This blog presents a Gen AI assisted content creation solution powered by the Nvidia H200 GPUs on Dell PowerEdge XE9680 servers.

Enterprises struggle with efficient and consistent content creation across their documentation needs, particularly in time-sensitive technical marketing and product launches. Traditional content generation processes are resource-intensive and often delay crucial market announcements, requiring significant manual effort to gather information, maintain brand consistency, and ensure technical accuracy.
To address these obstacles in content creation for enterprises, we have developed a RAG-based Content Creation solution powered by the Dell PowerEdge XE9680 server with NVIDIA H200 GPUs, designed to enable enterprises to automate these content workflows while maintaining enterprise security and utilizing existing content repositories.
In this blog, we explore the solution architecture and demonstrate:
- How RAG-based content generation intelligently leverages your reference documents and visual assets to create content
- How to deploy advanced language and embeddings models on the Dell PowerEdge XE9680, with support for Broadcom Ethernet Adapters (up to 200 GbE), along with eight NVIDIA H200 GPUs
- How customizable newsletter and product launch templates enable rapid content creation while maintaining brand consistency and factual accuracy
Hardware Selection

We selected the Dell PowerEdge XE9680 equipped with eight NVIDIA H200 GPUs for our solution due to its exceptional performance and memory capacity, which is crucial for handling the latest high parameter count large language models. With 141GB of HBM3e memory per GPU, representing a significant 60% increase from the H100's 80GB, we can efficiently run and serve multiple instances of leading large language models.
Solution Architecture
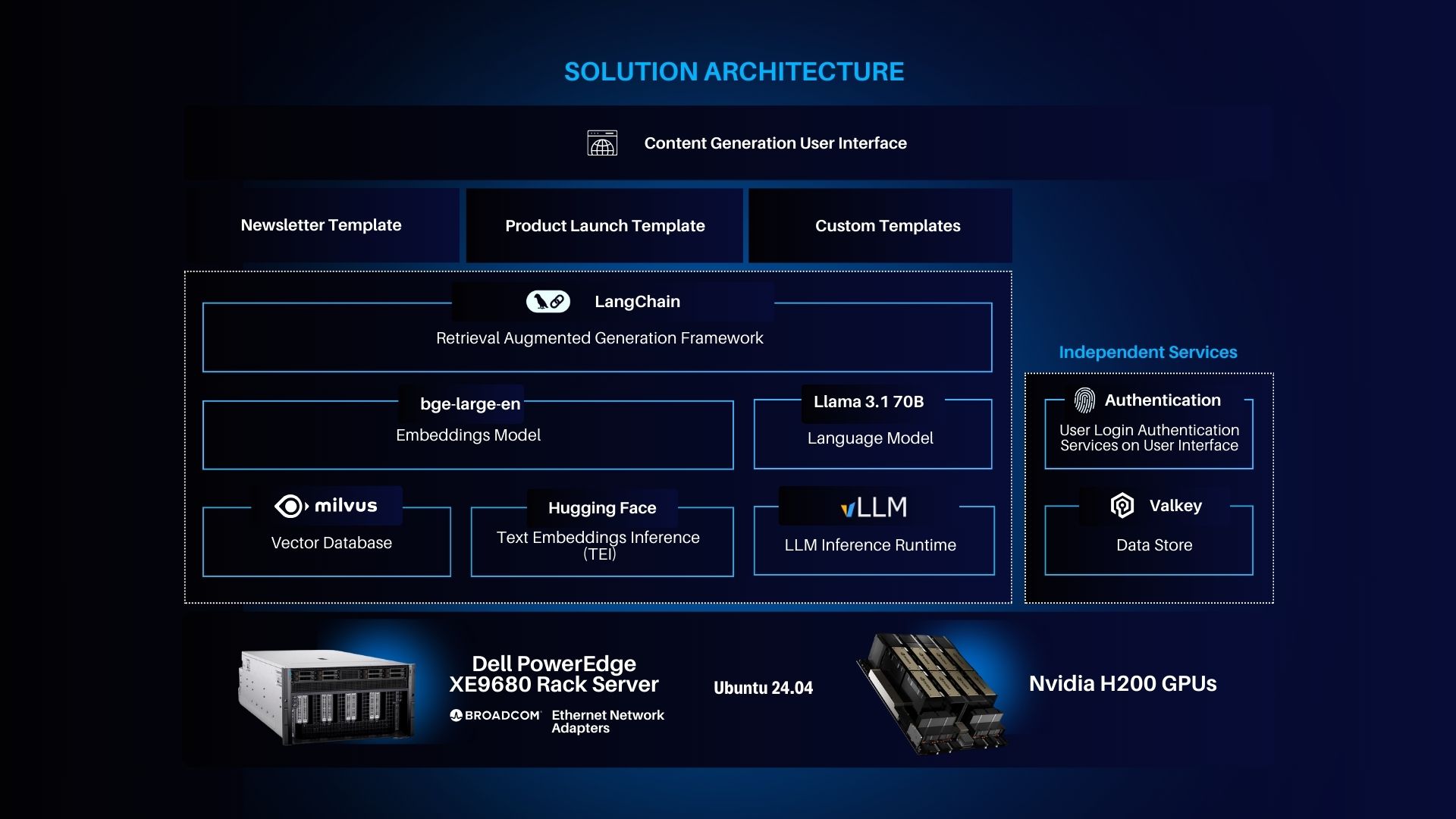
This solution leverages the following technologies:
- Content Generation via LLMs and Retrieval-Augmented Generation: Large language models (LLMs) are at the core of this architecture, enabling the generation of high-quality, contextually relevant content.
