Executive Summary
Enterprise agentic workloads are quietly paying for the same work twice. As an autonomous agent reasons across dozens of rounds, its Key-Value (KV) cache grows until it overflows GPU memory, forcing the GPU to recompute context it has already produced and inflating the price of every token. The HPE ProLiant Compute DL380a Gen12 with Intel Xeon 6787P processors removes that waste by putting the server's full memory hierarchy to work. The GPUs hold active context and stay fully engaged, while CPU DDR5 DRAM and KIOXIA NVMe SSDs persist the overflow and reload it on demand, catching what the GPU cannot hold on one integrated server.
The server's capital cost is the same regardless of how its memory is configured, so the price per token is set largely by how many tokens that fixed cost produces. Benchmarked by Metrum AI with HPE and Intel on real agentic traces, activating the CPU DRAM layer reduced the price per million tokens by 2.7x at 256 concurrent users, with the GPUs unchanged. Measured against a 300-second TTFT service-level target, the same server sustains 4x more concurrent agents before exceeding that SLA, lowering the cost per served agent by 4x at no additional hardware cost.
At extreme scale the story shifts to NVMe. When concurrency reaches 512 users, the allocated 1,024 GB DRAM working set fills, its cache hit rate collapses, and its cost per token climbs back toward GPU-only levels. The NVMe layer does not saturate: it sustains a 75.5% hit rate and holds the price near $13.34 per million tokens, 2.4x cheaper than GPU-only at the same scale. The result is a single server whose three memory layers each own a different operating regime, with no GPUs added or removed.
Key Results at a Glance
All figures are measured on a single HPE ProLiant Compute DL380a Gen12 running Qwen3-235B-A22B-FP8 at 256 concurrent users with 25 rounds per session, and at 512 users where scale changes the conclusion.
$11.38 Per 1M Tokens DRAM layer active, vs $30.30 GPU cache only (256 users) |
2.7x Lower Price per Token Same server, full cost incl. GPUs, DRAM layer activated |
4x More Agents Within SLA 32 to 128 concurrent users at a 300 sec TTFT target |
2.7x Better Energy Efficiency 0.033 to 0.090 tokens per joule at 256 users |
$13.34 Per 1M Tokens at 512 Users NVMe layer, vs $24.14 DRAM (saturated) and $31.72 GPU only |
0 GPUs Added or Removed The GPU and its KV cache stay fully active throughout |
The Hidden Cost of Agentic AI at Scale
Generative AI value is increasingly judged by the cost-effectiveness of inference rather than the choice of model. As agentic workloads scale, the measure of success shifts from model accuracy to the efficiency of the serving stack. Every second a GPU spends reprocessing context it has already seen is a second not spent generating value.
Agentic workloads make this problem acute. A conventional chat request is short and single-turn. A prompt arrives, the model prefills it, decodes a response, and the session ends. Agentic workloads invert almost every property of that model:
Multi-round. Each session runs many rounds. Coding agents iterate over a task, calling tools, reading results, and revising. Representative coding traces show mean session lengths well into the hundreds of rounds.
Long and growing context. Context grows monotonically. Every tool result, file read, and reasoning step is appended, so the KV cache for a single session expands turn over turn until it dominates VRAM.
High reuse. Each new turn adds a small amount of fresh text on top of a large reused prefix. That pattern produces very high cache-hit potential and shifts the workload from compute-bound to I/O-bound.
Host-bound phases. The GPU idles during tool execution. Retrieval, code execution, web fetches, and tokenization run on or are orchestrated by the host CPU, creating substantial GPU idle time within every round.
The CPU-centric reality of agentic serving
This last property is the one most benchmarks ignore. Recent work from Intel and Georgia Tech characterizes agentic execution from the host side and finds the CPU to be a first-order bottleneck rather than a supporting actor. For retrieval-augmented pipelines, nearest-neighbor retrieval alone consumes 81 to 89% of end-to-end latency.
The implication for infrastructure is direct. A serving architecture tuned only for GPU FLOPs leaves the accelerator stalled while the host works. The path to higher effective utilization runs through faster context retention and retrieval, which is exactly what KV cache offload to DRAM and NVMe provides.
The on-premises imperative
Security and IP control. Agents require deep access to proprietary code and sensitive data, so on-premises deployment keeps intellectual property behind the corporate firewall under strict access control.
Predictable economics. Agent workflows can generate volatile, runaway token costs because of large context windows. On-premises infrastructure converts unpredictable per-token operating expense into controlled, fixed capital expense.
Unrestricted leverage. With per-token cost anxiety removed, engineering teams can scale large swarms of autonomous agents for continuous integration and deep codebase modernization without metering each call.
