
Executive Summary
Network camera shipments now exceed 116 million units annually, with over one billion surveillance cameras active worldwide.[1] As 4K resolution drives a 20x increase in data per camera, organizations applying AI video analytics face exponential growth in vector embeddings (high-dimensional representations of visual content used for similarity search) that require real-time retrieval.[2] Each hour of processed video can generate thousands of embeddings and associated metadata. At enterprise scale, vector databases grow to hundreds of millions of records across standard retention windows. Traditional DRAM-based retrieval methods often struggle to scale economically with these expanding archives. At 100 million vectors, in-memory indexes can require over 300 GB of DRAM, creating cost and complexity barriers that limit how long organizations can retain searchable video. For enterprises managing thousands of hours of footage, this tradeoff carries real operational risk: missed incidents, delayed investigations, and compliance gaps.
To address this, Metrum AI developed a scalable video intelligence architecture powered by Solidigm D7-PS1010 NVMe SSDs. The solution combines DiskANN indexing (a graph-based vector search algorithm optimized for SSD storage, implemented via Milvus) with NVIDIA® NIM microservices for GPU-accelerated embedding generation and reranking. This architecture enables continuous video ingestion, policy-driven analysis, and responsive retrieval without proportional DRAM expansion. In synthetic benchmarks at 100 million vectors, DRAM consumption drops by up to 65% while query throughput increases 14% over in-memory HNSW indexing. Under the tested workload, the platform achieved 2,371 QPS at 1,024 concurrent threads with 10% lower P99 latency.
Scalable vector retrieval addresses one memory constraint. Video intelligence pipelines face a second bottleneck: GPU VRAM limitations during long-context LLM inference. Model weights must remain resident in high-bandwidth memory (HBM) at all times, leaving only the remaining capacity for the KV cache (key-value tensors generated during attention computation) and other runtime data structures. This constraint limits how organizations can scale inference servers without degrading user experience. Analysts working with 180,000-token documents consume over 90% of available GPU memory. When they switch between documents or return to previously reviewed content, traditional systems must recompute the KV cache from scratch, forcing 30- to 40-second delays before any response.
KV cache data placement extends the memory hierarchy to LLM inference, enabling tensors to reside across multiple tiers: GPU HBM for active inference, CPU-attached DRAM for recently accessed contexts, local NVMe storage for previously processed documents, and potentially remote storage for archival contexts. The system preserves computed tensors across this hierarchy rather than discarding them. When analysts return to a cached document, the system retrieves stored tensors in 1.43 seconds rather than recomputing them in 39 seconds. This 27.4x improvement in time to first token transforms multi-document analysis from a latency-constrained process into a responsive investigative workflow.
These operational benefits require longer initial index construction. DiskANN's optimized data placement takes 30% to 60% more time to build compared to HNSW. For most enterprise deployments where indexes are built once and queried continuously, this one-time cost is offset by sustained performance gains. Organizations with frequent index rebuilds, such as high-churn content libraries or rapid ingestion environments, should factor build time into capacity planning. For IT Directors and Infrastructure Architects deploying video analytics at scale, this solution enables a shift from memory-constrained systems to storage-optimized architectures that grow with operational demand.
Solution Overview
To address these challenges, we have developed a scalable video intelligence architecture for enterprise content analysis. The solution introduces SSD-offloaded retrieval directly into the AI inference pipeline, significantly reducing DRAM requirements while maintaining the throughput needed for production workloads. This approach enables organizations to scale vector archives without proportional memory expansion.
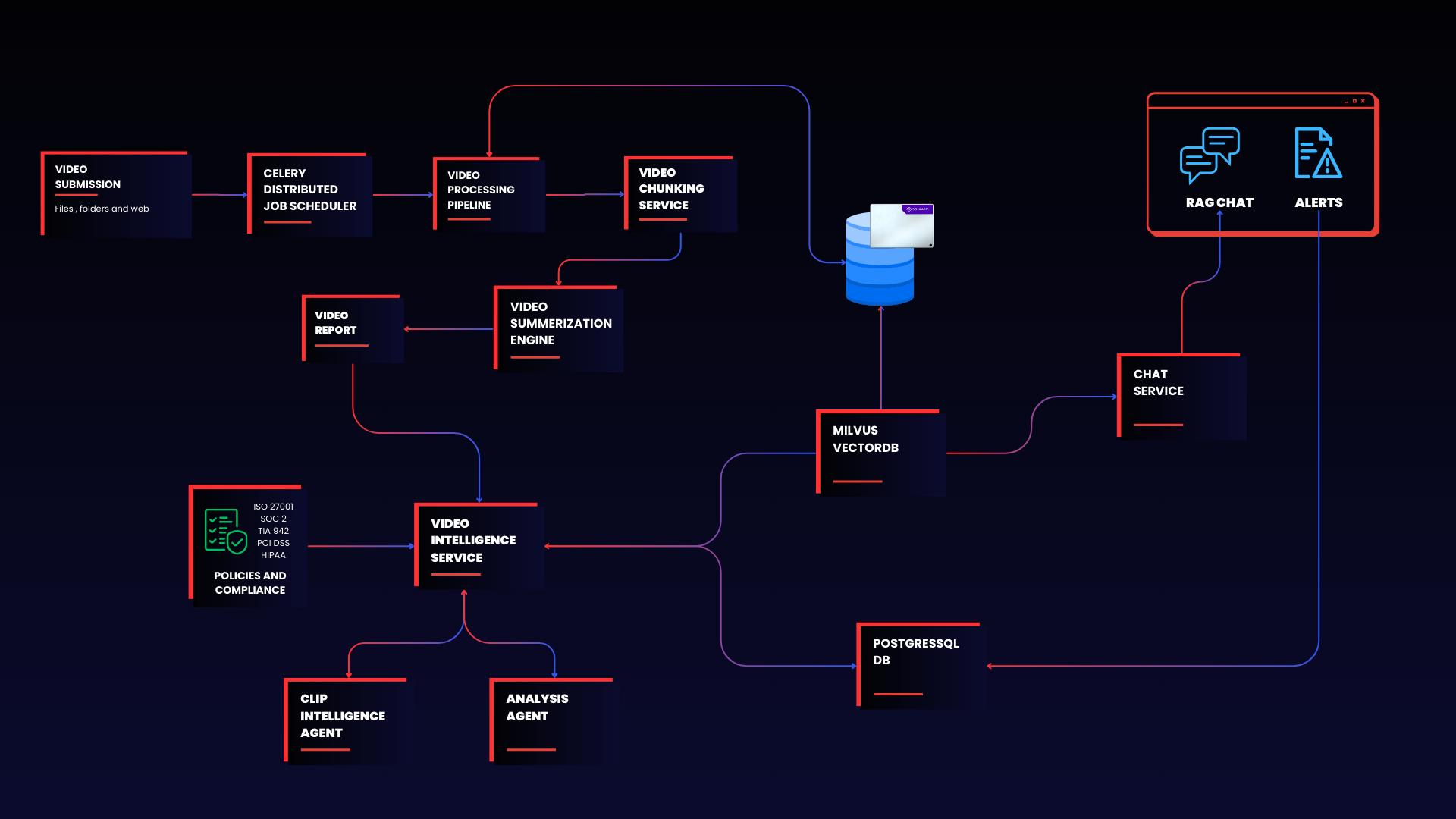
Figure 1 | End-to-end video intelligence pipeline showing data flow from ingestion through SSD-based indexing to analyst investigation
The architecture operates across three distinct phases: Ingest, Index, and Investigate. This separation allows infrastructure teams to scale each layer independently based on operational demands.