- Plug-and-Play Modular Architecture: The architecture enables seamless integration of various critical components such as embedding models, vector databases, and LLMs.
- High-Performance and Scalable Hardware Setup: To meet the demands of real-time content generation and retrieval tasks, the system runs on powerful hardware.
The software stack includes:
- LangChain: A framework for retrieval-augmented generation (RAG).
- bge-large-en (Embeddings Model): A high-ranking text embedding model.
- LLaMA 3.1 70B (Language Model): An advanced, open-weight large language model with 70 billion parameters.
- Hugging Face APIs: Provides tools for text embedding and inference.
- vLLM (LLM Inference Runtime): A PyTorch-based runtime for efficiently serving LLMs.
- Milvus (Vector Database): An open-source vector database designed for high-performance embedding storage.
Solution Overview
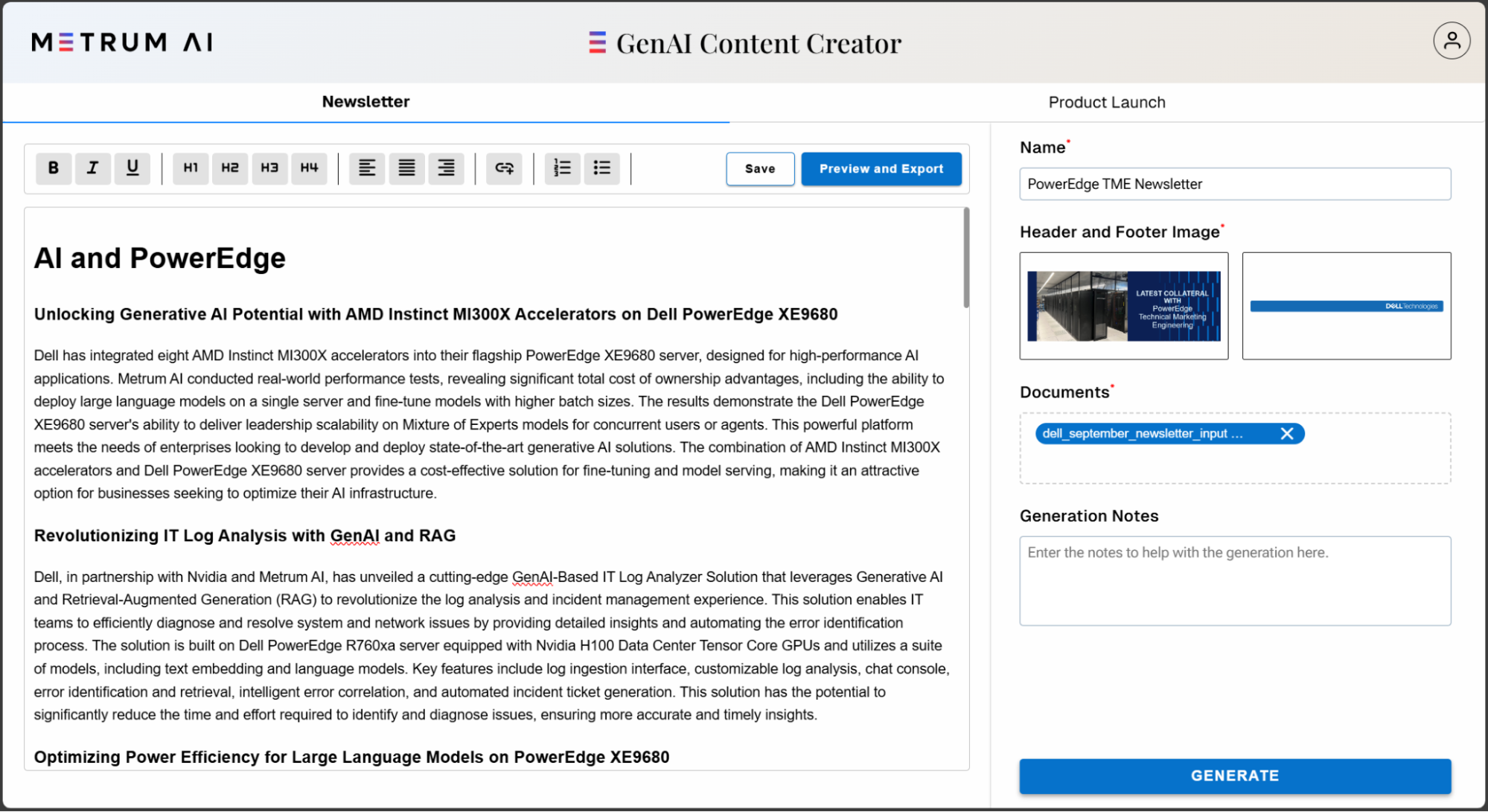
This solution provides a streamlined interface for users to efficiently generate high-quality content. Users can select from various content templates, such as "Generate Newsletter" or "Product Launch," and customize key inputs like the name of the document and header/footer images.