These pressures put the server's memory hierarchy at the center of the deployment decision. The question is not whether to buy a GPU, since every agent deployment needs one. It is how to allocate the rest of the server's memory, and when to activate each layer, to hold the price per million tokens down at a given concurrency and SLA target.
What Happens When the KV Cache Outgrows GPU Memory
Every large language model builds an attention state called the KV cache as it processes context. During prefill, the model computes the per-layer key and value tensors for every token in the prompt, a compute-bound step. During decode, the model reuses those cached tensors to generate each new token, a memory-bandwidth-bound step.
In agentic workflows, the agent returns to the same conversation turn after turn, and each turn extends the cache. The GPU is essential to all of this, and it remains fully active in every configuration.
The constraint is structural. GPU VRAM, the fastest memory in the server, is shared between two demands: holding the model weights, a fixed cost, and storing the KV cache for active sessions, a variable cost that grows with users and context length.
The model under test, Qwen3-235B-A22B-FP8, is loaded at FP8 precision: a sparse mixture-of-experts design with 22 billion parameters active per token out of 235 billion total. Loading those weights at FP8 consumes roughly 235 GB of the four NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs' 384 GB of combined VRAM, leaving approximately 149-157 GB for the KV cache.
FP8 is what allows a 235-billion-parameter model to fit on four professional-class 96 GB cards at all, and it directly sets the KV budget: at the SWE-bench session average of ~37,000 tokens, that budget fills at roughly 44-47 concurrent users.
When the server runs the GPU KV cache alone, with no other memory layer activated, the engine must evict sessions above that point to admit new ones. When an evicted session resumes on its next turn, the engine recomputes its entire context from scratch before producing a single output token. That recomputation consumes GPU cycles that could have generated tokens for other users.
The system then enters a spiral: more users drive more evictions, more evictions drive more recomputation, and more recomputation drives longer waits, which keep still more sessions active at once.
The benchmark makes the consequence concrete. At 256 concurrent users, running the GPU cache alone, TTFT degraded +496% from round 1 to round 25 (195.9 sec to 1,168.0 sec, a 6.0x worsening) as VRAM filled and the GPU reprocessed context it had already handled. At 512 users the same collapse reaches +524%.
This is not a fault of the GPU, which is doing useful work the entire time. It is the result of serving a long-context workload from a single memory layer that is too small for the working set. The fix is to give the cache more of the memory the server already contains.
Persist the Work, Skip the Recompute
The KV cache does not have to live only in GPU VRAM. The same server already contains a deeper memory hierarchy, and the inference engine can use all of it.
The GPU and its KV cache remain fully active. Beneath them, the server's CPU DDR5 DRAM and NVMe SSD act as additional KV layers that persist computed tensors instead of discarding them. When a session resumes, the engine reloads its cache from the nearest layer that holds it rather than recomputing it on the GPU, which removes the prefill penalty for cache hits.
The HPE ProLiant Compute DL380a Gen12 with Intel Xeon 6787P processors is built for exactly this. Rather than forcing the GPU to discard evicted KV blocks, LMCache catches them and stages them into the next memory layer. The three layers work as one system, and each maps cleanly onto how an enterprise agent uses memory.
| Infrastructure Layer | Agent Function | Representative Workloads |
|---|---|---|
| GPU VRAM | Active reasoning | Code generation, bug fixing, pull-request review |
| CPU DRAM | Working memory | Repository analysis, vulnerability triage, agent orchestration |
| NVMe SSD | Organizational memory | Enterprise code search, remediation history, shared knowledge |
Table 1 | The enterprise agentic memory hierarchy
Enterprise agent scalability is set by the whole server working together: reasoning capacity on the GPU, working-memory capacity in DRAM, and context capacity on NVMe. Traditional inference flows from model to GPU to response. Agentic inference flows from knowledge to storage to memory to GPU to action, so how many concurrent agents a server sustains within SLA depends on every layer of its memory hierarchy, not the GPU acting alone.
Intel Xeon 6787P: the reason the DRAM layer works
The DRAM layer that carries this benchmark works because of the host. Two Intel Xeon 6787P processors, with 86 cores per socket and a 16-channel DDR5 subsystem, supply the aggregate memory bandwidth that turns CPU DDR5 into a high-performance KV layer. This is the practical realization of the CPU-centric thesis that agentic serving is host-bound.
The 2,048 GB of installed DDR5 holds the working set, and the dual-socket topology stages KV blocks at speed across PCIe Gen5 to the GPUs, which stay active throughout. Each Intel Xeon 6787P socket provides 88 PCIe Gen5 lanes, giving the dual-socket platform 176 total lanes to carry KV blocks between host memory and the four GPUs.
Intel Advanced Matrix Extensions (AMX) built into each processor accelerate the prefill compute that runs when a cache miss forces full context reprocessing. The power and energy figures throughout this paper are measured using Intel RAPL package telemetry, which is standard in every Intel Xeon 6 processor.
Across all 27 test cells, Intel Xeon 6787P CPU utilization never exceeded 2.7%, confirming that the throughput gains come from memory tiering, not additional CPU compute.
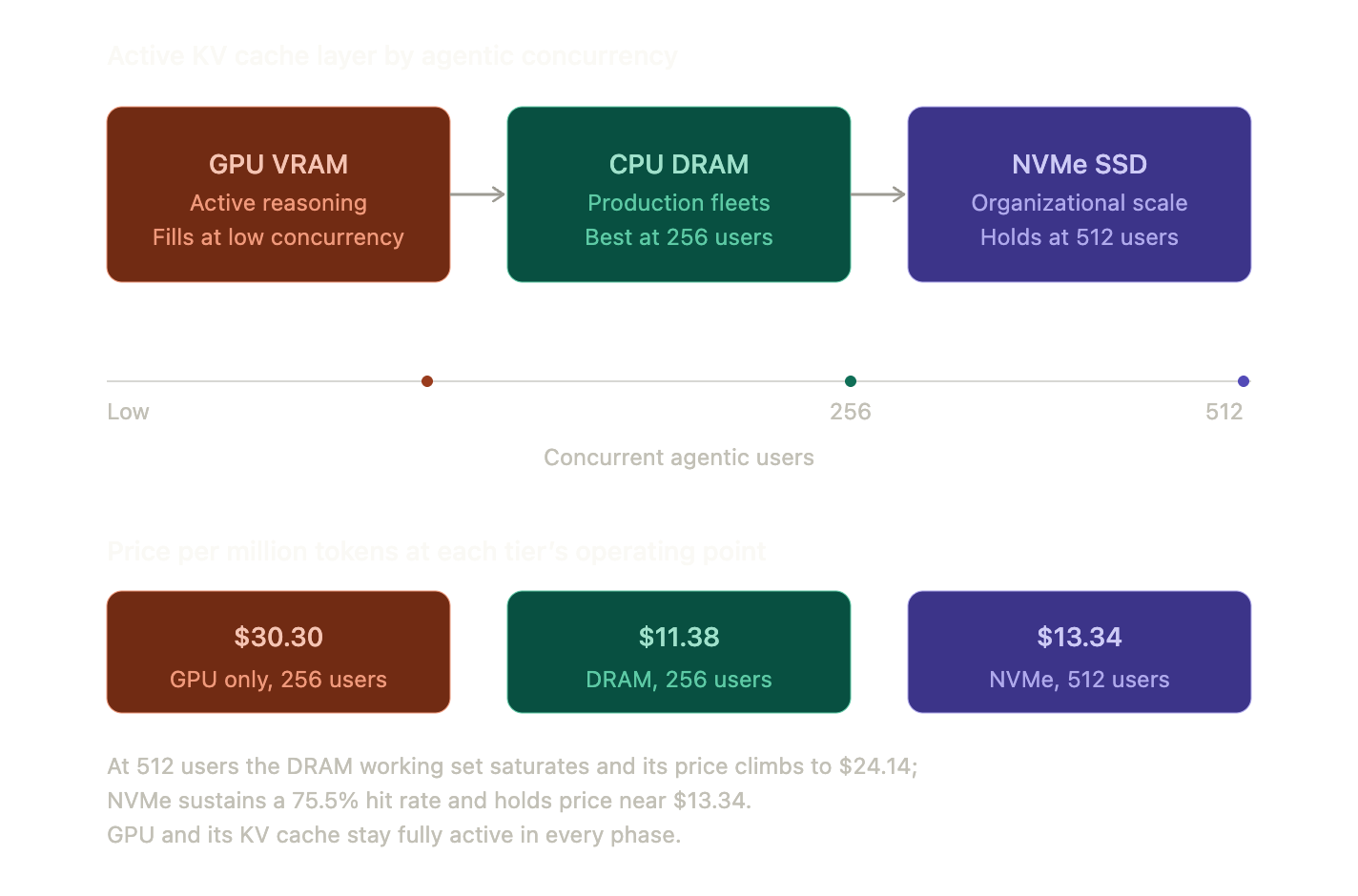
Figure 1 | The active KV cache layer shifts across the memory hierarchy as agentic concurrency rises
Tokenomics: The Price per Million Tokens
Infrastructure decisions for AI inference are often made on server price, GPU count, or peak throughput. None of those answer the question a budget owner actually asks: what does it cost to produce one token of AI output at a given operating scale?
Price per million tokens, the tokenomics of the deployment, collapses hardware, power, utilization, and throughput into a single number that a VP of Engineering can defend in a budget review. It is the metric HPE and Intel customers care about most, and it is where activating the server's full memory hierarchy changes the math.
How to read these cost numbers
Each cost figure reflects the complete HPE ProLiant Compute DL380a Gen12 server, with all four GPUs installed and active, in all three configurations. The comparison is not GPU versus DRAM versus SSD as if they were alternatives. It is the same server, at the same hourly cost, running its GPU KV cache alone, then with the DRAM layer activated, then with the NVMe layer activated. The GPUs and their KV cache stay on the entire time. What changes is how many tokens the server produces for the dollars it already costs.
The server costs the same to own regardless of how its memory hierarchy is configured. What changes is how many tokens that fixed cost produces. Because price per token is server cost divided by tokens generated, the measured 2.7x throughput gain from activating the DRAM layer at 256 users is also a 2.7x reduction in price per token. The enterprise pays effectively the same hourly rate and receives 2.7 times the output.
Price per million tokens at 256 concurrent users
| Concurrency | GPU Cache Only | + CPU DRAM Layer | + NVMe Layer |
|---|---|---|---|
| 8 | $16.85/1M | $16.93/1M | $16.36/1M |
| 16 | $18.09/1M | $14.81/1M | $15.00/1M |
| 32 | $26.23/1M | $12.84/1M | $13.24/1M |
| 128 | $28.99/1M | $11.95/1M | $13.20/1M |
| 256 | $30.30/1M | $11.38/1M (best) | $12.76/1M |
Table 2 | Price per million tokens across the full concurrency sweep
Below 16 users, all three tiers cost about the same because the GPU is not yet saturated. Above 16 users the offload tiers pull decisively ahead. At 256 users the CPU DRAM layer reaches its best price, $11.38 per million tokens, a 2.7x reduction against GPU-only.
At 512 users the DRAM working set fills and its price climbs to $24.14, more than double its $11.38 best at 256 users, while NVMe holds at $13.34.
Price per token is derived from measured throughput and an estimated full-server operating cost of roughly $5.10 per hour, within about $0.02 across configurations because node power differs only slightly. The figure assumes three-year hardware amortization at 70% utilization plus power at $0.10 per kilowatt-hour. The hardware component is $90,000 divided by 18,396 effective hours (3 years x 8,760 hours x 70%), or about $4.89 per hour, with roughly $0.21 per hour of power added on top.
The server cost, GPUs included, is identical in every row. Only the denominator, tokens produced, moves. The HPE ProLiant Compute DL380a Gen12 used in this benchmark carries an estimated cost of approximately $90,000. That capital cost is fixed regardless of which memory layers are active, so the primary variable that changes the price per million tokens is how many tokens that fixed cost produces.
Where to add KV capacity within the server
When an agent fleet needs more KV capacity than GPU memory holds, the server offers two further layers to absorb it, and the cost of capacity differs sharply between them.
| Capacity Tier | Market Cost per GB (est.) | Relative KV Capacity per Dollar |
|---|---|---|
| GPU VRAM (HBM) | ~$104 | 1x (baseline) |
| CPU DDR5 DRAM | ~$2.73 | ~37x more |
| NVMe SSD | ~$0.16 | ~640x more |
Table 3 | Cost of added KV capacity by layer, market estimate
For the same budget that buys a fixed amount of additional GPU memory, the DRAM layer holds tens of times more KV capacity and the NVMe layer holds hundreds of times more. That ratio, not any single price point, is what makes it economical to extend the cache into DRAM and NVMe rather than sizing the whole working set into GPU memory.
How to Allocate the Server's Memory for Your Workload
The deployment question is not whether to buy a GPU, since every agent server needs one. It is how to allocate the rest of the server's memory, and which layers to activate, for a given workload. The data answers three practical cases.
Light, low-concurrency work. Below roughly 32 concurrent users, where the GPU KV cache approaches capacity and TTFT begins to compound round over round, a developer running small tasks can use the GPU layer alone. Activating offload adds around 3 to 4 percent overhead at the very lowest concurrency levels and is negligible above four users, because the GPU is not yet under pressure.
Production agent fleets. Once concurrency fills GPU memory, activating the DRAM layer lowers price per token 2.7x at 256 users while the GPUs keep running. This is the operating point most enterprise deployments live in, and where the integrated server earns its cost.
Organizational scale and persistence. When the working set exceeds DRAM, when concurrency reaches 512 users, or when KV cache must persist across restarts and be shared across nodes, the NVMe layer holds price per token near $13.34 while DRAM has already saturated. NVMe is the only tier that meets a 900-second SLA at 512 concurrent users.