Phase 1: Ingest
Video streams from enterprise sources flow continuously into the processing pipeline. The system segments raw footage into fixed-length clips, tagging each with timestamps and source metadata. NVIDIA NIM microservices then analyze each segment to generate lightweight semantic signals such as object classifications, scene categories, and activity tags. These signals prepare content for downstream policy evaluation and search.
Phase 2: Index
A dedicated NVIDIA embedding NIM converts each processed segment into a high-dimensional vector representation optimized for similarity search. Milvus with DiskANN indexing stores these vectors on Solidigm D7-PS1010 NVMe SSDs rather than holding the full index in system memory. This storage-optimized approach enables the archive to grow from millions to hundreds of millions of vectors without requiring proportional DRAM expansion. The Solidigm D7-PS1010's PCIe 5.0 interface sustains the random read performance that DiskANN's graph traversal algorithm demands.
Phase 3: Investigate
Analysts interact with the indexed archive through multiple pathways. The Policy Service continuously evaluates incoming segments against predefined rules, flagging anomalies and operational events for review. When a policy triggers, the Clipper Agent extracts the relevant video window and generates a reviewable snippet tied to the specific incident.
For exploratory analysis, the RAG Chat Service transforms natural language questions into embedding-augmented queries. Analysts receive grounded, context-aware responses drawn from the vector archive and enhanced by LLM reasoning. Neo4j maintains a knowledge graph that connects related entities and events, surfacing patterns across cameras, locations, and timelines.
Workflow Summary
Phase | Components | Function |
Ingest | Video Processing Service, NIM Interpretation | Segment footage, extract semantic signals |
Index | NIM Embedding, Milvus with DiskANN, Solidigm SSDs | Generate vectors, store on SSD-optimized index |
Investigate | Policy Service, Clipper Agent, RAG Chat, Neo4j | Detect incidents, enable analyst queries |
This three-phase design ensures consistent progression from raw video to actionable intelligence. Each phase maintains high throughput and responsiveness even under heavy concurrent load from multiple analysts and automated policy engines.
Solution Architecture
Data flows from video ingestion at the left through AI processing in the center, terminating at analyst interfaces and outputs on the right. The architecture follows a layered design, separating concerns across video ingestion, AI inference, vector storage, and analyst interfaces.
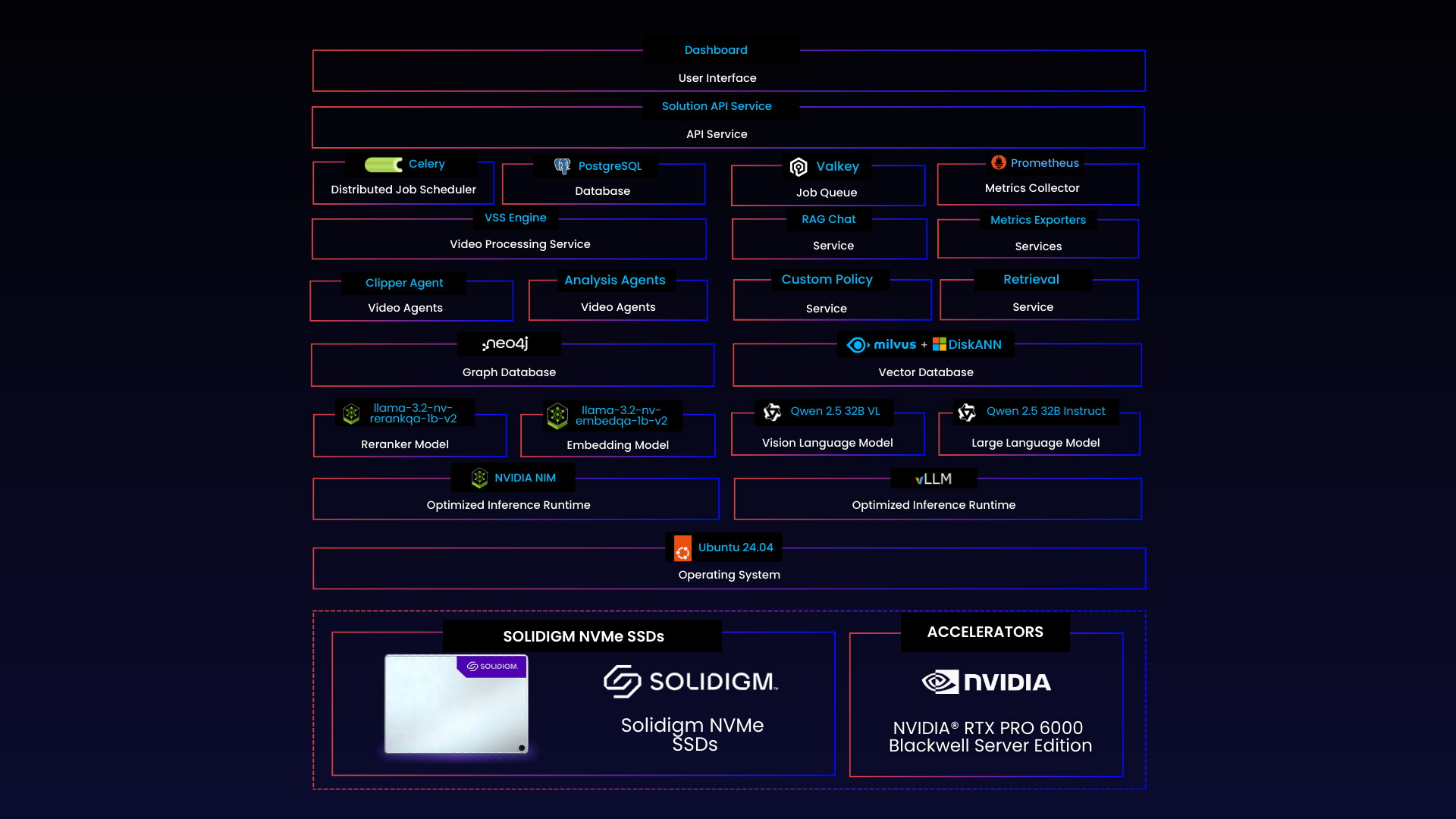
Figure 2 | Solution Architecture: Layered data pipeline from video ingestion through AI inference to analyst-facing outputs
Component | Function |
Video Processing Service | Segments video streams into fixed-length clips, tags with timestamps and source metadata. Manages concurrent ingestion from multiple sources. |
NIM Embedding Model | Generates high-dimensional vector representations for each video segment, optimized for similarity search and downstream policy evaluation. |
NIM Reranker | Refines retrieval results using semantic signals, improving relevance for RAG queries and analyst investigations. |
vLLM Language Service | Hosts Qwen2.5-32B for context reasoning, chat responses, and report generation. Supports RAG-augmented querying across the vector archive. |
Milvus with DiskANN | Stores and retrieves vector indexes on Solidigm NVMe SSDs. Enables scalable search without DRAM constraints. |
Policy Service | Compares interpreted segments against analyst-defined rules. Detects anomalies and raises incident flags for review. |
Clipper Agent | Extracts relevant video windows around detected events. Generates reviewable snippets tied to specific incidents. |
RAG Chat Service | Transforms natural language queries into embedding-augmented searches. Returns grounded, context-aware responses. |
Video Processing Layer
Raw video files are transferred to Solidigm NVMe SSDs and segmented into fixed-length clips tagged with timestamps and source metadata. The high sequential bandwidth of the D7-PS1010 supports concurrent read and write operations during ingestion without throttling downstream processing.
AI Inference Layer
NVIDIA RTX™ PRO 6000 GPUs run select NIM microservices for embedding generation and semantic reranking. A dedicated vLLM service hosts Qwen2.5-32B for language reasoning and RAG-based chat responses. GPU utilization remains stable because SSD-offloaded retrieval prevents memory bottlenecks from starving the inference pipeline.
Vector Storage Layer
Milvus with DiskANN stores vector indexes directly on Solidigm D7-PS1010 SSDs. The Vamana graph algorithm optimizes data placement during index construction to maximize I/O locality. This preprocessing enables efficient random read patterns during query traversal, sustaining 217,750 IOPS across concurrent retrieval operations. The design supports scaling from millions to hundreds of millions of vectors without requiring proportional DRAM expansion.
Policy and Analysis Layer
The Policy Service evaluates each video segment against analyst-defined rules to detect anomalies or operational events. When a rule triggers, the Clipper Agent extracts the relevant video window and generates a reviewable snippet. Neo4j connects related entities and events to surface patterns across cameras and timelines.
Analyst Interface Layer
A React-based dashboard provides real-time visualization of incidents, policy violations, and system metrics. The RAG Chat Service transforms analyst questions into embedding-augmented queries, returning grounded responses from the vector archive. API access enables integration with existing security and compliance tooling.
This multi-database architecture ensures sub-second query response during active investigations. Agents retrieve historical incidents, current metrics, and configuration data without waiting for cross-system joins or data transformations. The storage subsystem keeps pace with continuous GPU-driven embedding generation, preventing pipeline stalls that would otherwise degrade throughput under heavy ingestion.
Solution Benchmark Results
Organizations evaluating video intelligence platforms need more than theoretical performance claims. They require validated results from production-representative workloads that reflect real operational conditions. To validate this SSD-offloaded architecture built on Solidigm D7-PS1010 NVMe SSDs, Metrum AI conducted comprehensive benchmarking using their multi-agent video analysis solution.
Benchmark Methodology
Testing followed a standardized methodology designed to reflect production query patterns while enabling reproducible comparisons between indexing strategies.
Parameter | Value |
Vector Dimensions | 768 |
Embedding Model | NVIDIA NIM Embedding Model |
Recall Target | 0.97+ (based on achieved results) |
HNSW Parameters | M=30, efConstruction=360, ef=100 |
DiskANN Parameters | search_list=100 |
Vector Database | Milvus 2.5.3 |
Test Configuration
The benchmark processed 1,000 videos totaling 3,000 minutes of content, generating 140,900 vector embeddings. Tests executed at 1,024 concurrent threads, equivalent to approximately 50 security analysts running simultaneous queries alongside 200 automated policy evaluation agents and 50 API integration endpoints. This load profile represents peak operational demand during a major incident investigation when multiple teams access the archive simultaneously.
Parameter | Specification |
Video Dataset | 1,000 videos (3,000 minutes) |
Vector Count | 140,900 embeddings |
Concurrent Threads | 1,024 |
CPU | AMD EPYC™ 9554 64-Core Processor |
Memory | 384 GB DDR5 (4800 MT/s) |
GPU | 4x NVIDIA RTX PRO 6000 |
Storage | 2x Solidigm D7-PS1010 15.36TB NVMe SSDs (PCIe 5.0) |
Headline Results
The SSD-offloaded DiskANN configuration delivered measurable improvements across every key performance metric compared to DRAM-bound HNSW indexing.
Metric | HNSW (DRAM-Bound) | DiskANN (SSD-Offloaded) | Improvement |
Query Throughput (QPS) | 2,071 | 2,371 | +14% |
Average Latency (ms) | 494 | 432 | 13% faster |
P99 Latency (ms) | 860 | 770 | 10% faster |
These results challenge a common infrastructure assumption. Many architects expect SSD-based retrieval to sacrifice throughput for cost savings. The benchmark demonstrates the opposite outcome. DiskANN achieves higher query throughput while simultaneously reducing memory requirements and delivering more consistent response times under concurrent load.
Performance Analysis
Throughput Scaling Behavior. Both indexing approaches scale query throughput as concurrency increases, but DiskANN maintains a consistent advantage across the tested range. At enterprise concurrency levels (512 to 1,024 threads), DiskANN continues scaling smoothly while HNSW begins plateauing. This scaling characteristic directly impacts system capacity planning: fewer servers required to support the same user population.