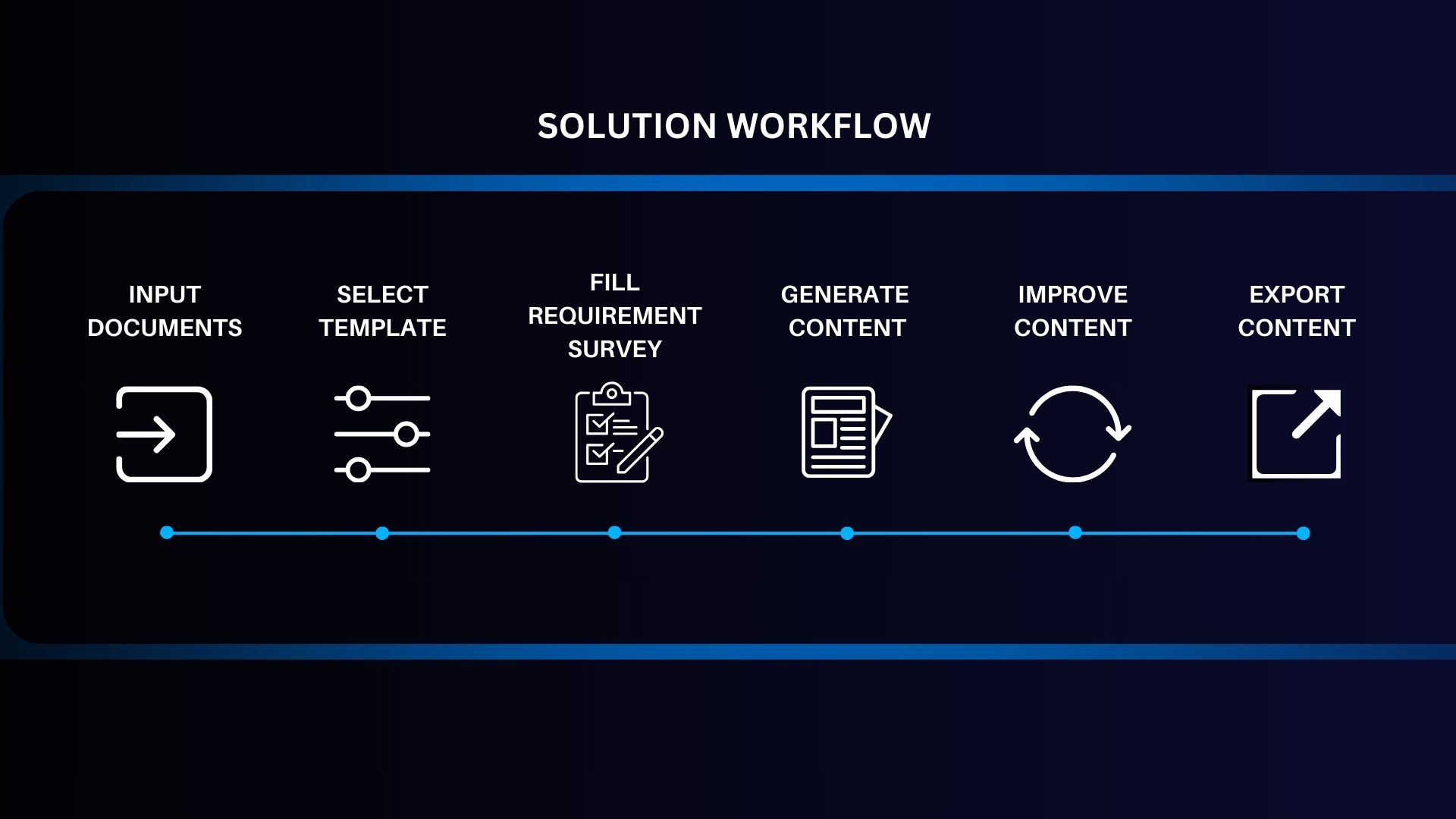
The image below illustrates each segment of the workflow:
In this blog, we demonstrated how enterprises can leverage their existing content and documentation to harness advanced generative AI capabilities. We achieved the following milestones:
- Tested Nvidia H200 GPU vs Nvidia H100 GPU performance in a vLLM model serving scenario with Llama 3.1 70B in FP16 precision.
- Developed an enterprise-grade content generation solution utilizing large language models and customizable templates.
- Implemented an intuitive, flexible system that streamlines newsletter creation and product documentation.
To learn more, please request access to our reference code by contacting us at contact@metrum.ai.
Copyright © 2024 Metrum AI, Inc. All Rights Reserved. This project was commissioned by Dell Technologies. Dell and other trademarks are trademarks of Dell Inc. or its subsidiaries. Nvidia and combinations thereof are trademarks of Nvidia. All other product names are the trademarks of their respective owners.
DISCLAIMER - Performance varies by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance.