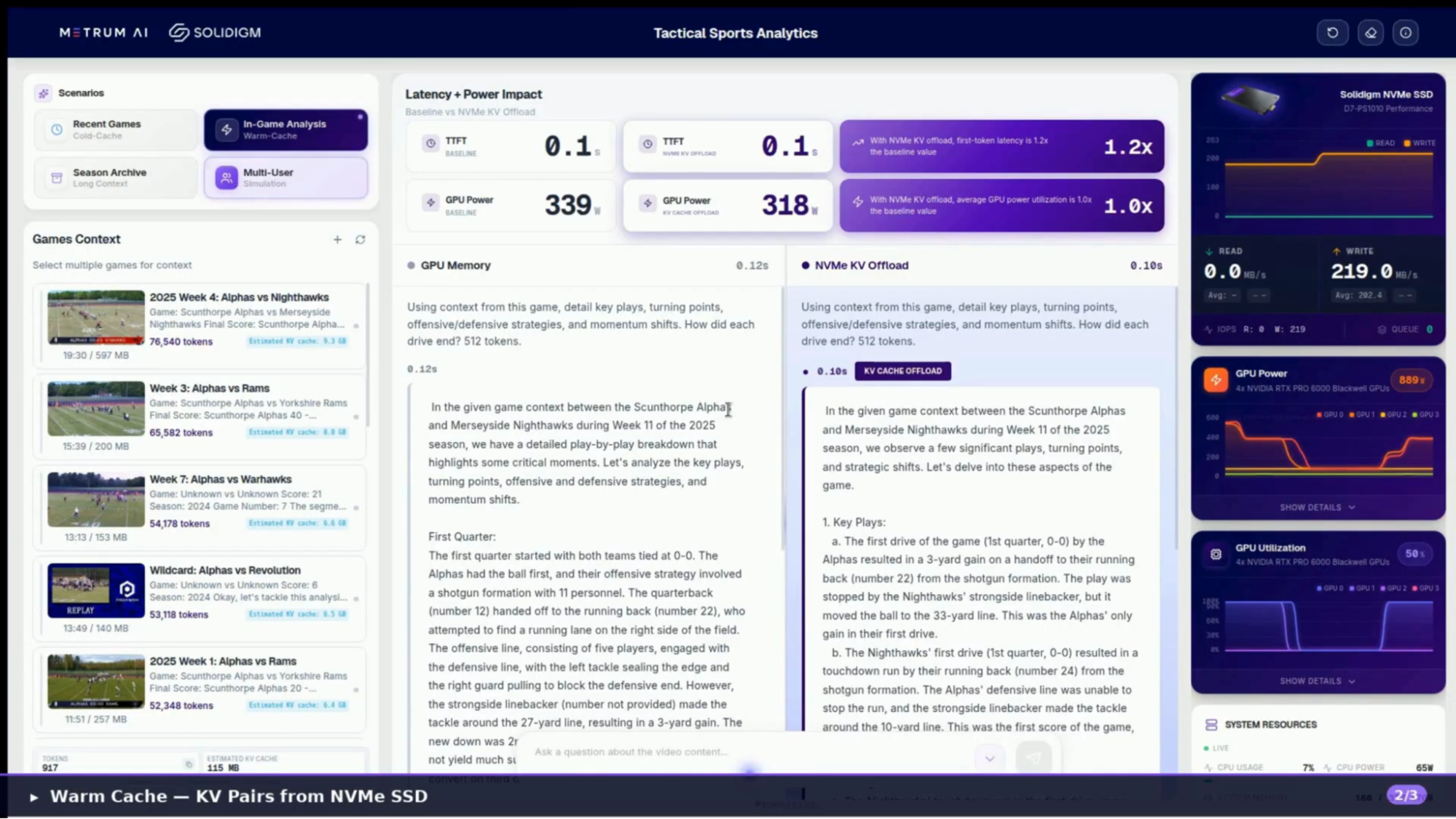
Figure 5 | Dashboard Overview: In-Game Analysis with Warm Cache Parity
The platform runs two identical LLM instances simultaneously: one using GPU memory only (Baseline) and one offloading KV cache to a Solidigm D7-PS1010 NVMe SSD. A live dashboard tracks time to first token, GPU power draw, SSD throughput, cache hit rates, and token generation speed, making the performance difference visible and measurable in real time.
Live Demo Results
| Metric | Value | Scenario | Detail |
|---|---|---|---|
| Faster Time to First Token | 10.9x | Single user | 31.0 seconds to 2.8 seconds on season archive scenarios |
| GPU Power Efficiency | 6.8x | Single user | Power usage in watts over generation time |
| Throughput Uplift | +102% | Multi user | Token throughput under 60-user concurrent load |
| Energy Efficiency | 4.1x | Multi user | Tokens per joule versus baseline at 60 users |
Figure 6 | Key Results from Tactical Sports Analytics Live Demonstration
Season-Scale Analysis: When Context Exceeds GPU Memory
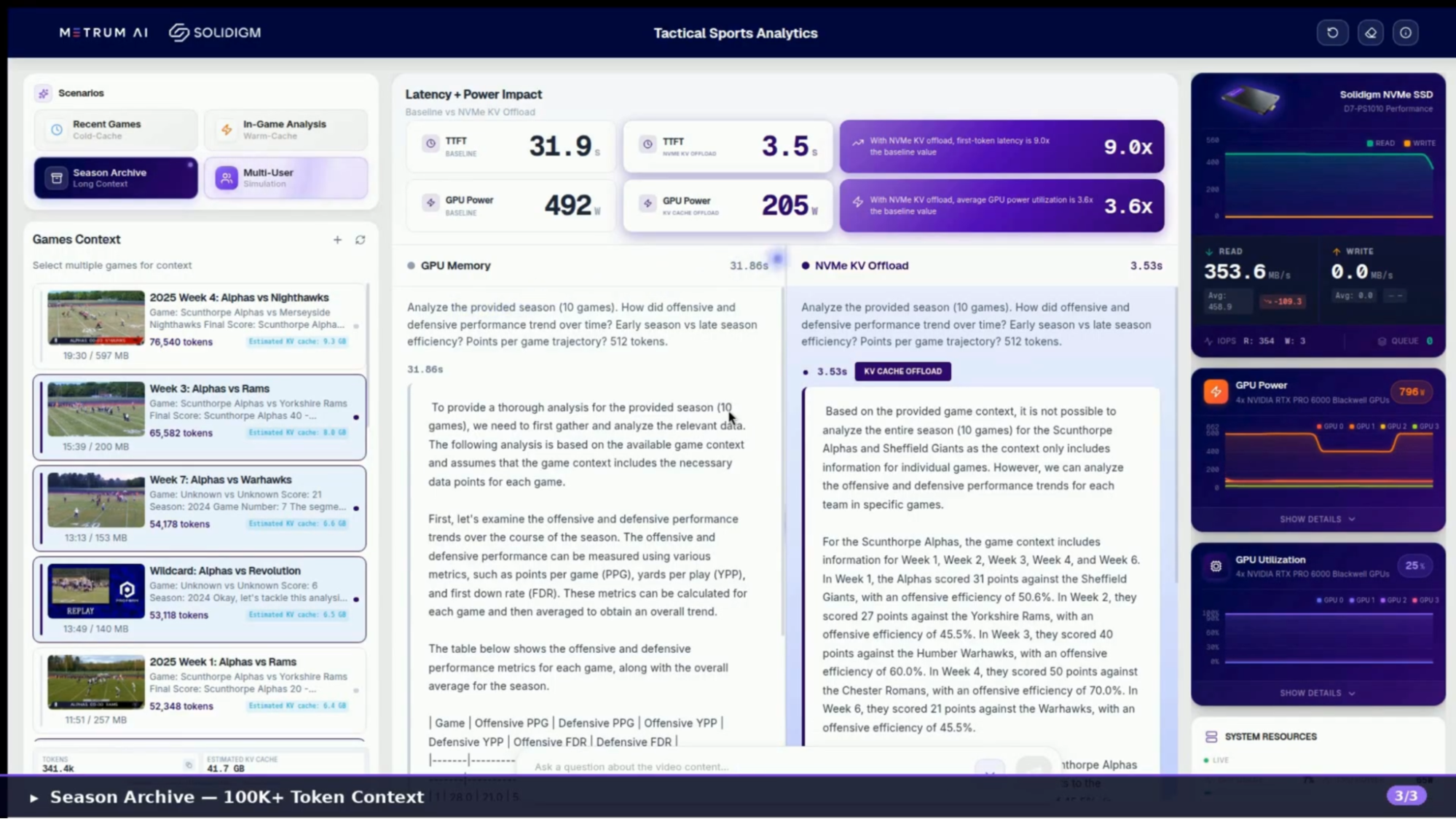
Figure 7 | Season Archive Scenario: 10x TTFT Improvement with NVMe KV Cache Offload
In the Season Archive scenario, the system loads over 300,000 tokens of game context across multiple games, deliberately exceeding what GPU VRAM can hold. When the Baseline path must answer a query against evicted context, it re-prefills from scratch. The NVMe KV Cache Offload path reloads cached blocks from the Solidigm SSD.
| Metric | Baseline (GPU Only) | NVMe KV Offload |
|---|---|---|
| Time to First Token | 31 seconds | 2.8 seconds (10.9x faster) |
| GPU Power Draw (Peak) | 547 watts | 354 watts (6.8x more efficient over generation time) |
| SSD Read Throughput (Peak) | N/A | 553.6 MB/s |
Figure 8 | Season Archive Scenario Performance Comparison
The Baseline GPU spent 31 seconds recomputing attention state before generating a single token, while drawing nearly 550 watts throughout. The NVMe Offload path delivered its first token in 2.8 seconds at less than one-sixth the total energy consumption over the generation cycle. The SSD read throughput confirms the D7-PS1010 is actively serving cached KV blocks at sustained bandwidth, keeping the GPU focused on generation rather than redundant recomputation.
Multi-User Concurrency: Where the Advantage Compounds
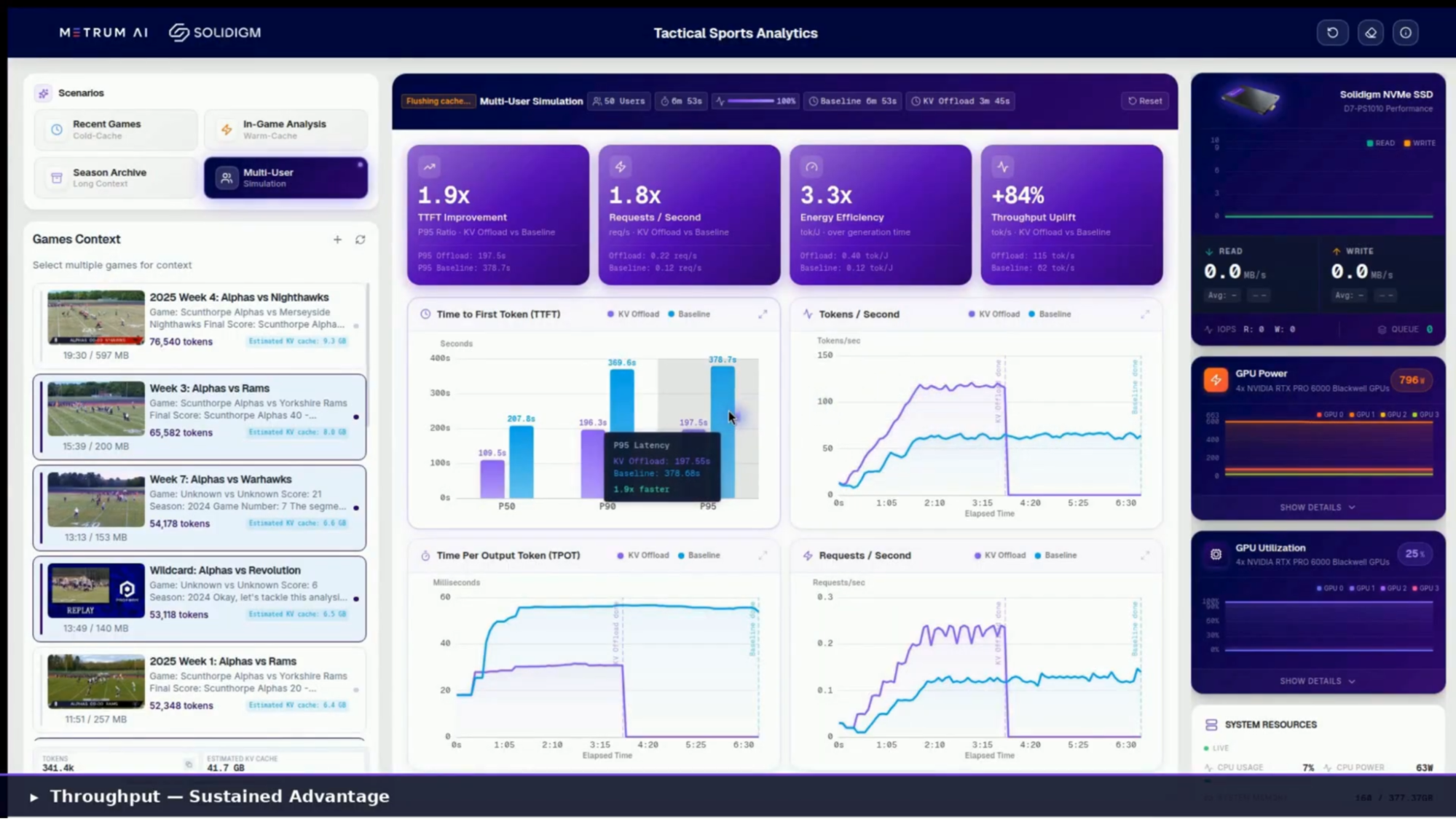
Figure 9 | Multi-User Simulation Results: Sustained Advantage Under Concurrent Load
Single-user latency improvements matter, but the real economics of inference play out under concurrent load. The Multi-User Simulation mode fired 60 simultaneous users against both systems, each with unique queries drawn from a pool of football analytics prompts, with random games selected with every query. Under this load, the KV cache offload advantage does not just hold. It grows.
| Metric | Result (KV Cache Offload vs. Baseline) |
|---|---|
| TTFT Improvement | 2x (P95 ratio) |
| Requests / Second | 2x |
| Energy Efficiency | 4.1x (tokens per joule) |
| Throughput Uplift | +102% (token throughput) |
Figure 10 | Multi-User Simulation Results at 60 Concurrent Users
Under 60-user concurrent load, the Baseline system queued requests and re-prefilled context for each one, driving P95 time to first token above 481 seconds. The NVMe Offload path held P95 TTFT under 237 seconds while sustaining 102% higher token throughput.
Both P95 figures reflect tail latency in a deliberately saturated system designed to stress-test the architecture at its limits. Median response times are substantially lower. The key takeaway is relative: under identical saturation conditions, the offload path sustained nearly twice the request throughput at one-third the energy cost per token. The SSD absorbed context-loading work that would otherwise queue on the GPU, keeping the accelerator focused on generation rather than redundant recomputation.
The architecture's scaling behavior follows a predictable pattern: as concurrent users increase, the offload path's advantage widens because each additional user that hits a warm NVMe cache is one fewer re-prefill cycle competing for GPU compute. At 60 users, the system demonstrated 2x higher request throughput at 4.1x the energy efficiency. Organizations planning for higher concurrency levels can expect this advantage to hold, since the SSD's bandwidth headroom and the cache-aware router's ability to direct requests to pre-loaded context both scale independently of GPU count. Formal characterization at higher concurrency levels is planned for a future publication.
What This Means for Your Infrastructure
The performance data points to four infrastructure outcomes, ordered by the directness of their impact on operational cost.
Eliminate redundant GPU compute. When evicted KV blocks persist on SSD rather than being discarded, returning users receive cached responses in seconds instead of waiting through recomputation. At season-scale context, that translates to 10x lower latency and 6.8x better power efficiency per query. Every re-prefill event the SSD absorbs is one fewer cycle of peak GPU power draw producing no new output.
Reduce energy per query. The 4.1x energy efficiency improvement under multi-user load is a direct consequence of eliminating redundant recomputation cycles. For organizations tracking power consumption per inference request, this shifts the cost curve without changing the hardware footprint.
Serve more users on the same hardware. Under 60-user concurrent load, the NVMe Offload path delivered 2.0x higher request throughput than the GPU-only Baseline. The SSD handles context loading while the GPU focuses on token generation, meaning more users served per accelerator and lower cost per token.
Scale context without scaling GPUs. Long-context models now support 200K to 300K+ tokens per session. Loading a full corpus of enterprise documents or season-scale video analysis can exceed 600,000 tokens, well beyond any single GPU's VRAM capacity. NVMe offload extends effective context using high-density SSD storage rather than additional accelerator hardware.
For organizations evaluating this architecture, the logical next step is a proof-of-concept on representative workloads. Solidigm and NVIDIA Dynamo provide the integration path; the Tactical Sports Analytics platform demonstrates the reference implementation.