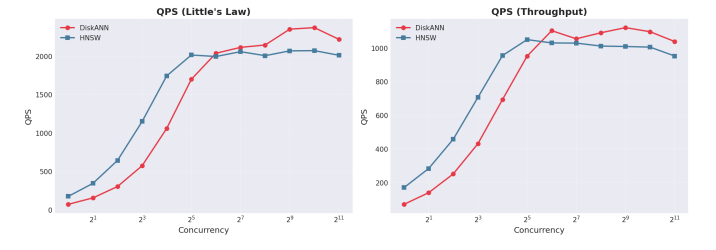
Figure 3 QPS vs Concurrency
Latency Consistency Under Load. The 13% improvement in average latency translates to faster analyst response times during investigations. More significantly, the 10% reduction in P99 latency indicates fewer outlier queries that could disrupt time-sensitive operations. Consistent response times matter for automated policy evaluation workflows where unpredictable latency introduces compliance risk.
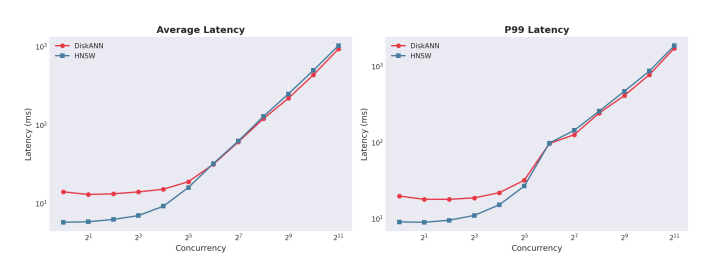
Figure 4 | Latency vs Concurrency (Average and P99)
Storage Performance Under Load. DiskANN shifts index traversal from DRAM to NVMe storage, placing significant I/O demands on the storage layer. During benchmark testing, the Solidigm D7-PS1010 sustained 217,750 random read IOPS across 1,024 concurrent query threads. This I/O capacity enabled DiskANN to deliver 14% higher throughput and 13% lower latency than DRAM-bound HNSW, while reducing memory requirements. The D7-PS1010's PCIe 5.0 interface and optimized firmware prevent storage from becoming the bottleneck that would otherwise limit SSD-offloaded architectures.
Specification | Value |
Interface | PCIe 5.0 x4, NVMe |
Form Factor | U.2 15mm |
Capacity (tested) | 15.36 TB |
NAND Technology | 176L TLC 3D NAND |
Observed IOPS (benchmark) | 217,750 random read IOPS |
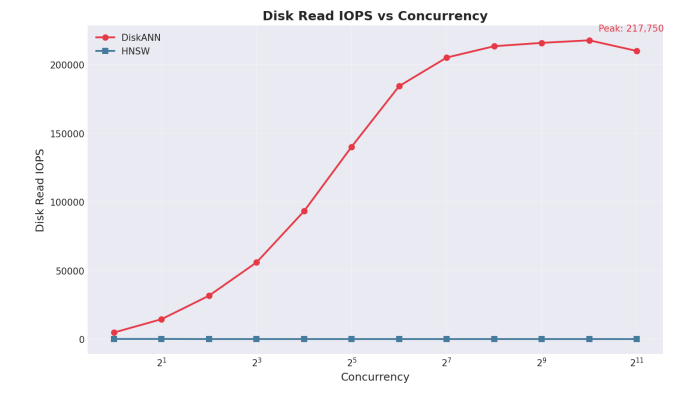
Figure 5 | Disk IOPS vs Concurrency
GPU Pipeline Stability. During high-concurrency testing, the GPU embedding pipeline maintained consistent throughput without observable stalls or backpressure from the retrieval layer. This architectural separation, where DiskANN services queries from SSD rather than competing for DRAM bandwidth, helps prevent the memory contention that can degrade GPU inference performance in DRAM-bound configurations.
What This Means for Infrastructure Planning
These benchmark results point to a clear infrastructure direction: SSD-offloaded vector retrieval eliminates the scaling limitations that DRAM-bound architectures impose on video intelligence deployments.
For IT Directors and Infrastructure Architects, three implications stand out. First, the solution scales to enterprise concurrency without requiring proportional DRAM expansion. Organizations support growing analyst teams and automated workloads by adding storage capacity rather than upgrading to memory-intensive server configurations. Second, latency remains predictable under load. Security operations centers and compliance teams get consistent query response times during incident investigations, even when multiple analysts access the system simultaneously. Third, the architecture maximizes return on existing GPU investments. By eliminating memory contention between embedding generation and retrieval, the platform sustains higher effective GPU utilization throughout continuous video ingestion workflows.
Factor | Guidance |
DRAM (1M vectors) | DiskANN: 26 GB; HNSW: 41 GB |
DRAM (10M vectors) | DiskANN: 66 GB; HNSW: 77 GB |
DRAM (100M vectors) | DiskANN: 116 GB; HNSW: 331 GB |
Concurrent threads tested | 1,024 |
IOPS per thread | ~213 |
DRAM-bound designs served earlier generations of vector search. These benchmarks demonstrate that SSD offload now delivers both the performance and economics required for enterprise-scale deployment.
KV Cache Offload Results
DiskANN with Solidigm D7-PS1010 SSDs eliminates DRAM as a scaling bottleneck for vector retrieval. Infrastructure teams can grow embedding archives from millions to hundreds of millions of vectors without proportional memory expansion. However, modern video intelligence pipelines face a second memory constraint that operates independently: GPU VRAM limitations during LLM inference.
The Memory Challenge in Long-Context Inference
Large language models create a growing memory burden during inference. As the model processes each token, it generates key/value tensors that must remain accessible for the attention mechanism. These tensors accumulate rapidly with longer contexts. A 180,000-token document can consume over 90% of available GPU VRAM, leaving little room for additional queries or concurrent users.
For video intelligence workflows, this constraint creates a real operational bottleneck. Analysts reviewing policy documents, incident reports, and aggregated summaries often work with 150,000 to 200,000 tokens of context. Because a single document of this length already occupies nearly all available GPU VRAM, the system cannot retain KV tensors from previously processed documents in GPU memory for reuse. When analysts switch between documents or return to previously analyzed content, the system must recompute the entire KV cache from scratch. Each context switch forces 30 to 40 seconds of processing delay before the analyst receives a response. Extending the memory hierarchy to include CPU-attached DRAM and NVMe SSD storage creates a path to preserve and retrieve those tensors without re-computation.
This latency compounds across investigative workflows. An analyst cross-referencing three incident reports and two policy documents may wait several minutes just for context loading. The GPU sits idle during SSD reads, while re-computation burns cycles on work the system already completed minutes earlier.
A Tiered Storage Approach
KV cache offload addresses this challenge by extending the memory hierarchy beyond GPU VRAM. Rather than discarding computed key/value tensors when switching contexts, the system preserves them across a three-tier storage architecture managed by the KV cache manager:
- Active tier (GPU HBM/VRAM): Holds currently used tensors for immediate access during inference. The KV cache manager maintains active working set here.
- Warm tier (CPU system memory): Maintains recently accessed contexts in CPU-attached DRAM, enabling rapid restoration without disk I/O. In this test configuration, LMCache allocated 10 GB of CPU RAM for this tier.
- Cold tier (NVMe SSD): Persists all processed contexts on Solidigm D7-PS1010 NVMe SSDs, providing high-capacity storage with consistent retrieval performance. This test allocated 100 GB of SSD storage for cached tensors.
Security Consideration: Cached KV tensors may contain representations of sensitive document content. Organizations should apply appropriate access controls to the SSD storage tier and consider encryption-at-rest for compliance-sensitive deployments. The same data governance policies applied to source documents should extend to cached tensor storage.
When an analyst or an agent returns to a previously processed document, the KV cache manager retrieves the cached tensors from the appropriate storage tier. Depending on recency and access patterns, data may come from CPU memory (warm tier) or SSD storage (cold tier). This eliminates redundant GPU computation and restores full context in seconds rather than tens of seconds.
Test Configuration
Testing evaluated KV cache offload performance using production-representative workloads from the video intelligence platform. The configuration isolated offload benefits by running parallel inference systems on matched hardware.
The test environment used NVIDIA RTX PRO 6000 Blackwell GPUs with 98 GB VRAM each. The baseline system ran vLLM v0.13.0 with standard GPU-only memory management. The offload system added LMCache v0.3.13.dev7, an open-source KV cache management library developed by LMCache.ai, configured on Solidigm D7-PS1010 NVMe storage.
The workload used MegaBeam-Mistral-7B-300k, a model optimized for extended context windows. Test documents represented realistic analyst workflows: Document 1 contained aggregated policy documents and summaries from approximately 50 video ingestions. Document 2 contained incident reports and summaries from a separate set of 50 video ingestions. Each document comprised 180,000 tokens, pushing GPU memory utilization to 95% of available VRAM.
Benchmark Results
Three scenarios measured Time to First Token (TTFT) across different cache states. This metric captures the full latency an analyst experiences before receiving any response from the model.
Scenario | Cache State | Baseline | KV Offload | Performance Delta |
Initial Document Ingestion | Cold (prefill) | 39.22s | 40.23s | ~1.0x |
New Document Ingestion | Cold (prefill) | 43.59s | 44.60s | ~1.0x |
Return to Cached Document | Warm/Cold hit | 39.26s | 1.43s | 27.4x |
The first two scenarios show minimal difference between configurations. When processing new content, both systems perform identical prefill computations. The slight overhead in the offload configuration reflects the additional step of writing computed tensors to SSD storage.
The third scenario reveals the primary benefit. Without KV cache offload, returning to a previously processed document requires full re-computation, taking 39.26 seconds. With SSD-cached tensors, the system retrieves the stored KV data in 1.43 seconds. This 27.4x improvement converts a workflow-breaking delay into an imperceptible pause.
Operational Implications
For security analysts and compliance teams working with video intelligence platforms, KV cache offload significantly changes how multi-document investigation workflows operate.
Consider an analyst reviewing a potential safety violation. They begin with a 180,000-token incident report, ask several questions, then need to reference the relevant policy documentation. Without caching, switching to the policy document and returning to the incident report adds nearly 80 seconds of pure waiting time. With SSD-backed KV cache, that same workflow completes in under 3 seconds of context-switching latency.
The economic case reinforces the operational benefits. GPU VRAM costs significantly more per gigabyte than enterprise NVMe storage. Expanding context capacity through additional GPUs requires significant capital expenditure and increases power and cooling demands. Extending context through SSD offload achieves similar results at a fraction of the infrastructure cost.
Three outcomes define the business value of this capability. First, analysts never reprocess the same document twice during an investigation session. Second, longer context windows become accessible without proportional GPU memory expansion. Third, infrastructure teams gain flexibility to optimize GPU utilization for compute-intensive tasks rather than memory capacity.
KV cache offload delivers significant value for iterative, multi-document workflows. However, infrastructure architects should understand the scenarios where this capability provides limited or no benefit.
First-time document processing shows no improvement. When an analyst or an agent ingests a new document, the system must compute all key/value tensors regardless of storage architecture. The benchmark results confirm this: initial document ingestion takes approximately 40 seconds in both configurations. Workloads consisting primarily of single-pass analysis on unique documents will not benefit from cache offload. The performance results in Scenarios 1 and 2 reflects this reality.
Short context windows reduce the value proposition. KV cache offload addresses memory pressure from long-context inference. Workflows operating within 8,000 to 32,000 tokens typically fit comfortably within GPU VRAM without tiered storage. For these shorter interactions, the overhead of persisting tensors to SSD may outweigh retrieval benefits.
High-churn query patterns limit cache utilization. Environments where analysts rarely return to previously processed content will see minimal gains. Customer service applications handling unique, one-time queries fall into this category. The 27.4x improvement requires cache hits, so workflows with low document revisit rates should evaluate whether offload infrastructure delivers adequate return on investment.
Latency-sensitive first-response workloads may see slight overhead. The benchmarks show initial ingestion with offload takes marginally longer (40.23s vs. 39.22s) due to the additional step of persisting tensors to storage. For applications where first-token latency is the primary optimization target, this overhead, though small, warrants consideration.
Understanding these boundaries helps infrastructure teams right-size their deployments. Organizations with mixed workloads can enable offload selectively, applying it to investigative analysis pipelines while maintaining standard configurations for transactional query workloads.
Summary of Key Findings for KV Cache Offload
The KV cache offload benchmarks demonstrate that Solidigm D7-PS1010 NVMe SSDs enable a practical tiered memory architecture for long-context LLM inference. Initial document processing performs identically to GPU-only configurations. Returning to cached contexts delivers 27.4x faster response times, reducing 39-second delays to sub-2-second retrieval. This capability transforms multi-document analysis workflows from latency-constrained sequences into efficient investigative sessions.
VectorDB Benchmarks
Synthetic Benchmark Context
While the production benchmarks above validate real-world performance, standardized synthetic testing provides additional validation at larger dataset scales. To validate the performance characteristics observed in production workloads, we conducted standardized benchmark testing using VectorDBBench, an open-source tool designed to measure vector database performance and cost efficiency. Testing compared DiskANN (SSD-offloaded indexing) against HNSW (in-memory indexing) using the Solidigm D7-PS1010 NVMe SSD across three industry-standard datasets.
The benchmark configuration used Milvus 2.5.3 as the vector database with 768-dimension embeddings, consistent parameters across both indexing methods, and identical hardware configurations to isolate storage architecture as the primary variable.
Query Throughput and DRAM Efficiency
The table below summarizes performance across increasing dataset scales.
Dataset | DiskANN QPS | HNSW QPS | QPS Lift | DiskANN DRAM | HNSW DRAM | DRAM Reduction |
Cohere 1M | 9,190 | 7,485 | +23% | 26 GB | 41 GB | 37% |
Cohere 10M | 1,270 | 1,035 | +23% | 66 GB | 77 GB | 14% |
LAION 100M | 165 | 131 | +26% | 116 GB | 331 GB | 65% |
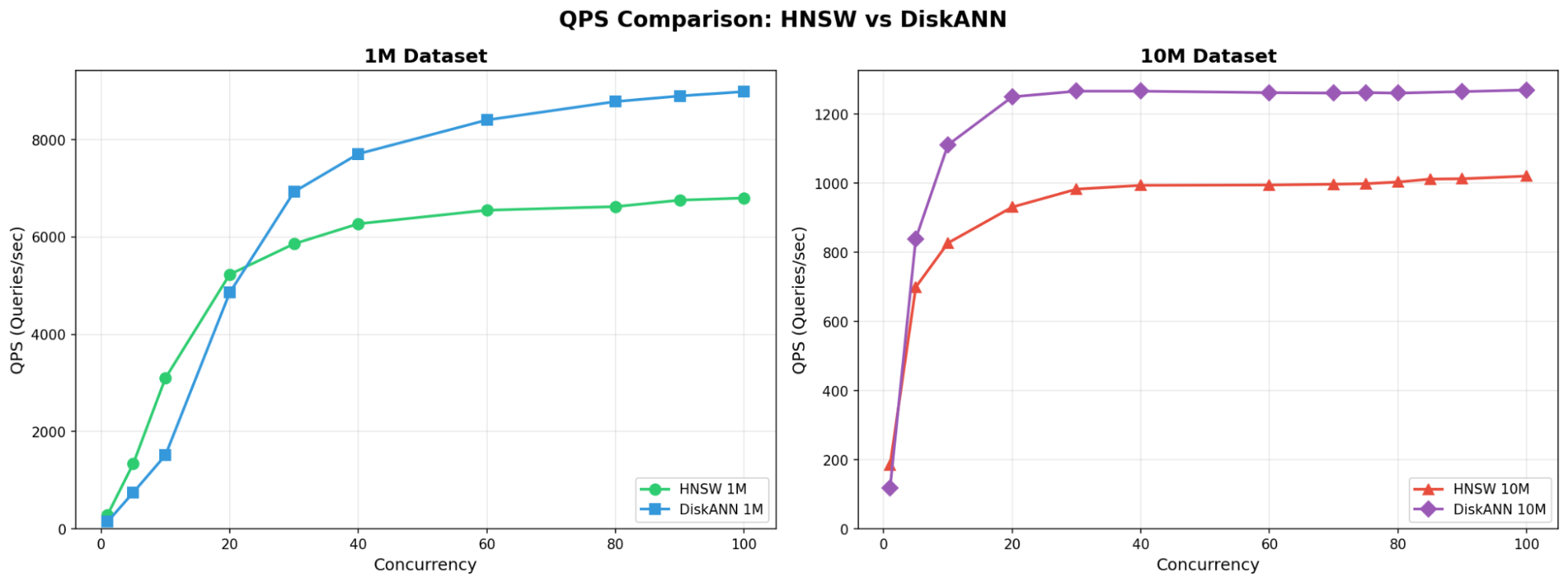
Figure 6 QPS vs Concurrency between HNSW and DiskANN at 1M and 10M
Key observations: DiskANN with Solidigm SSDs delivered 23-26% higher query throughput across all dataset scales. This result challenges the assumption that SSD-based retrieval sacrifices speed for memory efficiency. The Vamana graph algorithm at the core of DiskANN optimizes data placement for sequential I/O patterns, allowing the high-bandwidth D7-PS1010 to sustain throughput that exceeds DRAM-bound configurations.
Memory reduction becomes increasingly significant at scale. At 100 million vectors, DRAM consumption dropped from 331 GB to 116 GB, a 65% reduction. This efficiency enables organizations to deploy production-grade vector search on standard server configurations rather than memory-dense nodes.
Note on DRAM measurements: The 116 GB DiskANN footprint at the 100M scale reflects tuning optimizations applied after Phase 1 testing (which reported 145 GB). DiskANN was re-tuned for large-scale efficiency rather than peak QPS alone. At 100M vectors, those optimizations reduced the in-memory working set and shifted more traversal to SSD without a proportional performance penalty. HNSW, by contrast, has a largely fixed memory footprint once built, so its DRAM usage remained flat. The result is a larger DRAM delta at scale, which reflects DiskANN's architectural flexibility rather than a measurement anomaly.
Recall Accuracy at Scale
Retrieval accuracy remained consistent across both indexing methods. Recall@10 measures the proportion of true top-10 nearest neighbors returned in the query results, using each dataset's standard test query set of 10,000 held-out vectors.
Dataset | DiskANN Recall@10 | HNSW Recall@10 |
Cohere 1M | 97% | 97% |
Cohere 10M | 99% | 97% |
LAION 100M | 99.2% | 98.4% |
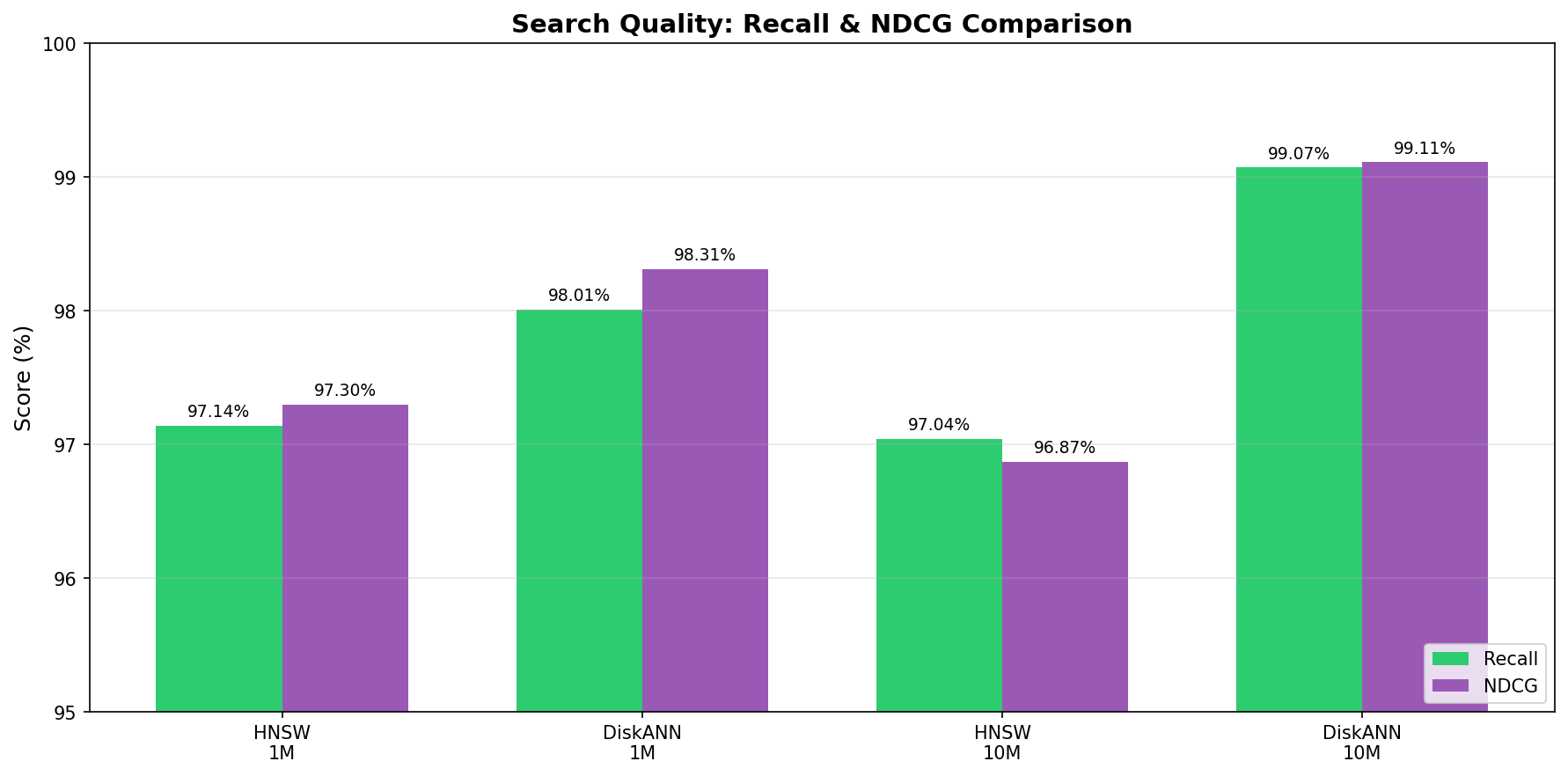
DiskANN maintained recall above 99% at the 100M scale, slightly exceeding HNSW accuracy. This demonstrates that SSD offloading does not compromise search quality. For production AI applications where retrieval precision directly affects user experience and analytical accuracy, these results confirm that cost optimization does not require quality tradeoffs.
Cost Efficiency Analysis
Infrastructure economics favor SSD-offloaded architectures at scale, and this advantage has grown as DRAM prices escalate. At 100 million vectors, we measured queries per second per dollar (QPS/$) for DRAM and SSD components using January 2026 market pricing.
Configuration | QPS | CapEx (Hardware Cost) | QPS per Dollar | Delta |
HNSW (DRAM-bound) | 126 | $5,170[3] | 0.024 | Baseline |
DiskANN (SSD-offload) | 186 | $2,890[4] | 0.064 | +48% Throughput, 44% Lower Cost |
Note: Infrastructure costs represent capital expenditure (CapEx) for memory and storage hardware. Operational expenses such as power, cooling, and maintenance are not included in this comparison.
At the 100-million vector scale, DiskANN with Solidigm D7-PS1010 SSDs delivered 48% higher query throughput while reducing memory tier costs by 44% compared to DRAM-bound HNSW configurations.
These per-node savings compound across multi-server deployments. Our TCO modeling shows that SSD offloading reduces total hardware costs by 13% per server (excluding GPU) by enabling a shift from 24 RDIMM slots to 12 RDIMM slots. For a 10-node deployment at current DRAM prices, this represents more than $23,000 in capital reallocation toward additional compute capacity or archive expansion.
As AI-driven demand continues to pressure server memory prices, this advantage grows with each refresh cycle
Indexing Time Considerations
DiskANN's performance advantages come with a trade-off: longer initial index construction.
Dataset | HNSW Index Time | DiskANN Index Time | Difference |
Cohere 1M | 616 seconds | 807 seconds | +31% |
Cohere 10M | 5,342 seconds | 8,430 seconds | +58% |
LAION 100M | 56,143 seconds | 89,805 seconds | +60% |
At the 100M vector scale, DiskANN requires approximately 25 hours to build its index compared to 15.6 hours for HNSW. This difference reflects the Vamana algorithm's additional preprocessing work to optimize data placement for sequential I/O patterns. The same structural optimizations that enable faster query throughput require more computation during index construction.
When this trade-off matters. Organizations with high-frequency reindexing requirements should factor this cost into capacity planning. Use cases involving continuous index rebuilds, such as hourly full refreshes or frequent schema changes, will experience cumulative overhead.
When this trade-off is acceptable. For most enterprise video intelligence deployments, index construction is infrequent. Video archives grow through incremental ingestion rather than bulk reprocessing.
Current index update limitations. The Milvus DiskANN implementation tested in this benchmark requires full index rebuilds when adding new vectors. Incremental index updates are not currently supported. Organizations should plan for periodic rebuild windows during low-traffic periods when ingesting new content at scale. Microsoft Research has developed FreshDiskANN to address this limitation, enabling efficient incremental updates. As this capability matures and integrates into production vector databases, operational flexibility will improve significantly.
Infrastructure teams should evaluate their specific update patterns when selecting an indexing strategy. Deployments with stable or incrementally growing archives benefit most from DiskANN's operational advantages.
Benchmark Summary
Standardized testing validated three core findings from production workloads:
- Throughput advantage: DiskANN with Solidigm D7-PS1010 SSDs achieved 23-26% higher QPS across dataset scales from 1M to 100M vectors.
- Memory efficiency: DRAM consumption decreased by up to 65% at the 100M scale without sacrificing recall accuracy.
- Cost optimization: Infrastructure efficiency improved by more than 2x when measuring QPS per dollar, with TCO reductions of approximately 13% on hardware costs.
These results reinforce the production benchmark findings: SSD-offloaded vector retrieval enables organizations to scale AI workloads without proportional memory investment, while maintaining the throughput and accuracy required for enterprise deployment.
Summary
As video archives grow and AI workloads intensify, DRAM-bound retrieval architectures face a practical ceiling. Memory costs escalate, throughput degrades under concurrent load, and organizations risk slower investigations, missed incidents, and compliance gaps. This whitepaper demonstrates that SSD-offloaded architectures built on Solidigm D7-PS1010 NVMe SSDs offer a validated path forward. By shifting from memory-constrained designs to storage-optimized infrastructure, enterprises can scale video intelligence capabilities without proportional increases in hardware complexity or cost.
DiskANN Vector Retrieval: Key Takeaways
- 14% higher throughput at production scale. Testing on 3,000 minutes of video achieved 2,371 QPS at 1,024 concurrent threads, outperforming in-memory HNSW indexing.
- Up to 65% reduction in DRAM requirements. Synthetic benchmarks at 100 million vectors reduced memory consumption from 331 GB to 116 GB.
- 23 to 26% higher QPS across all dataset scales. Performance gains held consistent from 1 million to 100 million vectors.
- 2x improvement in infrastructure cost efficiency. Organizations achieve higher queries per dollar by shifting retrieval workloads to NVMe storage.
- Sustained 217,750 IOPS without performance degradation. The Solidigm D7-PS1010's PCIe 5.0 interface handled DiskANN's intensive random read workload while delivering lower latency than DRAM-bound configurations.
- Index build time trade-off. DiskANN requires 30-60% longer initial indexing compared to HNSW. This one-time cost enables the algorithm's I/O-optimized data placement that delivers sustained query performance advantages.
KV Cache Offload for Long-Context LLM Inference: Key Takeaways
- 27.4x faster context switching. Returning to previously processed documents drops from 39 seconds to 1.43 seconds when retrieving from NVMe storage. Retrieval from the CPU-attached DRAM tier delivers sub-second restoration for recently accessed contexts, completing the hierarchical memory architecture.
- Persistent cache across system events. SSD-stored KV tensors survive system reboots and service restarts, enabling analysts to resume multi-document investigations without recomputing previously processed content. This persistence transforms ephemeral GPU memory into durable analytical context.
- Zero re-computation for cached contexts. Analysts never reprocess the same document twice during an investigation session.
- No penalty for initial document processing. First-time ingestion performs identically to GPU-only configurations.
- 80+ seconds saved per multi-document workflow. Investigators cross-referencing incident reports and policy documents experience minimal latency overhead.
- Lower GPU memory pressure. Tiered storage extends context capacity without proportional VRAM expansion.
For IT leaders evaluating their next infrastructure investment, this architecture offers a practical blueprint. Organizations ready to move beyond memory-bound constraints can explore reference designs, access the open-source solution repository, or engage Solidigm solution architects to assess deployment options tailored to their video analytics and multimodal AI requirements.
References
[1] S. J. Subramanya et al., "DiskANN: Fast accurate billion-point nearest neighbor search on a single node," in Advances in Neural Information Processing Systems (NeurIPS), 2019. [Online]. Available: https://github.com/microsoft/DiskANN
[2] Milvus, "Milvus vector database documentation," Milvus Project. [Online]. Available: https://milvus.io/docs
[3] NVIDIA, "NVIDIA NIM documentation," NVIDIA Corp. [Online]. Available: https://docs.nvidia.com/nim
[4] vLLM Project, "vLLM documentation," [Online]. Available: https://docs.vllm.ai
[5] LMCache Project, "LMCache GitHub repository," [Online]. Available: https://github.com/LMCache/LMCache
[6] Solidigm, "Solidigm D7-PS1010 PCIe Gen5 NVMe SSD product brief," Solidigm. [Online]. Available: https://www.solidigm.com/products/data-center/d7/ps1010.html
[7] Omdia, "Video surveillance & analytics database report," 2022, cited in Electronic Security Association, "100 million cameras - AI and video are changing the edge," Apr. 2022. [Online]. Available: https://esaweb.org/100-million-cameras-ai-and-video-are-changing-the-edge/
[8] MarketsandMarkets, "Video surveillance market report," 2025, cited in Camius, "AI IP security camera statistics 2025," Dec. 2025. [Online]. Available: https://www.camius.com/blog/ai-ip-security-camera-statistics-2025/
[9] Intel Market Research, "Video surveillance storage device market outlook 2025-2032," 2025. [Online]. Available: https://www.intelmarketresearch.com/download-sample/1106/video-surveillance-storage-device-2025-2032-409
[10] Counterpoint Research, "Advanced memory prices likely to double as DRAM crunch spreads on Nvidia pivot, structural factors," Nov. 19, 2025. [Online]. Available: https://counterpointresearch.com/en/insights/advanced-memory-prices-likely-to-double-as-dram-crunch-spreads-on-nvidia-pivot-structural-factors/
[11] EE Times, "AI to drive surge in memory prices through 2026," Nov. 20, 2025. [Online]. Available: https://www.eetimes.com/ai-to-drive-surge-in-memory-prices-through-2026/
[12] G. Swain, "Server memory prices could double by 2026 as AI demand strains supply," Network World, Nov. 20, 2025. [Online]. Available: https://www.networkworld.com/article/4093752/server-memory-prices-could-double-by-2026-as-ai-demand-strains-supply.html
[13] TrendForce, "Memory spot price update: DDR5 prices up 307% since September as module costs poised to surge," Nov. 19, 2025. [Online]. Available: https://www.trendforce.com/news/2025/11/19/insights-memory-spot-price-update-ddr5-prices-up-307-since-september-as-module-costs-poised-to-surge/
[14] Tom's Hardware, "DRAM prices skyrocket 171% year-over-year, outpacing the rate of gold price increases," Nov. 4, 2025. [Online]. Available: https://www.tomshardware.com/pc-components/dram/dram-prices-surge-171-percent-year-over-year-ai-demand-drives-a-higher-yoy-price-increase-than-gold
Copyright © 2026 Metrum AI, Inc. All Rights Reserved. This project was commissioned by Solidigm. Solidigm and other trademarks are trademarks of Solidigm or its subsidiaries. NVIDIA and related marks are trademarks of NVIDIA. All other product names mentioned are the trademarks of their respective owners.
***DISCLAIMER - Performance varies by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance.
[1] Omdia, cited in Electronic Security Association, "100 Million Cameras - AI and Video are Changing the Edge," April 2022; MarketsandMarkets, "Video Surveillance Market Report," 2025.
[2] Intel Market Research, "Video Surveillance Storage Market Outlook," 2025.
[3]HNSW infrastructure cost: 331 GB DDR5 RDIMM at ~$12/GB. Counterpoint Research, "Advanced Memory Prices Likely to Double," November 2025; TrendForce, "Memory Spot Price Update," November 2025.
[4] DiskANN infrastructure cost: 116 GB DDR5 RDIMM at ~$12/GB plus Solidigm D7-PS1010 NVMe SSD. Counterpoint Research, "Advanced Memory Prices Likely to Double," November 2025.