The configurations at a glance
| Same Server, 256 Users | GPU Cache Only | + CPU DRAM Layer | + NVMe Layer |
|---|---|---|---|
| KV Persistence | Volatile, evicts | Persistent | Persistent |
| Added KV Capacity | GPU memory only | ~1,097 GiB consumed (of 2,048 GB installed) | 15 TB NVMe allocated (~125 GiB DRAM buffer) |
| Avg TTFT at 256 Users | 839.5 sec | 307.1 sec | 348.3 sec |
| Throughput at 256 Users | 47 tok/s | 124.9 tok/s | 111.1 tok/s |
| Price per 1M Tokens (est.) | ~$30.30 | ~$11.38 | ~$12.76 |
| External Cache Hit Rate | n/a | 75.5% | 76.2% |
| GPU Energy per Token | baseline | 63% less (2.7x) | 63% less (2.7x) |
Table 4 | Memory configurations compared at 256 concurrent users. The DRAM row reports the measured KV working set (~1,097 GiB) consumed at this operating point, not the 2,048 GB installed; the full 2,048 GB only fills at 512 users, where DRAM saturates.
At Extreme Scales, NVMe Becomes the Right Layer
The DRAM layer is the right default for production concurrency, but it has a ceiling, and the benchmark finds it.
At 512 concurrent users, the working set exceeds the 1,024 GB allocated DRAM budget (configured to leave the remaining 1 TB of host memory available for OS and agent orchestration). Once it is full, LMCache cannot keep the working set resident, the external cache hit rate collapses from 75.5% to 23.7%, and the DRAM tier begins recomputing context just as the GPU-only configuration does. Its throughput falls to 59.0 tok/s, its TTFT rises to 1,294 sec, and its price per million tokens climbs to $24.14, more than double its best of $11.38 at 256 users, and no longer a compelling cost advantage over the $31.72 of GPU-only at the same scale.
The NVMe layer does not have this ceiling. The inference engine was allocated 15 TB of the KIOXIA SSD array, easily absorbing the full working set while leaving over 15.7 TB of high-speed NVMe storage free for local RAG indices or vector databases, and it sustains a 75.5% external hit rate at 512 users, the same hit rate DRAM held at 256. The consequences are decisive:
| Metric (512 Users) | GPU Cache Only | + CPU DRAM | + NVMe |
|---|---|---|---|
| Mean TTFT | 1,725.8 sec | 1,294.2 sec (1.3x) | 717.1 sec (2.4x faster) |
| Wall-clock, same 12,800 requests | 12.67 h | 9.58 h | 5.34 h (2.4x faster) |
| Throughput | 44.9 tok/s | 59.0 tok/s | 106.3 tok/s (2.4x) |
| External Cache Hit Rate | 0% | 23.7% saturating | 75.5% sustaining |
| Price per 1M Tokens | $31.72 | $24.14 | $13.34 |
| Energy Efficiency | 0.031 tok/J | 0.041 tok/J | 0.083 tok/J (2.7x) |
| DRAM Consumed | ~58 GiB | ~1,097 GiB | ~125 GiB (9x less) |
Table 5 | Memory configurations compared at 512 concurrent users
The NVMe tier completes the same 12,800-request enterprise workload in 5.3 hours, against 12.7 hours for GPU-only and 9.6 hours for a saturated DRAM tier, and it does so while consuming only ~125 GiB of DRAM, a 9x smaller DRAM footprint than the DRAM tier itself.
Storage hardware is nowhere near the limit: the KIOXIA drives peak at 15.7% utilization with 84% headroom, and the binding ceiling is PCIe Gen5 transfer, not SSD bandwidth or IOPS.
At extreme scale, capacity is the deciding factor, not reload latency, and NVMe is the tier that supplies it.
SLA-based capacity: where the 4x lives
| TTFT SLA | GPU Cache Only | + CPU DRAM | + NVMe |
|---|---|---|---|
| 30 sec | 16 users | 32 users (2x) | 32 users (2x) |
| 300 sec | 32 users | 128 users (4x) | 128 users (4x) |
| 900 sec | 256 users | 256 users | 512 users |
Table 6 | Maximum concurrent agents served within each TTFT target
At a 300-second SLA, the operating point of most production agent fleets, activating an offload layer takes the same server from 32 to 128 concurrent agents, a 4x increase in served capacity with no added GPUs. The effective cost falls from $0.160 per agent per hour to $0.040, a 4x reduction.
For long-running background tasks such as nightly repository analysis, continuous security scanning, or large-scale refactoring jobs, a 900-second SLA is both practical and standard. At that target, NVMe is the only tier that serves all 512 concurrent agents within the window.
Benchmark Methodology
The methodology rests on a single principle: the serving configuration influences TTFT more than the storage tier does, so the configuration is locked identically across all three scenarios and the offload tier is the only variable that changes. That discipline separates a defensible benchmark from a marketing number.