Live Demo Test Methodology
The performance results in this paper were captured from live demonstrations on the Tactical Sports Analytics platform. Two identical LLM instances run side by side on the same hardware (Figure 11): one using GPU memory only (Baseline) and one offloading KV cache to Solidigm D7-PS1010 NVMe SSDs. Both receive the same query with the same context at the same time. A live dashboard tracks all metrics via Prometheus at sub-second granularity, making the performance difference visible and measurable in real time.
System Under Test
All benchmarks executed on a single server node with the following configuration:
| Component | Specification |
|---|---|
| CPU | AMD EPYC 9554 64-Core Processor |
| Memory | 384 GB DDR5, 12-channel at 4800 MT/s |
| GPU | 4x NVIDIA RTX PRO 6000 Blackwell Server Edition (96 GB VRAM each) |
| Storage (Offload) | 2x Solidigm D7-PS1010, 15.36 TB, PCIe 5.0, 176L TLC |
| Inference Runtime | NVIDIA Dynamo with NIXL optimized data transfer |
| LLM | MegaBeam-Mistral-7B-300k (300K context window) |
| VLM | Qwen 3 VL 30B A3B Thinking (video frame analysis) |
| Operating System | Ubuntu 24.04.3 LTS, Kernel 6.8.0-83-generic |
Figure 11 | System Under Test Configuration
| Scenario | Context Load | What It Demonstrates |
|---|---|---|
| Cold Start (Recent Games) | ~140K tokens (5 games) | Fairness baseline. Neither path has cached context. Both compute from scratch. TTFT and power should be comparable, confirming the offload layer adds zero overhead for new content. |
| Warm Cache (In-Game Analysis) | ~1K tokens (1 game) | Caching benefit on follow-up queries. First query is comparable; subsequent queries show GPU caching advantage as cached KV blocks reload from the GPU Memory instead of recomputing. |
| Season Archive (Long Context) | ~340K tokens (10 games) | Key scenario. Context exceeds GPU VRAM. Baseline re-prefills from scratch (20-40 seconds). NVMe Offload reloads cached blocks in seconds at a fraction of the GPU power draw. |
| Multi-User Simulation | ~30K-180K tokens per user (60 users) | Production-scale concurrency. 60 simultaneous users with unique queries. Measures P50/P90/P95 TTFT, requests/sec, tokens/sec, and energy efficiency (tokens per joule) under load. |
Figure 12 | Live Demonstration Scenarios and Measurement Focus
Metrics captured across all scenarios include time to first token, token throughput, GPU power draw, GPU utilization, SSD read/write throughput, cache hit rate, requests per second, and energy efficiency (tokens per joule). GPU caches are flushed before each scenario to ensure no residual state influences results. The Cold Start scenario serves as the parity check: comparable performance on both paths confirms a fair comparison before the caching scenarios reveal the difference.
Multi-User Simulation results reflect tail latency (P95) under deliberate system saturation at 60 concurrent users. Median response times are substantially lower. All reported comparisons are relative: both paths face identical queries, identical context, and identical concurrent load.
The Bottom Line
KV cache offload is a production-ready architectural pattern that addresses the single largest source of wasted GPU compute in multi-user LLM inference: redundant recomputation of previously computed attention states.
This architecture shifts the cost curve of multi-user LLM inference. Organizations that persist computed attention state on Solidigm NVMe SSDs and integrate with NVIDIA Dynamo's cache-aware scheduling reduce GPU waste, serve more users per node, and extend context capacity without additional accelerators.
For infrastructure teams planning their next inference deployment, the question is worth asking: how much of your current GPU spend is recomputing attention states that NVMe storage could serve in seconds?
Addendum
Pricing Methodology Note
All pricing in this publication reflects approximate market ranges as of Q1 2026 and is derived from publicly available sources including retailer listings, industry analyst reports, and manufacturer product pages. Memory pricing is inherently volatile; the figures presented are intended to illustrate relative cost differences across tiers, not to serve as procurement guidance.
GPU VRAM: The ~$50-80/GB range shown in Figures 1 and 2 reflects estimated GDDR7 memory component costs. Full accelerator card pricing yields a higher effective $/GB ($125/GB for the RTX PRO 6000 at retail, $213-284/GB for HBM-based H200). The component-level estimate excludes GPU die, PCB, and system integration costs, and is consistent with how memory costs are typically presented in TCO analyses for infrastructure planning.
CPU DRAM: The ~$5-8/GB range reflects DDR5-4800 RDIMM server module pricing at enterprise contract volumes. Spot and retail pricing for DDR5 server memory has been significantly elevated since late 2025 due to AI-driven demand reallocation, with some analyst projections indicating year-over-year doubling by late 2026.
NVMe SSD: The ~$0.08-0.12/GB range reflects Solidigm D7-PS1010 enterprise volume pricing for the 15.36 TB capacity point. Published single-unit retail pricing ranges from approximately $0.21-0.36/GB depending on vendor and region. Enterprise procurement at volume typically achieves 40-50% below single-unit retail.
References
GPU VRAM Pricing
[1] NVIDIA RTX PRO 6000 Blackwell Server Edition, 96 GB GDDR7 ECC, PCIe 5.0 x16. Newegg product listing, Item #9SIATRNKK51563. Retail price: $11,989.00 (as of March 2026). At 96 GB, this yields approximately $125/GB at full card pricing. newegg.com
[2] JarvisLabs, "NVIDIA H200 Price Guide 2026," January 2026. NVIDIA H200 GPU at $30,000-$40,000 for 141 GB HBM3e, yielding $213-$284/GB. For comparison purposes; the system under test uses GDDR7-based RTX PRO 6000 accelerators, not HBM. docs.jarvislabs.ai
CPU DRAM Pricing
[3] Network World, "Server memory prices could double by 2026 as AI demand strains supply," November 20, 2025. Cites Counterpoint Research data: DRAM prices up approximately 50% year to date; Samsung raised 32 GB DDR5 module pricing to $239 from $149 in September 2025 (60% increase). Counterpoint projects DDR5 64 GB RDIMM costs could double by end of 2026. networkworld.com
[4] Tom's Hardware, "Server memory prices to double year-over-year in 2026, LPDDR5X prices could follow," November 19, 2025. Reports 16 GB DDR5 chip spot price at DRAMeXchange averaged $24.83 (up from $6.84 in September 2025). Cites Counterpoint Research forecast of server DDR5 prices doubling year-over-year by late 2026. tomshardware.com
NVMe SSD Pricing
[5] ServerSupply, Solidigm D7-PS1010, 15.36 TB, U.2 15mm, PCIe 5.0 x4, TLC. Part number: SB5PH27X153T001. Retail price: $3,250.00 (as of March 2026), yielding approximately $0.21/GB at single-unit retail. Enterprise volume pricing typically 40-50% below single-unit retail. serversupply.com
[6] Solidigm, "D7-PS1010 PCIe 5.0 NVMe SSD for Data Centers" product page. Specifications: up to 15.36 TB capacity, U.2 and E3.S form factors, 176L TLC 3D NAND, PCIe 5.0 x4, sequential read up to 14,500 MB/s, sequential write up to 9,300 MB/s, 2.5M hour MTBF. solidigm.com
DRAM Market Context (Supplementary)
[7] TechRadar, "2026 could see 32GB DDR5 memory costing $500 as analysts warn of steep DRAM price rises driven by server demand," January 8, 2026. Cites TrendForce forecast of DRAM contract prices rising 55-60% quarter-over-quarter in Q1 2026. techradar.com
[8] Tom's Hardware, "Here's why HBM is coming for your PC's RAM," December 19, 2025. Reports each gigabyte of HBM consumes roughly three times the wafer capacity of DDR5. SK hynix advanced packaging lines at capacity through 2026. Contextualizes the structural supply constraint driving memory pricing across all tiers. tomshardware.com
[9] Newegg, Solidigm D7-PS1010 Series, 15.36 TB, U.2 15mm, PCIe 5.0 x4, TLC. Item #N82E16820318064. Retail price: $5,574.99 (as of March 2026). Represents higher-end retail channel pricing; volume procurement pricing is lower. newegg.com
Copyright © 2026 Metrum AI, Inc. All Rights Reserved. This project was commissioned by Solidigm. Solidigm and other trademarks are trademarks of Solidigm or its subsidiaries. NVIDIA, Dynamo, RTX PRO, and related marks are trademarks of NVIDIA Corporation. AMD and EPYC are trademarks of Advanced Micro Devices, Inc. MegaBeam-Mistral is based on the Mistral model architecture. All other product names mentioned are the trademarks of their respective owners.
DISCLAIMER - Performance results are based on live demonstration measurements and may vary by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance. Formal benchmark results under controlled conditions will be published separately.