System under test
| Component | Specification |
|---|---|
| Server | HPE ProLiant Compute DL380a Gen12 |
| CPU | 2x Intel Xeon 6787P, 86 cores per socket |
| Memory (DRAM) | 16x 128 GB DDR5 RDIMM at 5600 MT/s, 8 channels per socket, 2,048 GB total |
| GPU | 4x NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs, 96 GB VRAM each, 384 GB total, no NVLink |
| GPU Interconnect | PCIe Gen5 x16 per card, roughly 64 GB/s host to device |
| Storage (data) | 2x KIOXIA 15.36 TB NVMe in RAID-0, 30.72 TB usable; 1x 480 GB NVMe boot |
| OS and Kernel | Ubuntu 24.04.3 LTS, kernel 6.8.0-71-generic |
| Driver and CUDA | NVIDIA driver 610.43.02, CUDA 13.3 |
| Inference Stack | vLLM 0.22.0, LMCache 0.4.6, PyTorch 2.11.0 (cu130), Python 3.12.3 |
Table 7 | System under test
The two Intel Xeon 6787P processors and the 16-channel DDR5 subsystem are not incidental to the design. The CPU DRAM layer depends on high aggregate host memory bandwidth to stage KV blocks at speed, and the dual-socket topology directly shapes the result. Each socket contributes 88 PCIe Gen5 lanes and Intel AMX support, giving the platform both the transfer bandwidth and the host-side compute headroom that KV offload requires at scale.
Agentic workload
The workload is replayed from real agentic conversation traces rather than generated synthetically, which is the reason the results transfer to production. Output length was fixed at 512 tokens per round across all runs, while input context accumulated turn over turn.
| Parameter | Value |
|---|---|
| Dataset | sammshen/lmcache-agentic-traces (Hugging Face) |
| Source Tasks | SWE-bench Verified, GAIA, WildClawBench: software engineering, debugging, reasoning |
| Scale | 787 sessions, 24.9K LLM interactions |
| Benchmark Tool | LMCache multi_round_qa.py |
| Rounds per Session | 25, with context accumulating each round |
| Output Tokens | Fixed at 512 per round (input not capped) |
| Concurrency Sweep | 1, 2, 4, 8, 16, 32, 128, 256, 512 |
| Arrival Model | Closed-loop (fixed concurrency) |
| Rigor | 3 or more runs per cell; mean reported with 95% confidence interval |
Table 8 | Agentic workload
Configurations under test
All three configurations run on the same server with the GPUs installed and active. They differ only in which memory layers the inference engine is allowed to use for KV cache.
| Configuration | Memory Layers Active | What It Establishes |
|---|---|---|
| GPU cache only | GPU VRAM prefix cache | The server uses its GPU KV cache alone. Sets the reference and the concurrency at which eviction begins. |
| + CPU DRAM layer | GPU plus CPU DDR5 via LMCache | Overflow blocks persist in DDR5. Tests whether the DRAM layer removes degradation and sizes the memory needed for flat TTFT. |
| + NVMe layer | GPU plus DRAM plus NVMe via LMCache | Blocks stage from GPU to DRAM to NVMe. Establishes price-performance and whether IOPS or PCIe binds at scale. |
Table 9 | Memory configurations under test
Between runs, the cache in all layers is cleared and the server is restarted before any concurrency change, so cross-run contamination cannot inflate hit rate. GPU clocks are locked and the box is single-tenant during steady-state windows, which removes boost and thermal variance from the comparison.
Performance Results Behind the Economics
Results are reported for Qwen3-235B-A22B-FP8 at 256 concurrent users with 25 rounds per session, the operating point where the memory layers are fully exercised, with the 512-user point shown where it changes the conclusion.
Time to first token
The sessions measured here run 25 rounds with context windows averaging 37,000 tokens under closed-loop load at production concurrency. These are background workloads such as repository analysis, code modernization, and security audits where latency is measured by SLA compliance across completed tasks rather than conversational response time.
Running the GPU KV cache alone under that load, the server averaged 839.5 seconds at 256 users. Activating the CPU DRAM layer brought that down to 307.1 seconds (2.7x faster, 63% lower), and the NVMe layer to 348.3 seconds (2.4x faster).
At 512 users the order flips: DRAM degrades to 1,294 sec while NVMe holds at 717 sec, 2.4x faster than the 1,726 sec of GPU-only.
Round-to-round degradation
Averages understate the real story. The decisive evidence is in how TTFT changes from round 1 to round 25 as context accumulates.
| Metric (256 Users) | GPU Cache Only | + CPU DRAM | + NVMe |
|---|---|---|---|
| Average TTFT (sec) | 839.5 | 307.1 | 348.3 |
| P99 TTFT (sec) | 1,258.9 | 546.3 | 603.9 |
| Round 1 to Round 25 Change | +496% | +166% | +183% |
| External Cache Hit Rate | n/a | 75.5% | 76.2% |
Table 10 | Round-to-round TTFT by configuration at 256 concurrent users
Running its GPU cache alone, the server does not merely start behind. It deteriorates as the conversation grows, because once VRAM is full the engine evicts KV blocks and pays the full recomputation cost on the next turn. Activating a lower memory layer moves the effective cache limit beyond GPU memory and keeps the system generating tokens rather than recomputing context.
Throughput
Generation throughput moves in the same direction. With the GPU cache alone, the server peaked at 47 tokens per second. The CPU DRAM layer sustained 124.9 tokens per second, a 2.7x uplift, and the NVMe layer 111.1 tokens per second, a 2.4x uplift.
At 512 users, where DRAM falls to 59 tok/s, NVMe holds 106.3 tok/s, nearly matching its 256-user peak.
Energy and power efficiency
The layered configurations remove redundant recomputation, returning GPU cycles to useful token generation. Measured as tokens per joule, DRAM reached 0.090 and NVMe 0.089 against 0.033 for the GPU cache alone at 256 users, a 2.7x efficiency gain, equivalent to a 63% reduction in energy cost per token.
All energy figures are sourced from Intel RAPL package telemetry rather than estimated. The NVMe tier saves roughly 200 W of node power at high concurrency because the GPU draws less power when it is not stalled on redundant prefill.
Where the data path binds
At 256 users, combined PCIe transmit and receive traffic measured roughly 54.6 GB/s with the GPU cache alone, dominated by recomputation churn, against 33.3 GB/s with DRAM and 29.3 GB/s with NVMe. Activating offload reduces PCIe traffic by ~39% because cache hits eliminate full prefill cycles.
Retrieved KV blocks cross PCIe Gen5 at roughly 63 GB/s effective regardless of which layer holds them, so the binding ceiling for both layered configurations is PCIe transfer, not raw DDR5 or SSD bandwidth.
What This Means for Your Infrastructure
Deploy the full server, then activate every memory layer. The cheapest path to a low price per token on this platform is not a different server and not fewer GPUs. It is deploying the complete HPE ProLiant server and putting its whole memory hierarchy to work. At 256 users, activating the DRAM layer cut price per token 2.7x with the GPUs unchanged, and the NVMe layer carried that economics to organizational scale.
Treat the layered hierarchy as the default, not an add-on. Running the GPU KV cache alone degraded TTFT +496% from round 1 to round 25 at 256 users. A single memory layer is not a viable production configuration for sustained agentic load. For any multi-round, long-context workload above roughly 32 concurrent users, activate the DRAM and NVMe layers from the start.
Lead with the CPU DRAM layer for production concurrency. Across the measured matrix from 16 to 256 users, the CPU DRAM layer delivered the lowest TTFT, the highest throughput, and the best energy efficiency at the same time. The dual Intel Xeon 6787P sockets and 2,048 GB of DDR5 make this the practical default for production agentic serving.
Extend to the NVMe layer for capacity, persistence, and extreme scale. The NVMe layer becomes the decisive tier at 512 users, where DRAM saturates. It sustains a 75.5% cache hit rate, holds price per token at $13.34, completes the workload 2.4x faster than GPU-only, and consumes 9x less DRAM, while holding KV state within a 15 TB allocation on the 30.72 TB SSD array at the lowest cost per gigabyte. It is also the layer for KV cache that must persist across restarts or be shared across nodes.
Allocate by workload, not by habit. A light, low-concurrency task can run on the GPU layer alone. A production agent fleet should activate DRAM, and organization-scale, persistent, or 512-user workloads should add NVMe.
The Bottom Line
Agentic AI has changed what an inference benchmark must measure. The workloads that now drive enterprise spend are multi-round, long-context, high-reuse, and host-bound. Under that profile, the efficiency of the memory hierarchy, not raw GPU compute, sets the ceiling on how many agents a node can serve within SLA.
The benchmark quantifies that ceiling on the HPE ProLiant Compute DL380a Gen12 with real agentic traces, on the same fully configured server in every test. At the same hourly cost, activating the CPU DRAM layer cut the price of one million generated tokens from roughly $30.30 to $11.38 at 256 users, a 2.7x reduction, while also lowering TTFT 63% and improving energy efficiency 2.7x.
At 512 users, where DRAM saturates, the NVMe layer held that price at $13.34 per million tokens, 2.4x cheaper than GPU-only, while extending KV capacity to organizational scale.
Measured against a 300-second SLA, the same server serves 4x more agents at 4x lower cost per agent. The GPUs run throughout.
For infrastructure teams planning their next inference deployment, the question is not whether to buy GPUs. Every agent server needs them. It is how much of the GPU investment already in place is being spent recomputing context that the server's own DRAM and NVMe could serve in a fraction of the time, and at a fraction of the price per token.
Next steps
- Size your deployment against your own concurrency and SLA targets using these configurations and price-per-token figures.
- Engage your HPE and Intel account team to model the price per million tokens for your agent workload on the HPE ProLiant Compute DL380a Gen12.
- Validate the result on your traces by replaying a representative agentic workload across the GPU, CPU DRAM, and NVMe configurations on the same server.
Appendix: Test Platform Reference
| Field | Value |
|---|---|
| Server | HPE ProLiant Compute DL380a Gen12 |
| CPU | 2x Intel Xeon 6787P processors (dual-socket, 86 cores per socket) |
| DRAM | 2,048 GB DDR5 at 5600 MT/s (16x 128 GB RDIMM) |
| GPU | 4x NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs (96 GB VRAM, PCIe Gen5 x16) |
| NVMe (data) | 2x KIOXIA 15.36 TB PCIe NVMe SSDs, RAID-0, 30.72 TB usable |
| Model | Qwen3-235B-A22B-FP8 (sparse MoE, 22B active / 235B total, TP4) |
| Workload | sammshen/lmcache-agentic-traces (SWE-bench Verified, GAIA, WildClawBench) |
| Software | vLLM 0.22.0, LMCache 0.4.6, CUDA 13.3, Ubuntu 24.04.3 LTS |
Table 11 | Test platform reference
Glossary
| Term | Definition |
|---|---|
| KV Cache | The key-value attention state a model builds from context, reused across turns so it is not recomputed for every new token. |
| Prefill | The compute-bound stage that processes the input context and produces its KV cache before any output token is generated. |
| Decode | The memory-bandwidth-bound stage that generates output one token at a time, reusing the stored KV cache. |
| TTFT | Time to First Token. The delay before a response begins, which an agent waits on at the start of every round. |
| Tokenomics | The price to produce a given volume of model output, expressed here as cost per million tokens. |
| MoE | Mixture of Experts. A model design that activates a subset of parameters per token, here 22B of 235B. |
Run Configuration
| Parameter | Value |
|---|---|
| Model Configuration | |
| Model | Qwen3-235B-A22B-FP8 (sparse MoE, 22B active / 235B total) |
| Tensor Parallelism | TP=4 across 4 GPUs |
| KV Cache Data Type | FP8 |
| Context Length | 40,192 tokens (sliding-window safe) |
| GPU Memory Utilization | 0.80 |
| GPU KV Cache Budget | ~149-157 GB (measured at launch) |
| vLLM Launch Config | |
| Max Sequences | 40,960 |
| Max Batched Tokens | 40,960 |
| Block Size | 16 tokens |
| Prefix Caching | Enabled (radix cache, all tiers) |
| Chunked Prefill | Enabled |
| LMCache Config - CPU DRAM Layer | |
| Chunk Size | 256 tokens |
| Local CPU | Enabled |
| Max DRAM per TP Worker | 256 GB x 4 workers = 1,024 GB total |
| Lazy Memory Allocator | Enabled |
| LMCache Config - NVMe SSD Layer | |
| Chunk Size | 256 tokens |
| DRAM Buffer per TP Worker | 16 GB x 4 workers = 64 GB total |
| NVMe Mount Path | /mnt/md0/kvcache/ |
| Max NVMe Allocation | 15,000 GB (15 TB) |
| O_DIRECT | Enabled |
| Async I/O | Enabled |
| Experimental I/O Path | Enabled |
References
- Raj, Wang, and Krishna. Towards Understanding, Analyzing, and Optimizing Agentic AI Execution: A CPU-Centric Perspective. arXiv:2511.00739, 2025.
- Intel. Intel Xeon 6 Agentic AI Platform Briefing. June 2026.
- Metrum AI, HPE, and Intel. KV Cache Offload Benchmark, full-grid run, Qwen3-235B-A22B-FP8. full-grid-sliding-safe-20260604T153951Z, June 2026.
Testing performed by Metrum AI in collaboration with HPE and Intel. All performance figures represent observed measurements under the described test conditions on a single HPE ProLiant Compute DL380a Gen12 configuration. Results vary by model, hardware configuration, software version, and deployment workload, and should not be interpreted as guarantees of performance on different systems. The relative comparisons between memory configurations are the transferable result. Cost figures are estimates based on stated assumptions and prevailing market pricing; confirm current procurement pricing before relying on them. NVIDIA and RTX are trademarks of NVIDIA Corporation. Intel and Xeon are trademarks of Intel Corporation. HPE and ProLiant are trademarks of Hewlett Packard Enterprise. KIOXIA is a trademark of KIOXIA Corporation.